
一文簡單理解“推薦系統”原理及架構
本文主要介紹什麼是推薦系統,為什麼需要推薦系統,如何實現推薦系統的方案,包括實現推薦系統的一些常見模型,希望給讀者提供學習實踐參考。
為什麼需要推薦系統

對於資訊消費者,需要從大量資訊中找到自己感興趣的資訊,而在資訊過載時代,使用者難以從大量資訊中獲取自己感興趣、或者對自己有價值的資訊。
對於資訊生產者,需要讓自己生產的資訊脫穎而出,受到廣大使用者的關注。從物品的角度出發,推薦系統可以更好地發掘物品的長尾(long tail)。

長尾效應是美國《連線》雜誌主編 Chris Anderson 在 2006 年出版的《長尾理論》一書中指出,傳統的 80/20 原則(80% 的銷售額來自於 20% 的熱門品牌)在網際網路的加入下會受到挑戰。網際網路條件下,由於貨架成本極端低廉,電子商務網站往往能出售比傳統零售店更多的商品。這些原來不受到重視的銷量小但種類多的產品或服務由於總量巨大,累積起來的總收益超過主流產品的現象。
主流商品往往代表了絕大多數使用者的需求,而長尾商品往往代表了一小部分使用者的個性化需求。
推薦系統通過發掘使用者的行為,找到使用者的個性化需求,從而將長尾商品準確地推薦給需要它的使用者,幫助使用者發現那些他們感興趣但很難發現的商品。
推薦系統的任務在於:
- 一方面幫助使用者發現對自己有價值的資訊。
- 另一方面讓資訊能夠展現在對它感興趣的使用者面前,從而實現資訊消費者和資訊生產者的雙贏。
推薦系統的本質
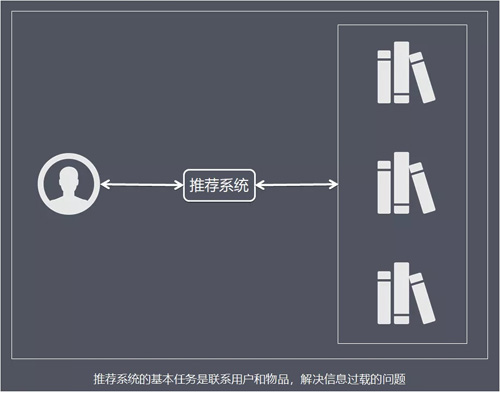
通過一定的方式將使用者和物品聯絡起來,而不同的推薦系統利用了不同的方式。
推薦系統就是自動聯絡使用者和物品的一種工具,它能夠在資訊過載的環境中幫助使用者發現令他們感興趣的資訊,也能將資訊推送給對它們感興趣的使用者。
評價指標
從產品的角度出發,評價一個推薦系統可以從以下維度出發:
- 使用者滿意度:使用者作為推薦系統的重要參與者,其滿意度是評測推薦系統的最重要指標。但是,使用者滿意度沒有辦法離線計算,只能通過使用者調查或者線上實驗獲得。
- 預測準確度:預測準確度度量一個推薦系統或者推薦演算法預測使用者行為的能力。這個指標是最重要的推薦系統離線評測指標,從推薦系統誕生的那一天起,幾乎 99% 與推薦相關的論文都在討論這個指標。
在計算該指標時需要有一個離線的資料集,該資料集包含使用者的歷史行為記錄。然後,將該資料集通過時間分成訓練集和測試集。
最後,通過在訓練集上建立使用者的行為和興趣模型預測使用者在測試集上的行為,並計算預測行為和測試集上實際行為的重合度作為預測準確度。
- 覆蓋率:覆蓋率( coverage )描述一個推薦系統對物品長尾的發掘能力。覆蓋率有不同的定義方法,最簡單的定義為推薦系統能夠推薦出來的物品佔總物品集合的比例。
- 多樣性:使用者的興趣是廣泛的,為了滿足使用者廣泛的興趣,推薦列表需要能夠覆蓋使用者不同的興趣領域,即推薦結果需要具有多樣性。
- 新穎性:新穎的推薦是指給使用者推薦那些他們以前沒有聽說過的物品。在一個網站中實現新穎性的最簡單辦法是,把那些使用者之前在網站中對其有過行為的物品從推薦列表中過濾掉。
- 驚喜度:與新穎性不同,如果推薦結果和使用者的歷史興趣不相似,但卻讓使用者覺得滿意,那麼就可以說推薦結果的驚喜度很高,而推薦的新穎性僅僅取決於使用者是否聽說過這個推薦結果。
- 信任度:對於基於機器學習的自動推薦系統,同樣存在信任度( trust )的問題,如果使用者信任推薦系統,那就會增加使用者和推薦系統的互動。
同樣的推薦結果,以讓使用者信任的方式推薦給使用者就更能讓使用者產生購買慾,而以類似廣告形式的方法推薦給使用者就可能很難讓使用者產生購買的意願。
度量推薦系統的信任度只能通過問卷調查的方式,詢問使用者是否信任推薦系統的推薦結果。
- 實時性:推薦系統需要實時地更新推薦列表來滿足使用者新的行為變化,推薦系統需要能夠將新加入系統的物品推薦給使用者。這主要考驗了推薦系統處理物品冷啟動的能力。
- 健壯性:任何一個能帶來利益的算法系統都會被人攻擊,這方面最典型的例子就是搜尋引擎。
搜尋引擎的作弊和反作弊鬥爭異常激烈,而健壯性(即 robust,魯棒性)指標衡量了一個推薦系統抗擊作弊的能力。
基於使用者行為推薦
使用者行為
使用者行為可以分為顯性反饋行為(explicit feedback)和隱性反饋行為(implicit feedback)。
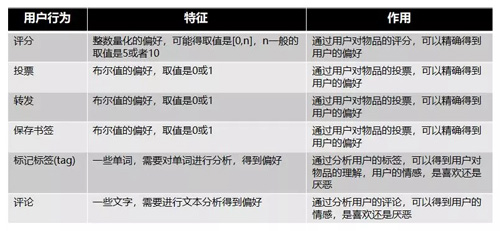
顯性反饋行為:指使用者明確表示對物品喜好的行為,主要方式就是評分和喜歡/不喜歡。
常見的顯性反饋行為可以參考如下表格:
隱性反饋行為(implicit feedback):指的是那些不能明確反應使用者喜好的行為。最具代表性的隱性反饋行為就是頁面瀏覽行為。
使用者瀏覽一個物品的頁面並不代表使用者一定喜歡這個頁面展示的物品,比如可能因為這個頁面連結顯示在首頁,使用者更容易點選它而已。
相比顯性反饋,隱性反饋雖然不明確,但資料量更大。在很多網站中,很多使用者甚至只有隱性反饋資料,而沒有顯性反饋資料。
基於使用者行為資料設計的推薦演算法一般稱為協同過濾演算法。學術界對協同過濾演算法進行了深入研究,提出了很多方法。
比如基於鄰域的演算法(neighborhood-based)、隱語義模型(latent factor model)、基於圖的隨機遊走演算法(random walk on graph)等。
下面主要展開介紹基於領域的演算法和隱語義模型演算法。
基於領域的演算法
基於鄰域的方法是最著名的、在業界得到最廣泛應用的推薦演算法,主要包含下面兩種演算法:
- 基於使用者的協同過濾演算法(UserCF)。
- 基於物品的協同過濾演算法(ItemCF)。
演算法涉及的基本步驟如下:
- 收集使用者偏好,把使用者對物品的偏好轉換成可量化的綜合評分值。
- 找到相似的使用者或物品。
- 計算推薦。
相似度計算
計算相似度主要有以下 3 種計算方式:
①歐氏距離(Euclidean Distance)
向量歐式距離:
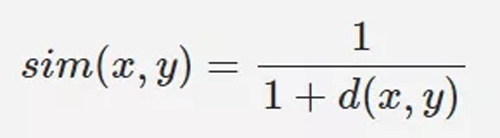
②皮爾遜相關係數(Pearson Correlation Coefficient)
協方差,用來衡量 2 個向量的變化趨勢是否一致:
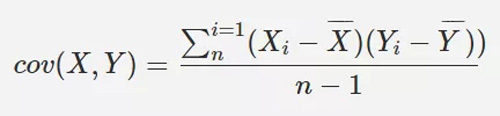
標準差:
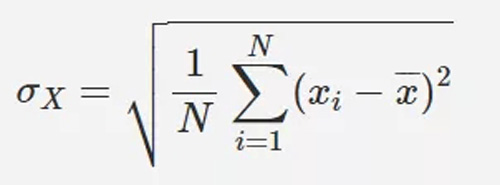
皮爾遜相關係數:
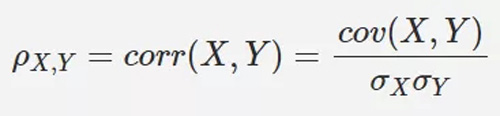
皮爾遜相關係數使用協方差除以 2 個向量的標準差得到,值的範圍[-1,1]。
③Cosine 相似度(Cosine Similarity,餘弦距離)
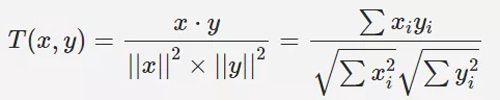
Cosine 相似度其實就是求 2 個向量的夾角。3 種計算相關係數的演算法中,皮爾遜相關係數在生產中最為常用。
鄰居的選擇

通過相似度計算出若干個最相似的鄰居後,如何選擇鄰居?主要有以下方式:
- 基於固定數量的鄰居:該方式直接選擇固定數量的鄰居,有可能把相似度較小的物件也引入。
- 基於相似度門檻的鄰居:該方式先用相似度門檻篩選出鄰居的一個集合,再從集合裡面挑選出相似度較大的鄰居。可以避免把相似度較小的物件引入,效果更好。
基於使用者的協同過濾演算法(UserCF)
簡單而言,就是給使用者推薦和他興趣相似的其他使用者喜歡的物品。
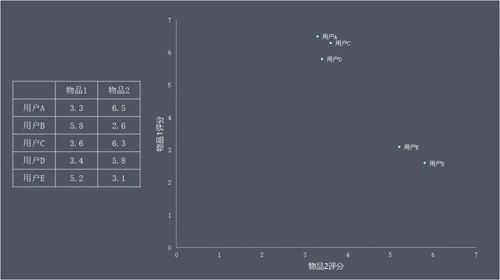
在一個線上個性化推薦系統中,當一個使用者 A 需要個性化推薦時,可以先找到和他有相似興趣的其他使用者,然後把那些使用者喜歡的、而使用者 A 沒有聽說過的物品推薦給 A 。這種方法稱為基於使用者的協同過濾演算法。

使用者 A 與使用者 C 的興趣比較相似,使用者 C 喜歡了物品 4,所以給使用者 A 推薦物品 4。
數學實現如下圖:
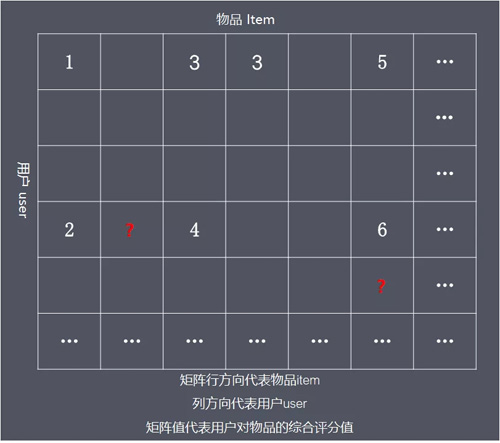
已知使用者評分矩陣 Matrix R(一般都是非常稀疏的),推斷矩陣中問號處的評分值。
UserCF 模型存在問題:
- 對於一個新使用者,很難找到鄰居使用者。
- 對於一個新物品,所有最近的鄰居都在其上沒有多少打分。
基礎解決方案:
- 相似度計算最好使用皮爾遜相似度。
- 計算使用者相似度考慮共同打分物品的數目。
比如乘上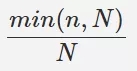 ,n 為共同打分的商品數,N 為指定閾值,這樣可以讓 2 個使用者的共同打分的商品數越少,相似度越小。
,n 為共同打分的商品數,N 為指定閾值,這樣可以讓 2 個使用者的共同打分的商品數越少,相似度越小。
- 對打分進行歸一化處理,比如把原來分數值範圍是[0,10],歸一化後變成[0,1]。
- 設定一個相似度閾值。
基於使用者的協同過濾不流行的原因:
資料稀疏問題,資料存取困難。
數百萬使用者計算,使用者之間兩兩計算相似度,計算量過大。
人是善變的。
基於物品的協同過濾演算法(ItemCF)
基於物品的協同過濾演算法(簡稱 ItemCF)就是給使用者推薦那些和他們之前喜歡的物品相似的物品。
比如,該演算法會因為你購買過《資料探勘導論》而給你推薦《機器學習》。
不過,ItemCF 演算法並不利用物品的內容屬性計算物品之間的相似度,它主要通過分析使用者的行為記錄計算物品之間的相似度。
該演算法認為,物品 A 和物品 B 具有很大的相似度是因為喜歡物品 A 的使用者大都也喜歡物品 B。

物品 1 和物品 3 都被使用者 A 和使用者 B 喜歡,所以認為是相似物品,所以當用戶 C 喜歡物品 1,就給使用者 C 推薦物品 3。
演算法主要步驟如下:
- 計算物品之間的相似度。
- 根據物品的相似度和使用者的歷史行為給使用者生成推薦列表。
數學實現思路如下圖:
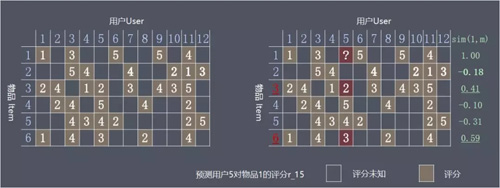
需要使用者 5 對物品 1 的評分 r_15,由於物品 3、物品 6 是與物品 1 最為相似的 2 個物品,取相似度作為權重,所以 r_15 可以預測如下:
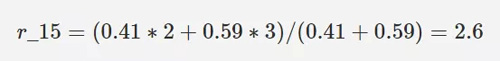
模型優勢:
- 計算效能高,通常使用者數量遠大於物品數量,實際計算物品之間的相似度,可以只選擇同一個大分類下的類似物品來計算,以此減少計算量。
- 可預先保留結果,物品並不善變。
UserCF 和 ItemCF 綜合比較
UserCF 給使用者推薦那些和他有共同興趣愛好的使用者喜歡的物品,而 ItemCF 給使用者推薦那些和他之前喜歡的物品類似的物品。
從這個演算法的原理可以看到:
- UserCF 的推薦結果著重於反映和使用者興趣相似的小群體的熱點。
- ItemCF 的推薦結果著重於維繫使用者的歷史興趣。

換句話說:
- UserCF 的推薦更社會化,反映了使用者所在的小型興趣群體中物品的熱門程度。
- ItemCF 的推薦更加個性化,反映了使用者自己的興趣傳承。
基於使用者標籤推薦
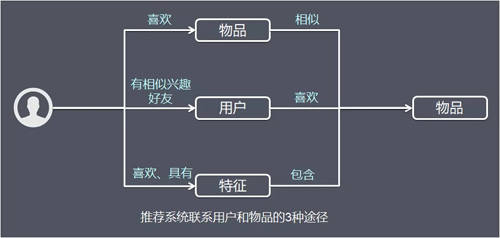
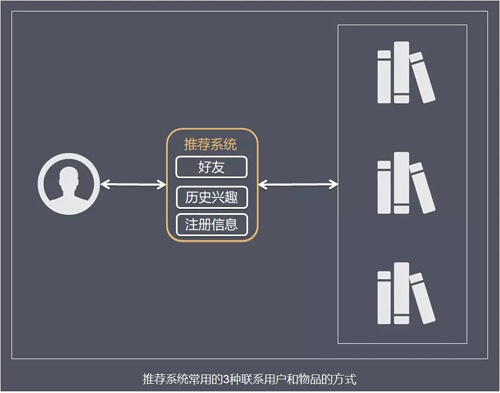
推薦系統的目的是聯絡使用者的興趣和物品,這種聯絡需要依賴不同的媒介。
目前流行的推薦系統基本上通過 3 種方式聯絡使用者興趣和物品:
- 基於使用者推薦 UserCF:利用和使用者興趣相似的其他使用者,給使用者推薦那些和他們興趣愛好相似的其他使用者喜歡的物品。
- 基於物品推薦 ItemCF:給使用者推薦與他喜歡過的物品相似的物品。
- 基於特徵:這裡的特徵有不同的表現方式,比如可以表現為物品的屬性集合(比如對於圖書,屬性集合包括作者、出版社、主題和關鍵詞等),也可以表現為隱語義向量(latent factor vector)。
標籤相關問題
標籤的定義
根據維基百科的定義,標籤是一種無層次化結構的、用來描述資訊的關鍵詞,它可以用來描述物品的語義。
根據給物品打標籤的人的不同,標籤應用一般分為兩種:
一種是讓作者或者專家給物品打標籤。
另一種是讓普通使用者給物品打標籤,也就是 UGC(User Generated Content,使用者生成的內容)的標籤應用 UGC 的標籤系統是一種表示使用者興趣和物品語義的重要方式。
當一個使用者對一個物品打上一個標籤,這個標籤一方面描述了使用者的興趣,另一方面則表示了物品的語義,從而將使用者和物品聯絡了起來。
因此下面主要討論 UGC 的標籤應用,研究使用者給物品打標籤的行為,探討如何通過分析這種行為給使用者進行個性化推薦。
使用者為什麼要打標籤
從產品的角度,我們需要理解使用者打標籤的行為,為什麼要打標籤,只有深入瞭解使用者的行為,我們才能基於這個行為設計出令他們滿意的個性化推薦系統。
使用者這個行為背後的原因主要可以從 2 個維度進行探討:
- 社會維度,有些使用者標註是給內容上傳者使用的(便於上傳者組織自己的資訊),而有些使用者標註是給廣大使用者使用的(便於幫助其他使用者找到資訊)。
- 功能維度,有些標註用於更好地組織內容,方便使用者將來的查詢,而另一些標註用於傳達某種資訊,比如照片的拍攝時間和地點等。
使用者打什麼樣的標籤
使用者常打的標籤如下:
- 表明物品是什麼。
- 表明物品的種類。
- 表明誰擁有物品,比如很多部落格的標籤中會包括部落格的作者等資訊。
- 表達使用者的觀點,比如使用者認為網頁很有趣,就會打上標籤 funny(有趣),認為很無聊,就會打上標籤 boring(無聊)。
- 使用者相關的標籤,比如 my favorite(我最喜歡的)、my comment(我的評論)等。
- 使用者的任務,比如 to read(即將閱讀)、 job search(找工作)等。
為什麼要給使用者推薦標籤
使用者瀏覽某個物品時,標籤系統非常希望使用者能夠給這個物品打上高質量的標籤,這樣才能促進標籤系統的良性迴圈。因此,很多標籤系統都設計了標籤推薦模組給使用者推薦標籤。
一般認為,給使用者推薦標籤有以下好處:
- 方便使用者輸入標籤,讓使用者從鍵盤輸入標籤無疑會增加使用者打標籤的難度,這樣很多使用者不願意給物品打標籤,因此我們需要一個輔助工具來減小使用者打標籤的難度,從而提高使用者打標籤的參與度。
- 提高標籤質量,同一個語義不同的使用者可能用不同的詞語來表示。這些同義詞會使標籤的詞表變得很龐大,而且會使計算相似度不太準確。
而使用推薦標籤時,我們可以對詞表進行選擇,首先保證詞表不出現太多的同義詞,同時保證出現的詞都是一些比較熱門的、有代表性的詞。
如何給使用者推薦標籤
使用者 u 給物品 i 打標籤時,我們有很多方法可以給使用者推薦和物品 i 相關的標籤。
比較簡單的方法有 4 種:
- 給使用者 u 推薦整個系統裡最熱門的標籤(這裡將這個演算法稱為 PopularTags),這個演算法太簡單了,甚至於不能稱為一種標籤推薦演算法。
- 給使用者 u 推薦物品 i 上最熱門的標籤(這裡將這個演算法稱為 ItemPopularTags)。
- 使用者 u 推薦他自己經常使用的標籤(這裡將這個演算法稱為 UserPopularTags)。
- 前面兩種的融合(這裡記為 HybridPopularTags),該方法通過一個係數將上面的推薦結果線性加權,然後生成最終的推薦結果。
一個最簡單的演算法
基本步驟如下:
- 統計每個使用者最常用的標籤。
- 對於每個標籤,統計被打過這個標籤次數最多的物品。
- 對於一個使用者,首先找到他常用的標籤,然後找到具有這些標籤的最熱門物品推薦給這個使用者。
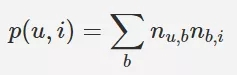
對於上面演算法,使用者 u 對於物品 i 的興趣公式如上:
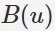 是使用者 u 打過的標籤集合。
是使用者 u 打過的標籤集合。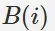 是物品 i 被打過標籤的集合。
是物品 i 被打過標籤的集合。 是使用者 u 打過標籤 b 的次數。
是使用者 u 打過標籤 b 的次數。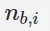 是物品 i 被打過標籤 b 的次數。
是物品 i 被打過標籤 b 的次數。
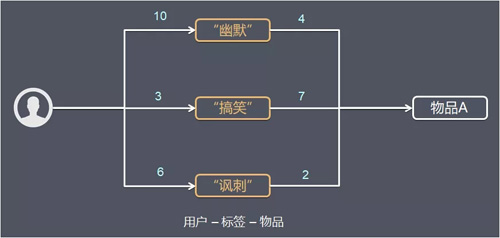
某使用者使用過“幽默”標籤 10 次,“搞笑”標籤 3 次,“諷刺”標籤 6 次。這 3 個標籤被物品 A 使用的次數分別的 4、7、2。
由此計算使用者對物品的興趣值為:

上面的計算公式會傾向於給熱門標籤對應的熱門物品很大的權重,因此會造成推薦熱門的物品給使用者,從而降低推薦結果的新穎性,還有資料稀疏性的問題,可以通過計算結果除以懲罰項來進行修正。
系統冷啟動問題
問題簡介
系統冷啟動(cold start)問題主要在於如何在一個新開發的網站上(還沒有使用者,也沒有使用者行為,只有一些物品的資訊)設計個性化推薦系統,從而在網站剛釋出時就讓使用者體驗到個性化推薦服務這一問題。
主要可以分為 3 類:
- 使用者冷啟動:使用者冷啟動問題主要在於如何給新使用者做個性化推薦。當新使用者到來時,我們沒有他的行為資料,所以也無法根據他的歷史行為預測其興趣,從而無法藉此給他做個性化推薦。
- 物品冷啟動:物品冷啟動問題主要在於如何解決將新的物品推薦給可能對它感興趣的使用者。
- 系統冷啟動:系統剛剛新上線,使用者、物品資料較少。
解決思路
針對上述 3 類冷啟動問題,一般來說,可以參考如下解決方案:
- 提供非個性化的推薦:非個性化推薦的最簡單例子就是熱門排行榜,我們可以給使用者推薦熱門排行榜,然後等到使用者資料收集到一定的時候,再切換為個性化推薦。這也是最常見的解決方案。
- 利用使用者註冊時提供的年齡、性別等資料做粗粒度的個性化。
- 要求使用者在首次登入時提供反饋,比如輸入感興趣的標籤,或感興趣的物品。收集使用者對物品的興趣資訊,然後給使用者推薦那些和這些物品相似的物品。
- 對於新加入的物品,可以利用內容資訊,將它們推薦給喜歡過和它們相似的物品的使用者。
- 在系統冷啟動時,可以引入專家的知識,通過一定的高效方式迅速建立起物品的相關度表。
評估指標
令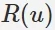 是根據使用者在訓練集上的行為給使用者作出的推薦列表,
是根據使用者在訓練集上的行為給使用者作出的推薦列表,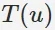 是使用者在測試集上的行為列表。
是使用者在測試集上的行為列表。
準確率
用於度量模型的預測值與真實值之間的誤差。
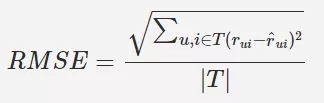
召回率
用於度量有多個正例被分為正例,這裡是正確推薦的數量佔測試集合上使用者行為列表的比例。
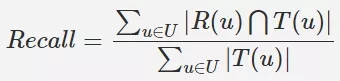
覆蓋率
使用者衡量推薦的物品佔全部商品的比例,一般我們推薦的物品希望儘可能覆蓋更多類別 。常見有 2 種計算方法:
通過推薦的商品佔總商品的比例:
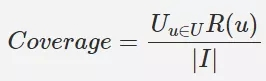
或者通過推薦物品的熵值得到覆蓋率,熵值越大,覆蓋率越大:

多樣性
用於衡量每次推薦裡面的推送的物品佔所有可能性的比率,多樣性越大,每次推薦的物品越豐富。

實際上,不同的平臺還有不同的衡量標準,例如使用者滿意度,廣告收益,需要結合實際業務情況做策略調整。
系統架構
基於特徵的推薦系統
再次回顧一下上面提到的推薦系統聯絡使用者和物品的 3 種途徑。
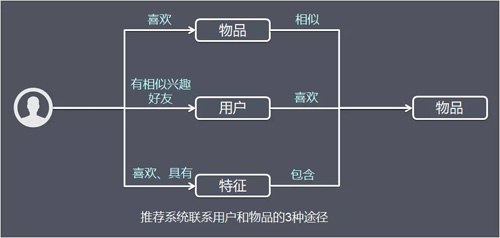
將這 3 種方式都抽象一下就可以發現,如果認為使用者喜歡的物品也是一種使用者特徵,或者和使用者興趣相似的其他使用者也是一種使用者特徵,那麼使用者就和物品通過特徵相聯絡。

使用者特徵種類特別多,主要包括以下幾類:
- 使用者註冊屬性:年齡、性別、國籍等。
- 使用者行為特徵:瀏覽、點贊、評論、購買等。
系統整體架構
由於推送策略本身的複雜性,如果要在一個系統中把上面提到的各種特徵和任務都統籌考慮,那麼系統將會非常複雜,而且很難通過配置檔案方便地配置不同特徵和任務的權重。
因此,推薦系統需要由多個推薦引擎組成,每個推薦引擎負責一類特徵和一種任務,而推薦系統的任務只是將推薦引擎的結果按照一定權重或者優先順序合併、排序然後返回。
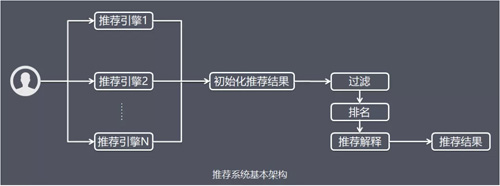
這樣做有 2 個好處:
- 可以方便地增加/刪除引擎,控制不同引擎對推薦結果的影響。對於絕大多數需求,只需要通過不同的引擎組合實現。
- 可以實現推薦引擎級別的使用者反饋。每一個推薦引擎其實代表了一種推薦策略,而不同的使用者可能喜歡不同的推薦策略:
有些使用者可能喜歡利用他的年齡性別作出的推薦。
有些使用者可能比較喜歡看到新加入的和他興趣相關的視訊。
有些使用者喜歡比較新穎的推薦。
有些使用者喜歡專注於一個鄰域的推薦。
有些使用者喜歡多樣的推薦。
我們可以將每一種策略都設計成一個推薦引擎,然後通過分析使用者對推薦結果的反饋瞭解使用者比較喜歡哪些引擎推薦出來的結果,從而對不同的使用者給出不同的引擎組合權重。
推薦引擎架構
推薦引擎使用一種或幾種使用者特徵,按照一種推薦策略生成一種型別物品的推薦列表,基本架構如下圖:

如上圖,推薦引擎架構主要包括 3 部分:
- 使用者行為資料模組:圖中 A 部分,該部分負責從資料庫或者快取中拿到使用者行為資料,通過分析不同行為,生成當前使用者的特徵向量。
不過如果是使用非行為特徵,就不需要使用行為提取和分析模組了。該模組的輸出是使用者特徵向量。
- 物品資料模組:圖中 B 部分,該部分負責將使用者的特徵向量通過特徵-物品相關矩陣轉化為初始推薦物品列表。
- 最終結果生成模組:圖中 C 部分,該部分負責對初始的推薦列表進行過濾、排名等處理,從而生成最終的推薦結果。
其中,有幾個模組需要特別介紹一下:
- 候選物品集合:特徵-物品相關推薦模組還可以接受一個候選物品集合。候選物品集合的目的是保證推薦結果只包含候選物品集合中的物品。它的應用場合一般是產品需求希望將某些型別的電視劇推薦給使用者。
比如有些產品要求給使用者推薦最近一週加入的新物品,那麼候選物品集合就包括最近一週新加的物品。
- 過濾模組:在得到初步的推薦列表後,還不能把這個列表展現給使用者,首先需要按照產品需求對結果進行過濾,過濾掉那些不符合要求的物品。
一般來說,過濾模組會過濾掉以下物品:
使用者已經產生過行為物品,因為推薦系統的目的是幫助使用者發現物品,因此沒必要給使用者推薦他已經知道的物品,這樣可以保證推薦結果的新穎性。
候選物品以外的物品,候選物品集合一般有兩個來源,一個是產品需求。比如在首頁可能要求將新加入的物品推薦給使用者,因此需要在過濾模組中過濾掉不滿足這一條件的物品。
另一個來源是使用者自己的選擇,比如使用者選擇了某一個價格區間,只希望看到這個價格區間內的物品,那麼過濾模組需要過濾掉不滿足使用者需求的物品。
某些質量很差的物品,為了提高使用者的體驗,推薦系統需要給使用者推薦質量好的物品,那麼對於一些絕大多數使用者評論都很差的物品,推薦系統需要過濾掉。這種過濾一般以使用者的歷史評分為依據,比如過濾掉平均分在 2 分以下的物品。
- 排名模組:經過過濾後的推薦結果直接展示給使用者一般也沒有問題,但如果對它們進行一些排名,則可以更好地提升使用者滿意度。實際進行排名時,可以基於新穎性、多樣性、使用者反饋進行排名優化。
總結
除了本文介紹的模型演算法,基於使用者行為推薦還有隱語義模型,基於圖的模型比較常見,還有的基於上下文、社交網路推薦。實際有一些常見的演算法庫可以實現推薦系統運算,包括 LibRec,Crab 等。
參考資料:
《推薦系統實踐》
一文讀懂推薦系統知識體系
https://cloud.tencent.com/developer/article/1070529
個性化推薦系統總結
https://www.jianshu.com/p/319e4933c5ba
推薦系統介紹
https://www.cnblogs.com/redbear/p/8594939.html
陳彩華(caison),從事服務端開發,善於系統設計、優化重構、線上問題排查工作,主要開發語言是 Java,微訊號:hua1881375。
【51CTO原創稿件,合作站點轉載請註明原文作者和出處為51CTO.com】