
【Python爬蟲實戰專案一】爬取大眾點評團購詳情及團購評論
1 專案簡介
從大眾點評網收集北京市所有美髮、健身類目的團購詳情以及團購評論,儲存為本地txt檔案。
技術:Requests+BeautifulSoup
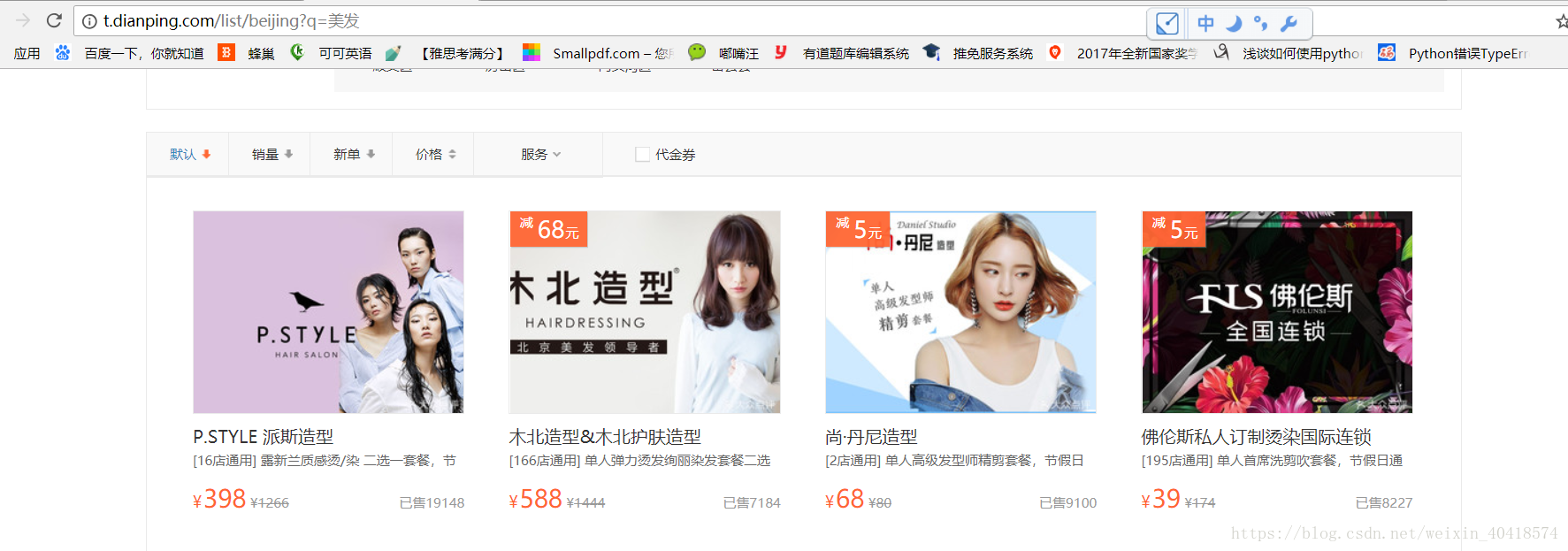
以美髮為例:http://t.dianping.com/list/beijing?q=美髮
爬取內容包括:
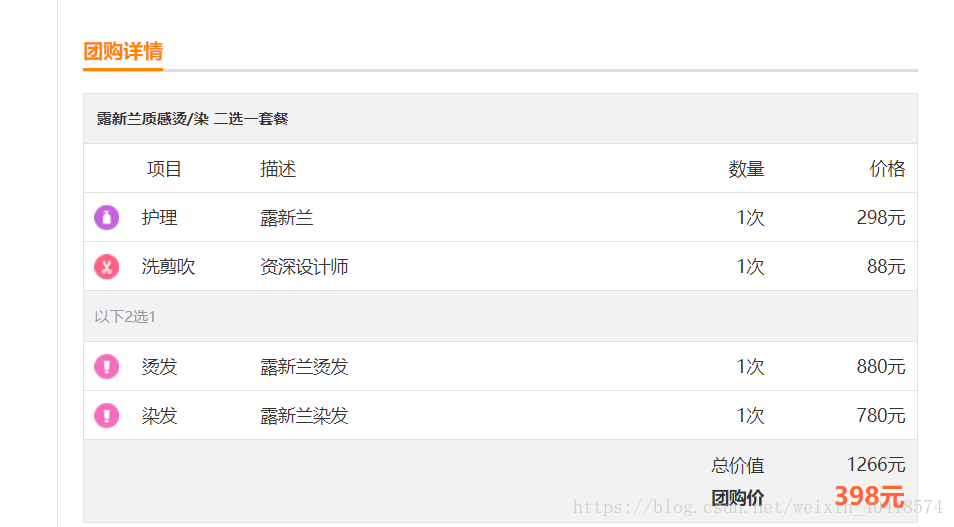
【團購詳情】團購名稱、原價(最高價)、團購價、銷量,團購裡包含的各個專案的名稱、單價。
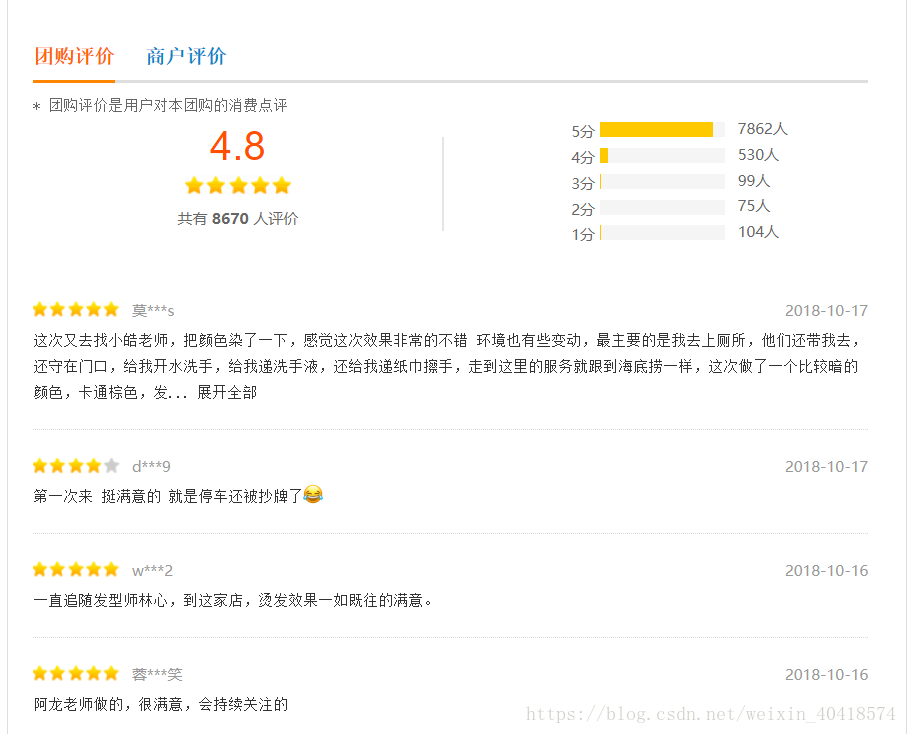
【團購評論】包括評論使用者名稱稱、評論星級、評論時間、評論內容。
2 程式結構
- 從大眾點評團購頁面獲取所有“美髮”、“健身”團購專案id的列表;
- 根據團購專案列表逐個獲取每個專案的團購詳情、團購評論;
- 儲存資料到本地檔案。
3 爬取前準備工作(以美髮為例)
爬取前需要提前檢視所要爬取資訊的位置—是靜態儲存在html頁面還是通過JavaScript動態生成?
檢視方法
在想要爬取頁面右鍵點選“檢視網頁原始碼”,在原始碼如果能搜尋到即為靜態儲存在html頁面,否則為通過JavaScript動態生成。
經過檢查,團購專案id、團購詳情靜態儲存在html中,團購評價為JavaScript動態生成。
3.1 獲取團購專案id列表、團購詳情
獲取所有團購專案id列表:http://t.dianping.com/list/beijing?q=美髮
獲取id為“6009460”團購詳情:http://t.dianping.com/deal/6009460
3.2 獲取團購評價
由於團購評價資訊由js動態生成,不存在原始碼中,需要動態載入頁面。
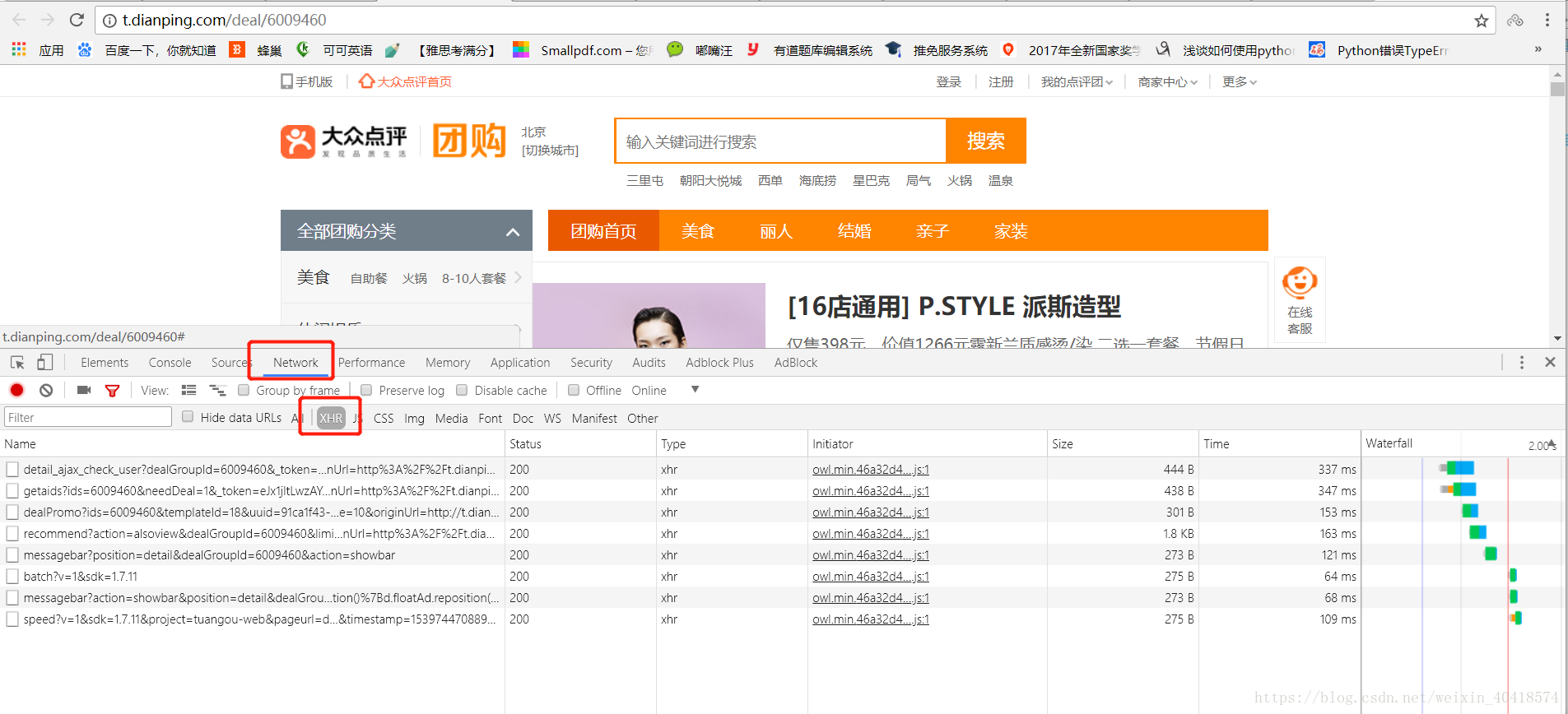
解決方案
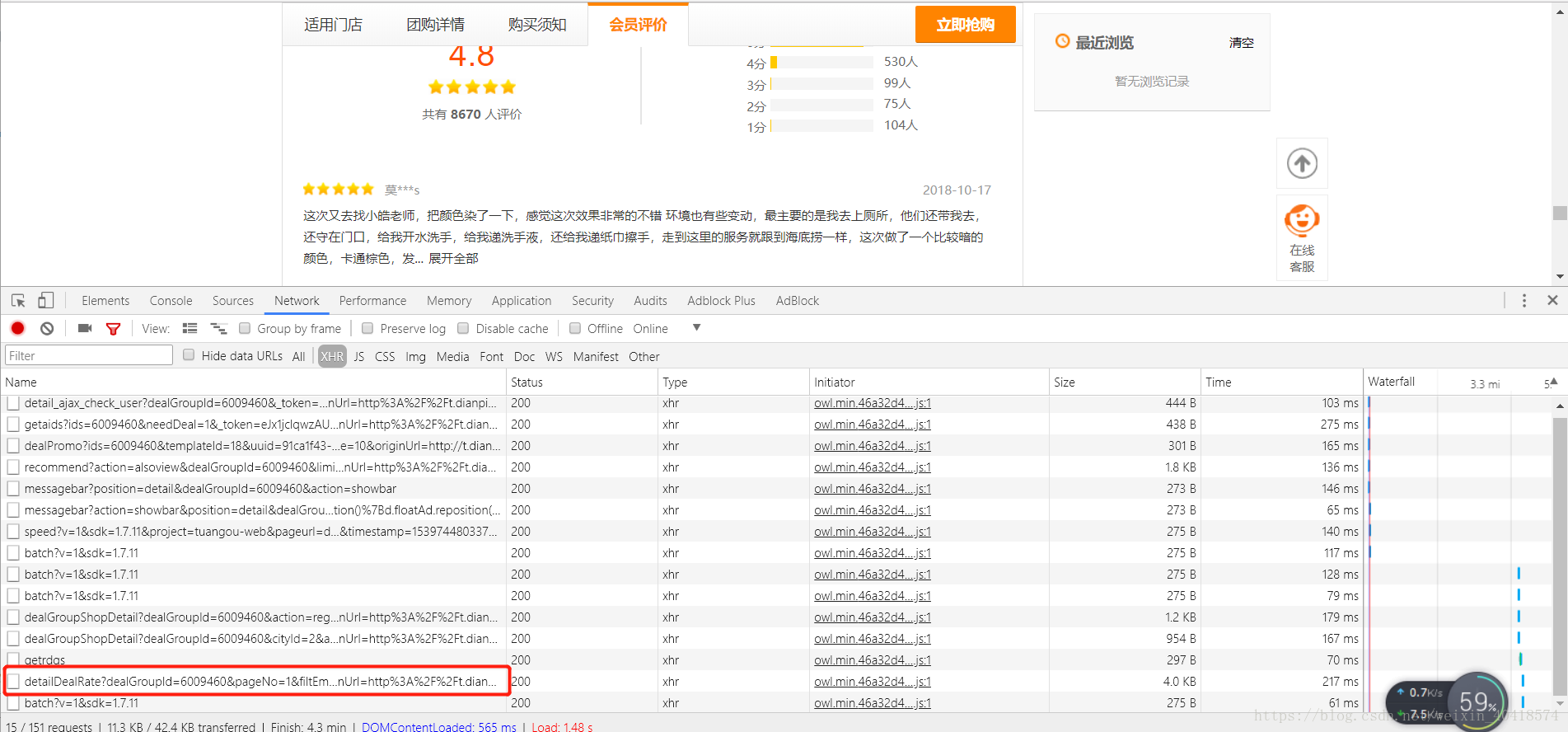
- 在團購評價所在頁面點選F12,依次點選Network和XHR開啟如下介面;
- 向下滑動頁面,直至頁面全部加載出評論資訊;
- 找到下圖中框選的“detailDealRate?..”點選開啟;
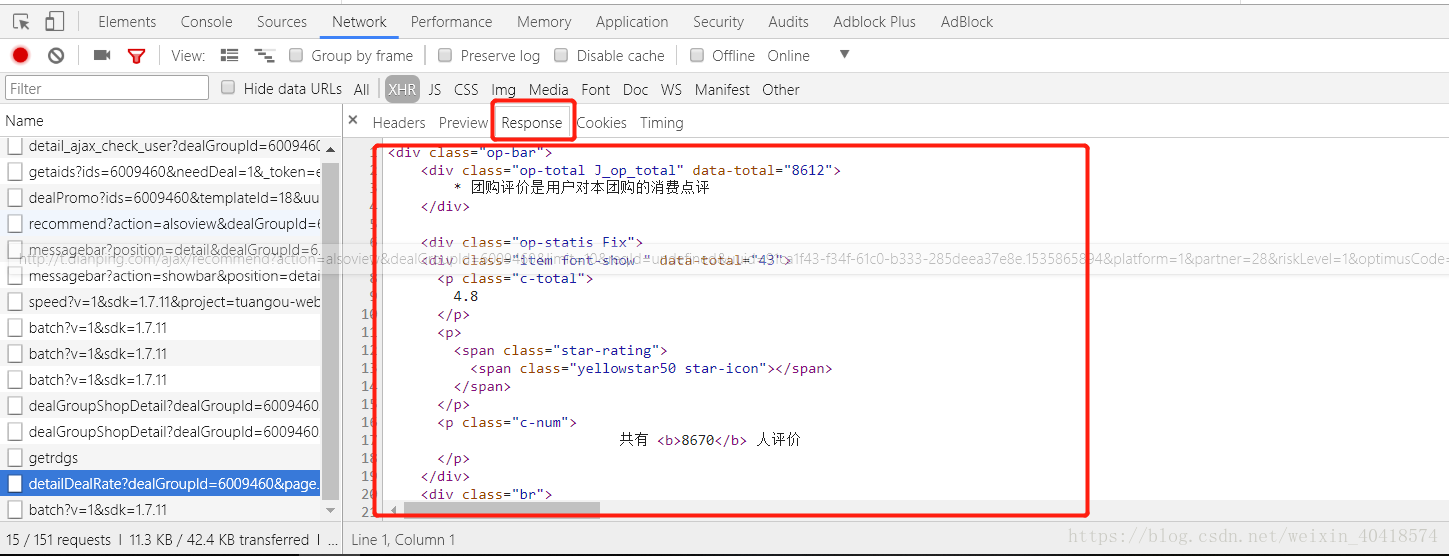
- 在Response中即可看到團購評價的原始碼;
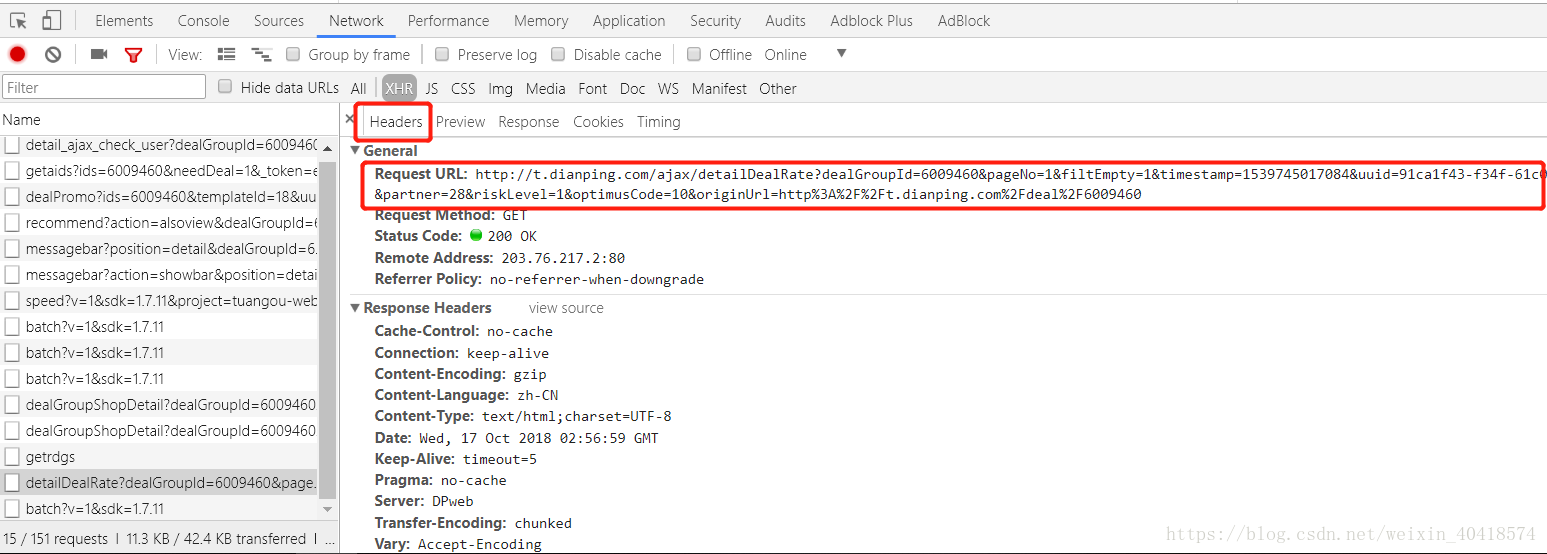
- 點選Headers獲取評論資訊的URL
3.3 實現爬取過程中的自動翻頁
【團購專案列表頁面】
第一頁URL:http://t.dianping.com/list/beijing?q=美髮
第二頁URL:http://t.dianping.com/list/beijing?q=美髮&pageIndex=1
第三頁URL:http://t.dianping.com/list/beijing?q=美髮&pageIndex=2
嘗試將第一頁URL改成:http://t.dianping.com/list/beijing?q=美髮&pageIndex=0 與原來開啟頁面一樣
【團購評價頁面】
第一頁URL:http://t.dianping.com/ajax/detailDealRate?dealGroupId=6009460&pageNo=1
第二頁URL:http://t.dianping.com/ajax/detailDealRate?dealGroupId=6009460&pageNo=2
找到規律了吧,翻頁時只需修改url中頁碼即可,不同頁面規律不同。
3.4 應對反爬技術
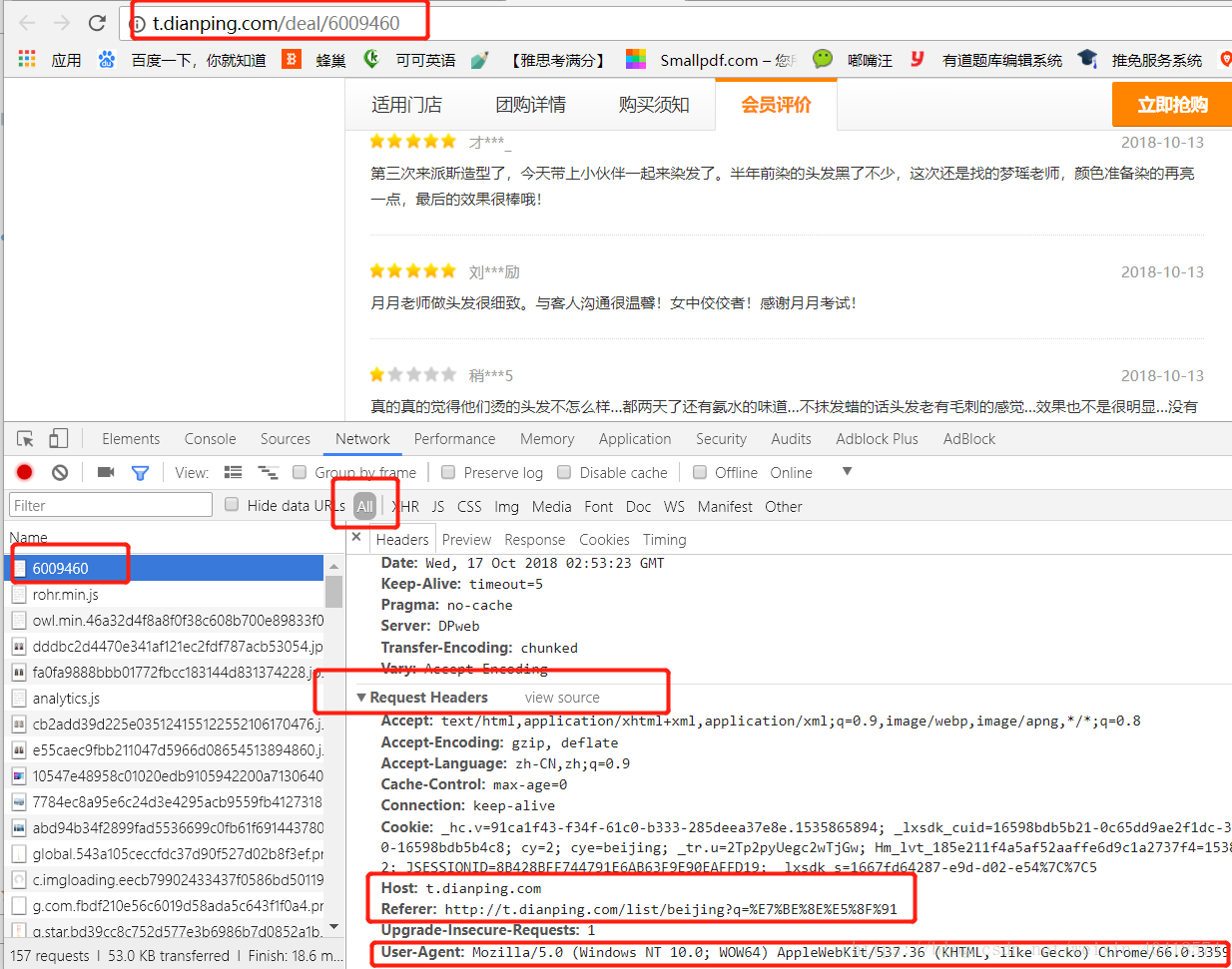
現在大部分網站都對爬蟲進行了限制,伺服器允許人類訪問,不允許“機器”訪問,所以模仿人類的訪問行為就可以解決這一問題。
解決方法:加一個請求頭完全模擬瀏覽器的請求,請求頭獲取見下圖:
4 編寫程式碼
4.1 引入所需要的庫
import requests
import re
import os
import traceback
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
from urllib.parse import quote
4.2 獲取單頁面內容
def getHtmlText(url,refer):
#模擬瀏覽器頭部資訊應對反爬
headers = {
"User-Agent": UserAgent(verify_ssl=False).random,
"Host":"t.dianping.com",
"Referer":refer
}
try:
r=requests.get(url,headers=headers)
r.raise_for_status()
if (r.encoding != "UTF-8"):
r.encoding = r.apparent_encoding
return r.text
except:
return ""
4.3 獲取所有團購專案列表
def getDealList(list,url,refer):
html=getHtmlText(url,refer)
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all("li",attrs={"class":"tg-floor-item"}):
try:
deal_id=item.attrs["data-eval-config"]
list.append(re.findall(r'\d+',deal_id)[0])
except:
continue
4.4 獲取團購詳情
def getDealInfo(list,url,refer):
path="D://deal_info.txt"
headers=["團購id","團購名稱","原價","團購價","銷量","單項名稱","單項數量","單項單價"]
for id in list[:3]: #資料太多,這裡選前三條做demo
try:
info=[]
deal_url=url+id
html=getHtmlText(deal_url,refer)
soup=BeautifulSoup(html,"html.parser")
#爬取團購名稱,原價,團購價,銷量等資訊
main_info=soup.find("div",attrs={"class":"setmeal-box J_setmeal-box"})
name=main_info.find("li")
data=eval(name.attrs["data-eval-config"])#將字串轉換成字典格式
info.append(id)#團購id
info.append(data["title"])#團購名稱
info.append(data["marketPrice"])#原價
info.append(data["price"])#團購價
info.append(data["sold"])#銷量
#爬取團購裡包含的各個專案的名稱、單價等資訊
detail_info=soup.find("table",attrs={"class":"detail-table"})
head=detail_info.find("thead")
head_list=head.find_all("th")
value=detail_info.find("tbody")
value_list=value.find_all("td")
item_num = int(len(value_list) / 3 - 1) # 三個為一組減去最後一組價格組 num表示團購專案中單項的數量
for i in range(item_num):
for j in range(len(head_list)):
info.append(re.sub(r'[\r\n" "]', "", value_list[3 * i + j].text)) # 用正則表示式去除多餘的\r\n和空格
saveInfo(info,path,headers)
except:
# 顯示錯誤資訊
traceback.print_exc()
continue
4.5 獲取團購評論
def getComInfo(list,url,refer):
com_path="D://com_info.txt"
headers=["團購id", "使用者名稱稱", "評論星級", "評論時間", "評論內容"]
page=2 #爬取評論的頁面數
#對每一個團購專案的評論
for id in list[:3]: #資料太多,這裡選前三條做demo
#對每一頁評論
for i in range(page):
com_url=url+id+"&pageNo="+str(i+1)
com_html = getHtmlText(com_url,refer+id)
com_soup = BeautifulSoup(com_html, "html.parser")
com_tag = com_soup.find_all("li", attrs={"class": "Fix"})
# 對每一條評論
for tag in com_tag:
try:
#儲存每一條評論資訊
com_info = []
star = tag.find("span", attrs={"class": "star-rating"})
com_info.append(id)#團購名稱
com_info.append(tag.find("span", attrs={"class": "name"}).text)#使用者名稱稱
com_info.append(re.search(r'\d',str(star)).group(0))#評論星級
com_info.append(tag.find("span", attrs={"class": "date"}).text)#評論時間
cont=tag.find("div", attrs={"class": "J_brief_cont_full Hide"})
#如果評論有隱藏資訊
if(cont):
com_info.append(re.sub(r'[\r\n]',"",cont.text))#評論內容
#無隱藏
else:
com_info.append(re.sub(r'[\r\n]',"",tag.find("div", attrs={"class": "J_brief_cont_full"}).text))#評論內容
saveInfo(com_info,com_path,headers)
except:
#顯示錯誤資訊
traceback.print_exc()
continue
4.5 儲存資訊到本地txt
def saveInfo(info, path,headers):
with open(path, "a", encoding="utf-8") as f:
#獲取檔案大小
file_size = os.path.getsize(path)
if file_size == 0:
# 表頭
f.write(re.sub(r'[\[\]\']', "",str(headers))+ "\n")
f.write(re.sub(r'[\[\]\']', "",str(info)) + "\n")
5 執行結果
5.1 團購評論

5.2 團購詳情(美髮、健身各選擇前三條做demo)

寫在最後
本人剛學習爬蟲不久,第一個自己寫的專案做個總結~
如有不盡完善之處,還請各位大佬指出,一起交流,一起進步~~
轉載記得標明出處哦~