
ssm學習——Lucene建立索引
一:理論知識
1.非結構化資料查詢方法
1)順序掃描法
太慢,效率不高。
2)全文檢索法
對需要查詢的文件建立索引,再對其進行搜尋。其實說白了就是為了使其結構化。
2.索引建立和搜尋流程圖
1)流程圖
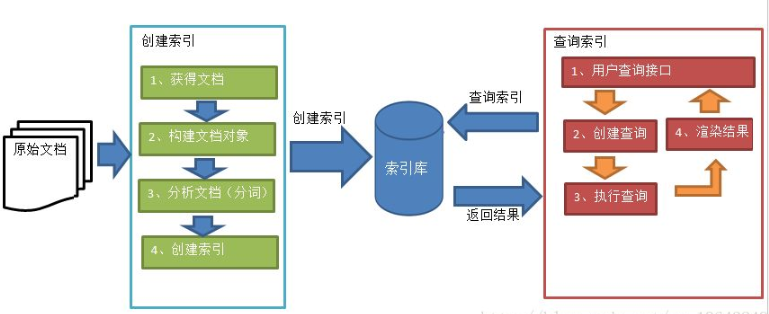
2)索引庫
索引庫是由兩部分組成的,一部分是索引,另一部分是文件物件(不是原始文件)。
3.流程圖詳解
1)建立文件物件
有以下規則
a.不同的文件可以有不同的Field
b.同一個文件可以有相同的Field
c.每一個文件有一個唯一的編號id
2)分析文件
分析的過程是經過對原始文件提取單詞,將字母轉換成小寫,去除標點符號等過程最終生成語彙單元(一個一個的單詞)。
注意:不同的域中生成的term是不同的term。
term好像是索引的基本單位,term包含文件域名和單詞內容。例如一個文件的檔名包含java是不同於內容中包含java的。這是通過term來實現的。
3)建立索引
為每一個term,指向所在的文件物件。Lucene是倒排索引,是先找到這個term再找到這個文件,這種方法比順序查詢效率高。
二:例項
1.準備工作
1)建立java工程
2)導包
lucene-core-4.10.3.jar
lucene-analyzer-common-4.10.3.jar
lucene-queryparser-4.10.3.jar
common-io-2.4.jar
2.實現步驟
1)實現步驟
1.建立一個IndexWriter物件
指定索引庫存放位置
指定一個分析器
2.建立document物件
3.建立field物件
4.使用IndexWriter物件進行索引建立
4.關閉IndexWriter物件
2)程式碼
3.Field的一些說明
1)Field域有幾大實現類,選擇依據:
是否分析:是否對域的內容進行分詞處理。是否要對域的內容進行查詢
是否索引:無論是否分析,但是索引要搜尋到。有一些不分析,但是也要進行索引。
是否儲存:將Field值儲存在文件物件中,凡是將來要從Document中獲取的Field都要儲存。
2)Field的子類

3)使用工具檢視建立的索引庫
Luke - Lucene Index Toolbox
注意事項:Lucene不提供資訊採集的類庫,需要其它庫支援。(Nutch,jsoup,heritrix)