
Python程序、執行緒、協程詳解、執行效能、效率(tqdm)
多程序實踐——multiprocessing
筆者最近在實踐多程序發現multiprocessing,真心很好用,不僅加速了運算,同時可以GPU呼叫,而且互相之間無關聯,這樣可以很放心的進行計算。
譬如(參考:多程序):
from multiprocessing import Pool import os, time, random def long_time_task(name): print 'Run task %s (%s)...' % (name, os.getpid()) start = time.time() time.sleep(random.random() * 3) end = time.time() print 'Task %s runs %0.2f seconds.' % (name, (end - start)) if __name__=='__main__': print 'Parent process %s.' % os.getpid() p = Pool() for i in range(5): p.apply_async(long_time_task, args=(i,)) print 'Waiting for all subprocesses done...' p.close() p.join() print 'All subprocesses done.'
先載入multiprocessing 模組Pool,
然後定義一個函式long_time_task;
建立一個程序池: p = Pool(),
for i in range(5):即為定義開一個程序,此處發現ubuntu裡面用spyder中的ipython,開多程序CPU時候,只能開到4個(可能預設開到4個記憶體佔滿了);
args是long_time_task函式的引數項,
一定要p.close()之後才能執行後續內容,
然後用p.join()呼叫join()之前必須先呼叫close(),呼叫close()之後就不能繼續新增新的Process了。
請注意輸出的結果,task 0,1,2,3是立刻執行的,而task 4要等待前面某個task完成後才執行,這是因為Pool的預設大小在我的電腦上是4,因此,最多同時執行4個程序。這是Pool有意設計的限制,並不是作業系統的限制。如果改成:
p = Pool(5)就可以同時跑5個程序。
由於Pool的預設大小是CPU的核數,如果你不幸擁有8核CPU,你要提交至少9個子程序才能看到上面的等待效果。
.
延伸一:Caffe Python介面多程序提取特徵
那麼在做影象處理的時候,進行預測任務的時候,可以開多程序,GPU方案。那麼步驟是:
- 1、分割資料;
- 2、多個程序池。
第一步:分割資料,用split_list函式:
def split_list(alist, wanted_parts=1):
length = len(alist)
return [ alist[i*length // wanted_parts: (i+1)*length // wanted_parts]
for i in range(wanted_parts) ]第二步:開多個程序池
可參考部落格:機器視覺:Caffe Python介面多程序提取特徵
.
多執行緒案例——threading
1、普通的threading
import threading
import time
def haha(max_num):
"""
隨便定義一個函式,要求使用者輸入一個要列印數字的最大範圍
輸入之後就會從0開始列印,直到使用者輸入的最大範圍
"""
for i in range(max_num):
"""
每次列印一個數字要間隔1秒,那麼列印10個數就要耗時10秒
"""
time.sleep(1)
print i
for x in range(3):
"""
這裡的rang(3)是要依次啟動三個執行緒,每個執行緒都呼叫函式haha()
第一個執行緒啟動執行之後,馬上啟動第二個執行緒再次執行。最後也相當
函式執行了3次
"""
#通過threading.Thread方法例項化多執行緒類
#target後面跟的是函式的名稱但是不要帶括號也不填寫引數
#args後面的內容才是要傳遞給函式haha()的引數。切記引數一定要以陣列的形式填寫不然會報錯。
t=threading.Thread(target=haha,args=(10,))
#將執行緒設定為守護執行緒
t.setDaemon(True)
#執行緒準備就緒,隨時等候cpu排程
t.start()其中setDaemon 這個引數是True,就表示程式流程跑完之後直接就關閉執行緒然後退出了,根本不管執行緒是否執行完。
.
2. join()
結果看起來規則一些可以考慮使用join()方法,參考:python 併發執行之多執行緒
join(timeout)方法將會等待直到執行緒結束。這將阻塞正在呼叫的執行緒,直到被呼叫join()方法的執行緒結束。
import threading
import time
def haha(max_num):
for i in range(max_num):
time.sleep(1)
print i
for x in range(3):
t=threading.Thread(target=haha,args=(5,))
t.start()
#通過join方法讓執行緒逐條執行
t.join()0
1
2
3
4
0
1
2
3
4
0
1
2
3
43. 多執行緒迴圈
背景:Python指令碼:讀取檔案中每行,放入列表中;迴圈讀取列表中的每個元素,並做處理操作。
核心:多執行緒處理單個for迴圈函式呼叫
#!/usr/bin/env python
#-*- coding: utf8 -*-
import sys
import time
import string
import threading
import datetime
fileinfo = sys.argv[1]
# 讀取檔案內容放入列表
host_list = []
port_list = []
# 定義函式:讀取檔案內容放入列表中
def CreateList():
f = file(fileinfo,'r')
for line in f.readlines():
host_list.append(line.split(' ')[0])
port_list.append(line.split(' ')[1])
return host_list
return port_list
f.close()
# 單執行緒 迴圈函式,註釋掉了
#def CreateInfo():
# for i in range(0,len(host_list)): # 單執行緒:直接迴圈列表
# time.sleep(1)
# TimeMark = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
# print "The Server's HostName is %-15s and Port is %-4d !!! [%s]" % (host_list[i],int(port_list[i]),TimeMark)
#
# 定義多執行緒迴圈呼叫函式
def MainRange(start,stop): #提供列表index起始位置引數
for i in range(start,stop):
time.sleep(1)
TimeMark = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print "The Server's HostName is %-15s and Port is %-4d !!! [%s]" % (host_list[i],int(port_list[i]),TimeMark)
# 執行函式,生成列表
CreateList()
# 列表分割成:兩部分 mid為列表的index中間位置
mid = int(len(host_list)/2)
# 多執行緒部分
threads = []
t1 = threading.Thread(target=MainRange,args=(0,mid))
threads.append(t1)
t2 = threading.Thread(target=MainRange,args=(mid,len(host_list)))
threads.append(t2)
for t in threads:
t.setDaemon(True)
t.start()
t.join()
print "ok" 也有一個分拆的步驟,args=(0,mid),args=(mid,len(host_list)
.
4.執行緒鎖與執行緒同步
當你有多個執行緒,就需要考慮怎樣避免執行緒衝突。解決辦法就是使用執行緒鎖。鎖由 Python 的 threading 模組提供,並且它最多被一個執行緒所持有。當一個執行緒試圖獲取一個已經鎖在資源上的鎖時,該執行緒通常會暫停執行,直到這個鎖被釋放。
讓我們給這個函式新增鎖。有兩種方法可以實現。第一種方式是使用 try/finally ,從而確保鎖肯定會被釋放。下面是示例:
import threading
total = 0
lock = threading.Lock()
def update_total(amount):
"""
Updates the total by the given amount
"""
global total
lock.acquire()
try:
total += amount
finally:
lock.release()
print (total)
if __name__ == '__main__':
for i in range(10):
my_thread = threading.Thread(
target=update_total, args=(5,))
my_thread.start()由 with 語句作為替代。
import threading
total = 0
lock = threading.Lock()
def do_something():
lock.acquire()
try:
print('Lock acquired in the do_something function')
finally:
lock.release()
print('Lock released in the do_something function')
return "Done doing something"
def do_something_else():
lock.acquire()
try:
print('Lock acquired in the do_something_else function')
finally:
lock.release()
print('Lock released in the do_something_else function')
return "Finished something else"
if __name__ == '__main__':
result_one = do_something()
result_two = do_something_else()可重入鎖
為了支援在同一執行緒中多次請求同一資源,python提供了可重入鎖(RLock)。RLock內部維護著一個Lock和一個counter變數,counter記錄了acquire的次數,從而使得資源可以被多次require。直到一個執行緒所有的acquire都被release,其他的執行緒才能獲得資源。
即把 lock = threading.lock() 替換為 lock = threading.RLock(),然後重新執行程式碼,現在程式碼就可以正常運行了。
參考文獻:
Python 多執行緒
一文學會 Python 多執行緒程式設計
.
python 效能除錯工具(line_profiler)
參考:python 效能除錯工具(line_profiler)使用
網上大部分都是說在所需要測的函式前面加一個@profile,如文件所說。但是加了@profile後函式無法直接執行,只能優化的時候加上,除錯的時候又得去掉。文章中提到了這個問題的解決辦法,個人覺得還是有點麻煩,不太能理解這是為什麼。我在stackoverflow上看到了另一種關於line_profile的使用方法,簡單而且實用。
from line_profiler import LineProfiler
import random
def do_stuff(numbers):
s = sum(numbers)
l = [numbers[i]/43 for i in range(len(numbers))]
m = ['hello'+str(numbers[i]) for i in range(len(numbers))]
numbers = [random.randint(1,100) for i in range(1000)]
lp = LineProfiler()
lp_wrapper = lp(do_stuff)
lp_wrapper(numbers)
lp.print_stats()輸出結果:
Timer unit: 1e-06 s
Total time: 0.000649 s
File: <ipython-input-2-2e060b054fea>
Function: do_stuff at line 4
Line # Hits Time Per Hit % Time Line Contents
==============================================================
4 def do_stuff(numbers):
5 1 10 10.0 1.5 s = sum(numbers)
6 1 186 186.0 28.7 l = [numbers[i]/43 for i in range(len(numbers))]
7 1 453 453.0 69.8 m = ['hello'+str(numbers[i]) for i in range(len(numbers))].
python通過tqdm 執行時間
安裝
pip install tqdm在迭代器for中使用:
from tqdm import tqdm
for i in tqdm(range(9)):
...同時也可以支援這樣的迭代方式:
[i for i in tqdm(range(9))]trange的方式:
>>> for i in trange(100):
... sleep(0.1)
100%|################################################################| 100/100 [00:10<00:00, 9.97it/s]
當迭代的內容為list:
>>> pbar = tqdm(["a", "b", "c", "d"])
>>> for char in pbar:
... pbar.set_description("Processing %s" % char)
Processing d: 100%|######################################################| 4/4 [00:06<00:00, 1.53s/it]
手動的控制更新
把執行的粒度放寬
>>> with tqdm(total=100) as pbar:
... for i in range(10):
... sleep(0.1)
... pbar.update(10)
100%|################################################################| 100/100 [00:01<00:00, 99.60it/s]
函式執行時間函式兩個小技巧:
# 第一種方式
%time [i+1 for i in range(100)]
# 第二種方式
%%time
[i+1 for i in range(100)]返回的結果都是:
CPU times: user 0 ns, sys: 0 ns, total: 0 ns
Wall time: 26.9 µs延伸二:Python 多程序實踐
參考:Python 多程序實踐
多程序的方式可以增加指令碼的併發處理能力, python 支援這種多程序的程式設計方式
在類unix系統中, python的os 模組內建了fork 函式用以建立子程序
1、fork 方式建立子程序
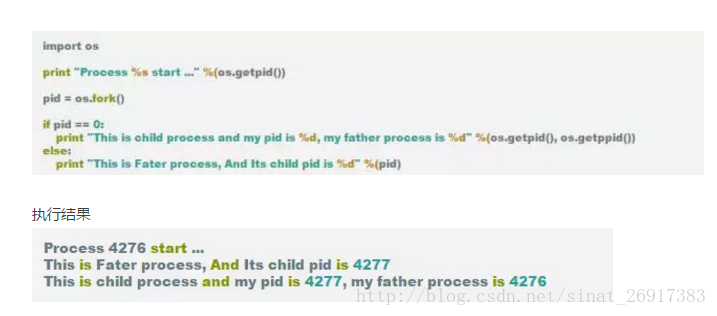
從結果可以看到, 從pid = os.fork() 開始, 下面的部分程式碼運行了兩次, 第一次是父程序執行, 第二次是子程序執行, 且子程序的fork的結果總是0, 所以這個也可以用來作為區分父程序或是子程序標誌
那麼變數在多個程序之間是否相互影響呢
import os

很明顯, 初始值為10的source 在父程序中值 減少了 1, 為9, 而子程序明顯source的初始值 是10, 也就是說多程序之間並沒有什麼相互影響