
二進位制與字元編碼
計算機能識別的只有1和0,也就是二進位制,而1和0可以表達出全世界的所有文字和語言符號。
我們人類採用的是十進位制算術法,主要原因是因為我們有10個手指頭。如果我們只有2個手指頭的話,我們就會用二進位制計數,就會逢二進一,那可能是這樣計數的:1,10,11,20,21,30,31,40。。。。。。其中1代表十進位制中的1,10代表10進制中的2,11代表十進位制中的3,20代表10進制中的4。。。。。。不過這樣太麻煩了,我們可以用純2進製表達,因為是逢二進一,所以除第一位外,每一位肯定是前一位的兩倍。 比如1在二進位制中還是用1表示;2在二進位制中用10表示,其中1是2的一次方;3在二進位制中用11表示;4用100表示,5用101表示。。。。。。從第一位開始的數字(1或0)乘以2的0次方,然後依次是乘以2的1次方,2次方,3次方直到無限大,得出的數就是十進位制。所以,雖然電腦只認識0和1,但是可以表達任何數字。
那如何表達文字和符號呢?這就涉及到字元編碼了,字元編碼強行將每一個字元對應一個十進位制數字,再將十進位制數字轉換成計算機理解的二進位制,而計算機讀到這些1和0之後就會顯示出對應的文字或符號。下面是ASCII(美國資訊交換標準程式碼)
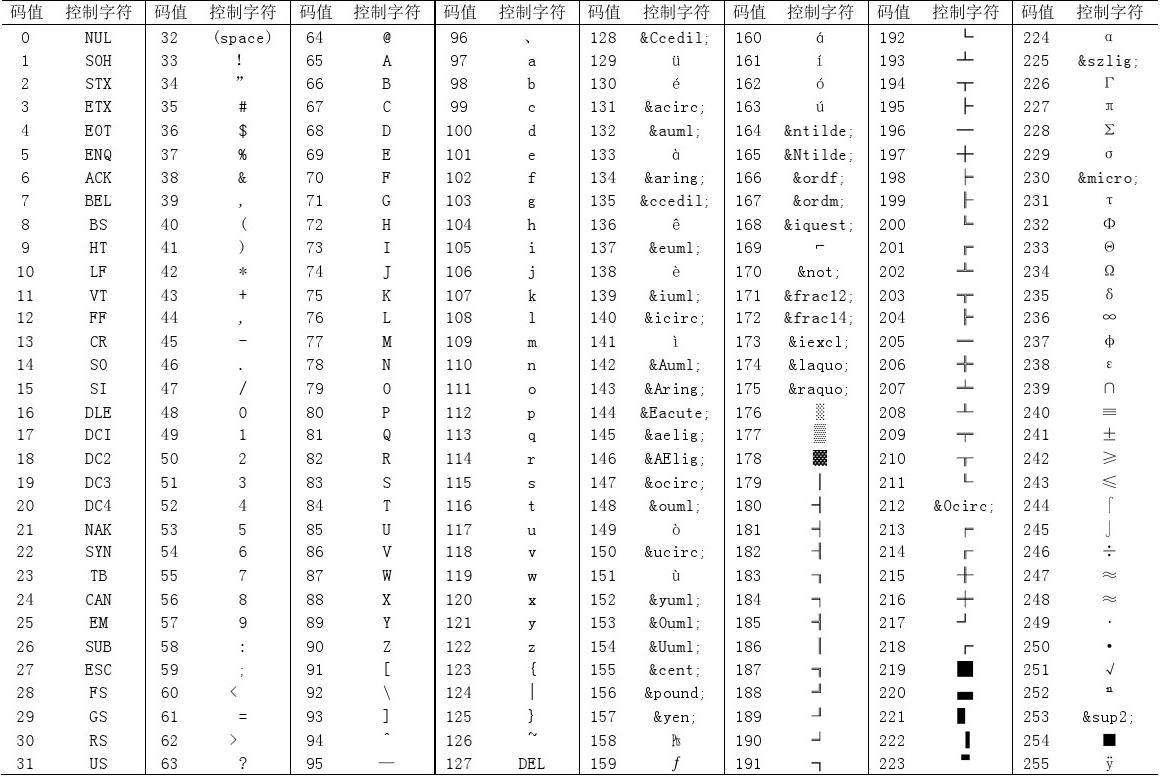
可以看到,255個就夠用了,因為美國是用字母的,那麼如何讓計算機去斷字呢?要知道,計算機讀的一堆二進位制數字是沒有空格的。解決辦法是用8個二進位制代表一個字母或符號,因為8個二進位制可以表達的最大數是255,正好用8個二進位制就能表示了,那乾脆所有的都用二進位制表示吧。
那你老美的編碼問題解決了,我們中國呢?中國文化博大精深,我們可以有上萬個漢字呢。於是我們於1980年推出了自己的GB2312編碼,支援常用的漢字。後來又相繼推出了 GBK1.0和 GB18030,簡單說後來推出的就是支援更多的漢字,而且支援少數民族文字和日韓裡面的所有漢字。其他國家也紛紛推出了自己國家的字元編碼。那麼問題來了,如果把一個國家出的軟體,裝到另一個國家的作業系統裡面,由於編碼不同,就會出現一些亂七八糟的東西,簡稱亂碼。
為了解決這個問題,ISO(國際標準化組織)於推出了Unicode,也就是萬國碼。在萬國碼中,每個字元用16個二進位制來表示。按理說,這個問題為完美解決了,但是老美不幹了,我們以前用8個二進位制就能表示的,你現在讓我們用16個二進位制來表示,那不是白白浪費空間嗎。為了安撫老美,utf-8誕生了。 UTF-8,是對Unicode編碼的壓縮和優化,簡單說就是對ASCII碼的內容用1位元組儲存,歐洲的字元用2個位元組儲存,東亞的字元用3個位元組儲存. 現在世界上使用最廣泛的編碼。不過這樣咱們吃虧了啊,咱們以前是用2個位元組的。
在作業系統方面windows中文版預設是用GBK編碼,Mac OX和linux是用utf-8
python2預設是用ASCII編碼,不過到了python3預設就用utf-8了。不過python2可以在程式碼的第一行加上如下宣告,這樣就會用utf-8去解碼了。
#! -*- coding: utf-8 -*- #!encoding :utf-8