
Pipeline inbound(netty原始碼7)
netty原始碼死磕7
Pipeline 入站流程詳解
1. Pipeline的入站流程
在講解入站處理流程前,先腦補和鋪墊一下兩個知識點:
(1)如何向Pipeline新增一個Handler節點
(2)Handler的出站和入站的區分方式
1.1. HandlerContext節點的新增
在Pipeline例項建立的同時,Netty為Pipeline建立了一個Head和一個Tail,並且建立好了連結關係。
程式碼如下:
protected DefaultChannelPipeline(Channel channel) {
this.channel = ObjectUtil.checkNotNull(channel, "channel");
tail = new TailContext(this);
head = new HeadContext(this);
head.next = tail;
tail.prev = head;
}
也就是說,在加入業務Handler之前,Pipeline的內部雙向連結串列不是一個空連結串列。而新加入的Handler,加入的位置是,插入在連結串列的倒數第二個位置,在Tail的前面。

加入Handler的程式碼,在DefaultChannelPipeline類中。
具體的程式碼如下:
@Override
public final ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler) {
final AbstractChannelHandlerContext newCtx;
synchronized (this) {
//檢查重複
checkMultiplicity(handler);
//建立上下文
newCtx = newContext(group, filterName(name, handler), handler);
//加入雙向連結串列
addLast0(newCtx);
//…
}
callHandlerAdded0(newCtx);
return this;
}
加入之前,首先進行Handler的重複性檢查。非共享型別的Handler,只能被新增一次。如果當前要新增的Handler是非共享的,並且已經新增過,那就丟擲異常,否則,標識該handler已經新增。
什麼是共享型別,什麼是非共享型別呢?先聚焦一下主題,後面會詳細解答。
檢查完成後,給Handler建立包裹上下文Context,然後將Context加入到雙向列表的尾部Tail前面。
程式碼如下:
private void addLast0(AbstractChannelHandlerContext newCtx) {
AbstractChannelHandlerContext prev = tail.prev;
newCtx.prev = prev;
newCtx.next = tail;
prev.next = newCtx;
tail.prev = newCtx;
}
這裡主要是通過調整雙向連結的指標,完成節點的插入。如果對雙向連結串列不熟悉,可以自己畫畫指向變化的草圖,就明白了。
1.2. Context的出站和入站的型別
對於入站和出站,Pipeline中兩種不同型別的Handler處理器,出站Handler和入站Handler。
入站(inBound)事件Handler的基類是 ChannelInboundHandler,出站(outBound)事件Handler的基類是 ChannelOutboundHandler。
處理入站(inBound)事件,最典型的就是處理Channel讀就緒事件,還有就是業務處理Handler。處理出站outBound操作,最為典型的處理,是寫資料到Channel。
對應於兩種Handler處理器的Context 包裹器,更加需要區分入站和出站。對Context的區分方式,又是什麼呢?
首先,需要在Context加了一組boolean型別判斷屬性,判斷出站和入站的型別。這組屬性就是——inbound、outbound。這組屬性,定義在上下文包裹器的基類中——ContextAbstractChannelHandlerContext 定義。它們在建構函式中進行初始化。
ContextAbstractChannelHandlerContext 的構造器程式碼如下:
abstract class AbstractChannelHandlerContext extends DefaultAttributeMap implements ChannelHandlerContext
{
private final boolean inbound;
private final boolean outbound;
AbstractChannelHandlerContext(DefaultChannelPipeline pipeline, EventExecutor executor, String name,
boolean inbound, boolean outbound) {
//….
this.pipeline = pipeline;
this.executor = executor;
this.inbound = inbound;
this.outbound = outbound;
//…
}
//…
}
對於通用的預設包裹器,繼承了ContextAbstractChannelHandlerContext 基類,並且在自己的構造器中,初始化這兩個父類屬性的方法,如下:
final class DefaultChannelHandlerContext extends AbstractChannelHandlerContext {
//…
private final ChannelHandler handler;
private static boolean isInbound(ChannelHandler handler) {
return handler instanceof ChannelInboundHandler;
}
private static boolean isOutbound(ChannelHandler handler) {
return handler instanceof ChannelOutboundHandler;
}
DefaultChannelHandlerContext(
DefaultChannelPipeline pipeline, EventExecutor executor, String name, ChannelHandler handler) {
super(pipeline, executor, name, isInbound(handler), isOutbound(handler));
//….
this.handler = handler;
}
}
從上面的程式碼可以看出, 通用的包裹器DefaultChannelHandlerContext ,通過自己的isInbound()、isOutbound()方法的返回值,對建構函式引數中的Handler 型別進行判斷,來設定分類的boolean型別屬性inbound、outbound的值。
再看兩個非通用的HandlerContext——head和tail。
在HeadContext,則呼叫父類構造器的第五個引數(outbound)的值為true,表示Head是一個出站型別的Context。程式碼如下:
final class HeadContext extends AbstractChannelHandlerContext
implements ChannelOutboundHandler, ChannelInboundHandler {
private final Unsafe unsafe;
HeadContext(DefaultChannelPipeline pipeline) {
//父類構造器
super(pipeline, null, HEAD_NAME, false, true);
//...
}
}
在TailContext,則呼叫父類構造器的第四個引數(inbound)的值為true,表示Tail是一個入站型別的Context。程式碼如下:
final class TailContext extends AbstractChannelHandlerContext implements ChannelInboundHandler {
TailContext(DefaultChannelPipeline pipeline) {
super(pipeline, null, TAIL_NAME, true, false);
//...
}
}
無論是哪種型別的handler,Pipeline沒有單獨和分開的入站和出站連結串列,都是統一在一個雙向連結串列中進行管理。
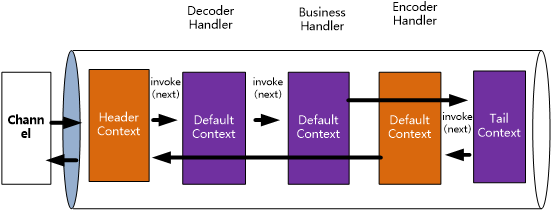
下圖中,使用紫色代表入站Context,橙色代表出站Context。

在上圖中,橙色表示出站Context,紫色表示入站Context。
在上圖中的流程中,區分一個 ChannelHandlerContext到底是in(入站)還是out(出站) ,使用的是Context的isInbound() 和 isOutbound() 這一組方法。
贅述一下:
Tail是出站執行流程的啟動點,但是,它最後一個入站處理器。
Hearder,是入站流程的啟動起點,但是,它最後一個出站處理器。
感覺,有點兒饒。容易讓人混淆。看完整個的入站流程和出站流程的詳細介紹,就清楚了。
1.3. 入站操作的全流程
入站事件前面已經講過,流向是從Java 底層IO到ChannelHandler。入站事件的型別包括連線建立和斷開、讀就緒、寫就緒等。
基本上,,在處理流程上,大部分的入站事件的處理過程,是一致的。
通用的入站Inbound事件處理過程,大致如下(使用IN_EVT符號代替一個通用事件):
(1)pipeline.fireIN_EVT
(2)AbstractChannelHandlerContext.invokeIN_EVT(head, msg);
(3)context.invokeIN_EVT(msg);
(4)handler.IN_EVT
(5)context.fireIN_EVT(msg);
(6)Connect.findContextInbound()
(7)context.invokeIN_EVT(msg);
上面的流程,如果短時間內看不懂,沒有關係。可以先看一個例子,再回來推敲學習這個通用流程。
1.4. 讀就緒事件的流程例項
下面以最為常見和最好理解的事件——讀就緒的事件為例,將Inbound事件做一個詳細的描述。
整個讀就緒的入站處理流程圖,如下:

1.5. 入站源頭的Java底層 NIO封裝
入站事件處理的源頭,在Channel的底層Java NIO 就緒事件。
Netty對底層Java NIO的操作類,進行了封裝,封裝成了Unsafe系列的類。比方說,AbstractNioByteChannel 中,就有一個NioByteUnsafe 類,封裝了底層的Java NIO的底層Byte位元組的讀取操作。
為什麼叫Unsafe呢?
很簡單,就是在外部使用,是不安全的。Unsafe就是隻能在Channel內部使用的,在Netty 外部的應用開發中,不建議使用。Unsafe包裝了底層的資料讀取工作,包裝在Channel中,不需要應用程式關心。應用程式只需要從快取中,取出快取資料,完成業務處理即可。
Channel 讀取資料到快取後,下一步就是呼叫Pipeline的fireChannelRead()方法,從這個點開始,正式開始了Handler的入站處理流程。
從Channel 到Pipeline這一段,Netty的程式碼如下:
public abstract class AbstractNioByteChannel extends AbstractNioChannel
{
protected class NioByteUnsafe extends AbstractNioUnsafe {
@Override
public final void read() {
final ChannelPipeline pipeline = pipeline();
……
// 讀取結果.
byteBuf = allocHandle.allocate(allocator);
……
int localReadAmount = doReadBytes(byteBuf);
………
// 通過pipeline dispatch(分發)結果到Handler
pipeline.fireChannelRead(byteBuf);
……
}
//通過重寫newUnsafe() 方法
//取得內部類NioSocketChannelUnsafe的例項
@Override
protected AbstractNioUnsafe newUnsafe() {
return new NioSocketChannelUnsafe();
}
…
}
channel呼叫了 pipeline.fireChannelRead(byteBuf)後,進入pipeline 開始處理。這是流程的真正啟動的動作。
1.6. Head是入站流程的起點
前面分析到,Pipeline中,入站事件處理流程的處理到的第一個Context是Head。
這一點,從DefaultChannelPipeline 原始碼可以得到驗證,如下所示:
public class DefaultChannelPipeline implements ChannelPipeline
{
…
@Override
public final ChannelPipeline fireChannelRead(Object msg) {
AbstractChannelHandlerContext.invokeChannelRead(head, msg);
return this;
}
…
}
Pipeline將內部連結串列的head頭作為引數,傳入了invokeChannelRead的靜態方法中。
就像開動了流水線的開關,開啟了整個的流水線的迴圈處理。
1.7. 小迭代的五個動作
一個Pipeline上有多個InBound Handler,每一個InBound Handler的處理,可以算做一次迭代,也可以說成小迭代。
每一個迭代,有四個動作。這個invokeIN_EVT方法,是整個四個動作的小迭代的起點。
四個動作,分別如下:
(1)invokeChannelRead(next, msg)
(2)context.invokeIN_EVT(msg);
(3)handler.IN_EVT
(4)context.fireIN_EVT(msg);
(5)Connect.findContextInbound()
區域性的流程圖如下:

整個五個動作中,只有第三步在Handler中,其他的四步都在Context中完成。
1.8. 流水線小迭代的第一步
invokeChannelRead(next,msg) 靜態方法,非常關鍵,其重要作為是:作為流水線迭代處理的每一輪迴圈小迭代的第一步。在Context的抽象基類中,原始碼如下:
abstract class AbstractChannelHandlerContext extends DefaultAttributeMap implements ChannelHandlerContext
{
//...
static void invokeChannelRead(final AbstractChannelHandlerContext next, final Object msg) {
……
next.invokeChannelRead(msg);
……
}
//...
}
首先,這個是一個靜態方法。
其次,這個方法沒有啥特別。只是做了一個二轉。將處理傳遞給context例項,呼叫context例項的invokeChannelRead方法。強調一下,使用了同一個名稱哈。但是後邊的invokeChannelRead,是一個例項方法,而且只有一個引數。
1.9. context.invokeIN_EVT例項方法
流水線小迭代第二步,觸發當前的Context例項的IN_EVT操作。
對於IN_EVT為ChannelRead的時候,第二步方法為invokeChannelRead,其原始碼如下:
abstract class AbstractChannelHandlerContext extends DefaultAttributeMap implements ChannelHandlerContext
{
private void invokeChannelRead(Object msg) {
……
((ChannelInboundHandler) handler()).channelRead(this, msg);
……
}
}
這一步很簡單,就是將context和msg(byteBuf)作為引數,傳遞給Handler例項,完成業務處理。
在Handler中,可以獲取到以上兩個引數例項,作為業務處理的輸入。在業務Handler中的IN_EVT方法中,可以寫自己的業務處理邏輯。
1.10. 預設的handler.IN_EVT 入站處理操作
流水線小迭代第三步,完後Context例項中Handler的IN_EVT業務操作。
如果Handler中的IN_EVT方法中沒有寫業務邏輯,則Netty提供了預設的實現。預設原始碼在ChannelInboundHandlerAdapter 介面卡類中。
當IN_EVT為ChannelRead的時候,第三步的預設實現原始碼如下:
public class ChannelInboundHandlerAdapter extends ChannelHandlerAdapter implements ChannelInboundHandler
{
//預設的通道讀操作
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ctx.fireChannelRead(msg);
}
//...
}
讀完原始碼發現,這份預設原始碼,都沒有做什麼實際的處理。
唯一的乾的活,就是呼叫ctx.fireChannelRead(msg),將msg通過context再一次發射出去。
進入第四步。
1.11. context.fireIN_EVT再發射訊息
流水線小迭代第四步,尋找下家,觸發下一家的入站處理。
整個是流水線的流動的關鍵一步,實現了向下一個HandlerContext的流動。
原始碼如下:
abstract class AbstractChannelHandlerContext extends DefaultAttributeMap implements ChannelHandlerContext
{
private final boolean inbound;
private final boolean outbound;
//...
@Override
public ChannelHandlerContext fireChannelRead(final Object msg) {
invokeChannelRead(findContextInbound(), msg);
return this;
}
//..
}
第四步還是在ChannelInboundHandlerAdapter 介面卡中定義。首先通過第五步,找到下一個Context,然後回到小迭代的第一步,完成了小迭代的一個閉環。
這一步,對於業務Handler而言,很重要。
在使用者Handler中,如果當前 Handler 需要將此事件繼續傳播下去,則呼叫contxt.fireIN_EVT方法。如果不這樣做, 那麼此事件的流水線傳播會提前終止。
1.12. findContextInbound()找下家
第五步是查詢下家。
程式碼如下:
public class ChannelInboundHandlerAdapter extends ChannelHandlerAdapter implements ChannelInboundHandler
{
//...
private AbstractChannelHandlerContext findContextInbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.next;
} while (!ctx.inbound);
return ctx;
}
}
這個是一個標準的連結串列查詢操作。this表示當前的context,this.next表示下一個context。通過while迴圈,一直往流水線的下邊找,知道查詢到下一個入站Context為止。
假定流水下如下圖所示:

{kind=link}
{kind=link}
{kind=link}
在上圖中,如果當前context是head,則下一個是Decoder;如果當前context是Decoder,則下一個是Business;如果當前context是Business,則下一個是Tail。
第五步,是在第四步呼叫的。
找到之後,第四步通過 invokeChannelRead(findContextInbound(), msg)這個靜態方法的呼叫,由回到小迭代的第一步,開始下一輪小的執行。
1.13. 最後一輪Context處理
我們在前面講到,在Netty中,Tail是最後一個IN boundContext。
final class TailContext extends AbstractChannelHandlerContext implements ChannelInboundHandler {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
onUnhandledInboundMessage(msg);
}
protected void onUnhandledInboundMessage(Object msg) {
//…
//釋放msg的引用計數
ReferenceCountUtil.release(msg);
//..
}
}
在最後的一輪入站處理中。Tail沒有做任何的業務邏輯,僅僅是對msg 釋放一次引用計數。
這個msg ,是從channel 入站源頭的過來的byteBuf。有可能是引用計數型別(ReferenceCounted)型別的快取,則需要釋放其引用。如果不是ReferenceCounted,則什麼也不做。
關於快取的引用計數,後續再開文章做專題介紹。
1.14. 小結
對入站(Inbound )事件的處理流程,做一下小節:
Inbound 事件是通知事件,當某件事情已經就緒後,從Java IO 通知上層Netty Channel。
Inbound 事件源頭是 Channel內部的UNSafe;
Inbound 事件啟動者是 Channel,通過Pipeline. fireIN_EVT啟動。
Inbound 事件在 Pipeline 中傳輸方向是從 head 到 tail。
Inbound 事件最後一個的處理者是 TailContext, 並且其處理方法是空實現。如果沒有其他的處理者,則對Inbound ,TailContext是唯一的處理者。
Inbound 事件的向後傳遞方法是contxt.fireIN_EVT方法。在使用者Handler中,如果當前 Handler 需要將此事件繼續傳播下去,則呼叫contxt.fireIN_EVT方法。如果不這樣做, 那麼此事件的流水線傳播會提前終止。