
######好好好,本質#####基於LSTM搭建一個文字情感分類的深度學習模型:準確率往往有95%以上
基於情感詞典的文字情感分類
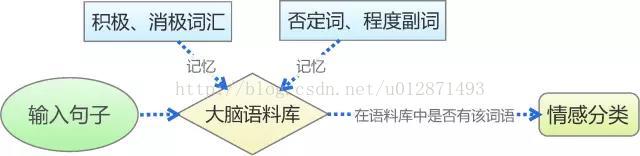
傳統的基於情感詞典的文字情感分類,是對人的記憶和判斷思維的最簡單的模擬,如上圖。我們首先通過學習來記憶一些基本詞彙,如否定詞語有“不”,積極詞語有“喜歡”、“愛”,消極詞語有“討厭”、“恨”等,從而在大腦中形成一個基本的語料庫。然後,我們再對輸入的句子進行最直接的拆分,看看我們所記憶的詞彙表中是否存在相應的詞語,然後根據這個詞語的類別來判斷情感,比如“我喜歡數學”,“喜歡”這個詞在我們所記憶的積極詞彙表中,所以我們判斷它具有積極的情感。
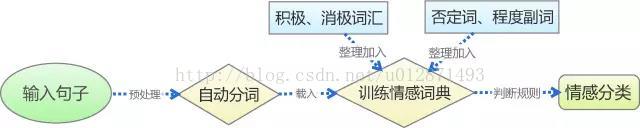
基於上述思路,我們可以通過以下幾個步驟實現基於情感詞典的文字情感分類:預處理、分詞、訓練情感詞典、判斷,整個過程可以如下圖所示。而檢驗模型用到的原材料,包括薛雲老師提供的蒙牛牛奶的評論,以及從網路購買的某款手機的評論資料(見附件)。
文字的預處理
由網路爬蟲等工具爬取到的原始語料,通常都會帶有我們不需要的資訊,比如額外的Html標籤,所以需要對語料進行預處理。由薛雲老師提供的蒙牛牛奶評論也不例外。我們隊伍使用Python作為我們的預處理工具,其中的用到的庫有Numpy和Pandas,而主要的文字工具為正則表示式。經過預處理,原始語料規範為如下表,其中我們用-1標註消極情感評論,1標記積極情感評論。
句子自動分詞
為了判斷句子中是否存在情感詞典中相應的詞語,我們需要把句子準確切割為一個個詞語,即句子的自動分詞。我們對比了現有的分詞工具,綜合考慮了分詞的準確性和在Python平臺的易用性,最終選擇了“結巴中文分詞”作為我們的分詞工具。
下表僅展示各常見的分詞工具對其中一個典型的測試句子的分詞效果:
測試句子:工信處女幹事每月經過下屬科室都要親口交代24口交換機等技術性器件的安裝工作
| 分詞工具 | 測試結果 |
| 結巴中文分詞 | 工信處/ 女幹事/ 每月/ 經過/ 下屬/ 科室/ 都/ 要/ 親口/ 交代/ 24/ 口/ 交換機/ 等/ 技術性/ 器件/ 的/ 安裝/ 工作 |
| 中科院分詞 | 工/n 信/n 處女/n 幹事/n 每月/r 經過/p 下屬/v 科室/n 都/d 要/v 親口/d 交代/v 24/m 口/q 交換機/n 等/udeng 技術性/n 器件/n 的/ude1 安裝/vn 工作/vn |
| smallseg | 工信/ 信處/ 女幹事/ 每月/ 經過/ 下屬/ 科室/ 都要/ 親口/ 交代/ 24/ 口/ 交換機/ 等/ 技術性/ 器件/ 的/ 安裝/ 工作 |
| Yaha 分詞 | 工信處 / 女 / 幹事 / 每月 / 經過 / 下屬 / 科室 / 都 / 要 / 親口 / 交代 / 24 / 口 / 交換機 / 等 / 技術性 / 器件 / 的 / 安裝 / 工作 |
載入情感詞典
一般來說,詞典是文字挖掘最核心的部分,對於文字感情分類也不例外。情感詞典分為四個部分:積極情感詞典、消極情感詞典、否定詞典以及程度副詞詞典。為了得到更加完整的情感詞典,我們從網路上收集了若干個情感詞典,並且對它們進行了整合去重,同時對部分詞語進行了調整,以達到儘可能高的準確率。
我們隊伍並非單純對網路收集而來的詞典進行整合,而且還有針對性和目的性地對詞典進行了去雜、更新。特別地,我們加入了某些行業詞彙,以增加分類中的命中率。不同行業某些詞語的詞頻會有比較大的差別,而這些詞有可能是情感分類的關鍵詞之一。比如,薛雲老師提供的評論資料是有關蒙牛牛奶的,也就是飲食行業的;而在飲食行業中,“吃”和“喝”這兩個詞出現的頻率會相當高,而且通常是對飲食的正面評價,而“不吃”或者“不喝”通常意味著對飲食的否定評價,而在其他行業或領域中,這幾個詞語則沒有明顯情感傾向。另外一個例子是手機行業的,比如“這手機很耐摔啊,還防水”,“耐摔”、“防水”就是在手機這個領域有積極情緒的詞。因此,有必要將這些因素考慮進模型之中。
文字情感分類
基於情感詞典的文字情感分類規則比較機械化。簡單起見,我們將每個積極情感詞語賦予權重1,將每個消極情感詞語賦予權重-1,並且假設情感值滿足線性疊加原理;然後我們將句子進行分詞,如果句子分詞後的詞語向量包含相應的詞語,就加上向前的權值,其中,否定詞和程度副詞會有特殊的判別規則,否定詞會導致權值反號,而程度副詞則讓權值加倍。最後,根據總權值的正負性來判斷句子的情感。基本的演算法如圖。
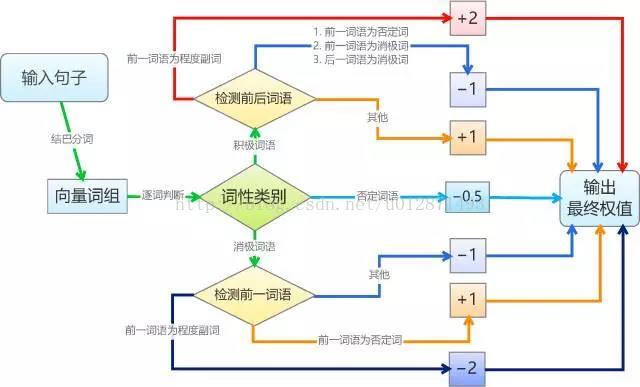
要說明的是,為了程式設計和測試的可行性,我們作了幾個假設(簡化)。假設一:我們假設了所有積極詞語、消極詞語的權重都是相等的,這只是在簡單的判斷情況下成立,更精準的分類顯然不成立的,比如“恨”要比“討厭”來得嚴重;修正這個缺陷的方法是給每個詞語賦予不同的權值,我們將在本文的第二部分探討權值的賦予思路。假設二:我們假設了權值是線性疊加的,這在多數情況下都會成立,而在本文的第二部分中,我們會探討非線性的引入,以增強準確性。假設三:對於否定詞和程度副詞的處理,我們僅僅是作了簡單的取反和加倍,而事實上,各個否定詞和程度副詞的權值也是不一樣的,比如“非常喜歡”顯然比“挺喜歡”程度深,但我們對此並沒有區分。
在演算法的實現上,我們則選用了Python作為實現平臺。可以看到,藉助於Python豐富的擴充套件支援,我們僅用了一百行不到的程式碼,就實現了以上所有步驟,得到了一個有效的情感分類演算法,這充分體現了Python的簡潔。下面將檢驗我們演算法的有效性。
模型結果檢驗
作為最基本的檢驗,我們首先將我們的模型運用於薛雲老師提供的蒙牛牛奶評論中,結果是讓人滿意的,達到了82.02%的正確率,詳細的檢驗報告如下表

讓我們驚喜的是,將從蒙牛牛奶評論資料中調整出來的模型,直接應用到某款手機的評論資料的情感分類中,也達到了81.96%準確率!這表明我們的模型具有較好的強健性,能在不同行業的評論資料的情感分類中都有不錯的表現。

結論:我們隊伍初步實現了基於情感詞典的文字情感分類,測試結果表明,通過簡單的判斷規則就能夠使這一演算法具有不錯的準確率,同時具有較好的強健性。一般認為,正確率達80%以上的模型具有一定的生產價值,能適用於工業環境。顯然,我們的模型已經初步達到了這個標準。
困難所在
經過兩次測試,可以初步認為我們的模型正確率基本達到了80%以上。另外,一些比較成熟的商業化程式,它的正確率也只有85%到90%左右(如BosonNLP)。這說明我們這個簡單的模型確實已經達到了讓人滿意的效果,另一方面,該事實也表明,傳統的“基於情感詞典的文字情感分類”模型的效能可提升幅度相當有限。這是由於文字情感分類的本質複雜性所致的。經過初步的討論,我們認為文字情感分類的困難在以下幾個方面。
語言系統是相當複雜的
歸根結底,這是因為我們大腦中的語言系統是相當複雜的。(1)我們現在做的是文字情感分類,文字和文字情感都是人類文化的產物,換言之,人是唯一準確的判別標準。(2)人的語言是一個相當複雜的文化產物,一個句子並不是詞語的簡單線性組合,它有相當複雜的非線性在裡面。(3)我們在描述一個句子時,都是將句子作為一個整體而不是詞語的集合看待的,詞語的不同組合、不同順序、不同數目都能夠帶來不同的含義和情感,這導致了文字情感分類工作的困難。
因此,文字情感分類工作實際上是對人腦思維的模擬。我們前面的模型,實際上已經對此進行了最簡單的模擬。然而,我們模擬的不過是一些簡單的思維定式,真正的情感判斷並不是一些簡單的規則,而是一個複雜的網路。
大腦不僅僅在情感分類
事實上,我們在判斷一個句子的情感時,我們不僅僅在想這個句子是什麼情感,而且還會判斷這個句子的型別(祈使句、疑問句還是陳述句?);當我們在考慮句子中的每個詞語時,我們不僅僅關注其中的積極詞語、消極詞語、否定詞或者程度副詞,我們會關注每一個詞語(主語、謂語、賓語等等),從而形成對整個句子整體的認識;我們甚至還會聯絡上下文對句子進行判斷。這些判斷我們可能是無意識的,但我們大腦確實做了這個事情,以形成對句子的完整認識,才能對句子的感情做了準確的判斷。也就是說,我們的大腦實際上是一個非常高速而複雜的處理器,我們要做情感分類,卻同時還做了很多事情。
活水:學習預測
人類區別於機器、甚至人類區別於其他動物的顯著特徵,是人類具有學習意識和學習能力。我們獲得新知識的途徑,除了其他人的傳授外,還包括自己的學習、總結和猜測。對於文字情感分類也不例外,我們不僅僅可以記憶住大量的情感詞語,同時我們還可以總結或推測出新的情感詞語。比如,我們只知道“喜歡”和“愛”都具有積極情感傾向,那麼我們會猜測“喜愛”也具有積極的情感色彩。這種學習能力是我們擴充我們的詞語的重要方式,也是記憶模式的優化(即我們不需要專門往大腦的語料庫中塞進“喜愛”這個詞語,我們僅需要記得“喜歡”和“愛”,並賦予它們某種聯絡,以獲得“喜愛”這個詞語,這是一種優化的記憶模式)。
優化思路
經過上述分析,我們看到了文字情感分類的本質複雜性以及人腦進行分類的幾個特徵。而針對上述分析,我們提出如下幾個改進措施。
非線性特徵的引入
前面已經提及過,真實的人腦情感分類實際上是嚴重非線性的,基於簡單線性組合的模型效能是有限的。所以為了提高模型的準確率,有必要在模型中引入非線性。
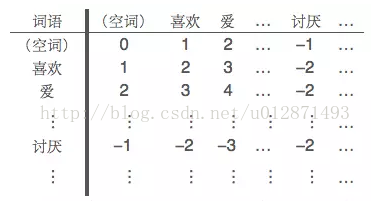
所謂非線性,指的是詞語之間的相互組合形成新的語義。事實上,我們的初步模型中已經簡單地引入了非線性——在前面的模型中,我們將積極詞語和消極詞語相鄰的情況,視為一個組合的消極語塊,賦予它負的權值。更精細的組合權值可以通過“詞典矩陣”來實現,即我們將已知的積極詞語和消極詞語都放到同一個集合來,然後逐一編號,通過如下的“詞典矩陣”,來記錄片語的權值。
並不是每一個詞語的組合都是成立的,但我們依然可以計算它們之間的組合權值,情感權值的計算可以閱讀參考文獻。然而,情感詞語的數目相當大,而詞典矩陣的元素個數則是其平方,其資料量是相當可觀的,因此,這已經初步進入大資料的範疇。為了更加高效地實現非線性,我們需要探索組合詞語的優化方案,包括構造方案和儲存、索引方案。
情感詞典的自動擴充
在如今的網路資訊時代,新詞的出現如雨後春筍,其中包括“新構造網路詞語”以及“將已有詞語賦予新的含義”;另一方面,我們整理的情感詞典中,也不可能完全包含已有的情感詞語。因此,自動擴充情感詞典是保證情感分類模型時效性的必要條件。目前,通過網路爬蟲等手段,我們可以從微博、社群中收集到大量的評論資料,為了從這大批量的資料中找到新的具有情感傾向的詞語,我們的思路是無監督學習式的詞頻統計。
我們的目標是“自動擴充”,因此我們要達到的目的是基於現有的初步模型來進行無監督學習,完成詞典擴充,從而增強模型自身的效能,然後再以同樣的方式進行迭代,這是一個正反饋的調節過程。雖然我們可以從網路中大量抓取評論資料,但是這些資料是無標註的,我們要通過已有的模型對評論資料進行情感分類,然後在同一類情感(積極或消極)的評論集合中統計各個詞語的出現頻率,最後將積極、消極評論集的各個詞語的詞頻進行對比。某個詞語在積極評論集中的詞頻相當高,在消極評論集中的詞頻相當低,那麼我們就有把握將該詞語新增到消極情感詞典中,或者說,賦予該詞語負的權值。
舉例來說,假設我們的消極情感詞典中並沒有“黑心”這個詞語,但是“可惡”、“討厭”、“反感”、“喜歡”等基本的情感詞語在情感詞典中已經存在,那麼我們就會能夠將下述句子正確地進行情感分類:
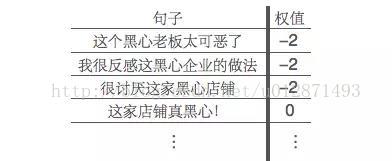
其中,由於消極情感詞典中沒有“黑心”這個詞語,所以“這家店鋪真黑心!”就只會被判斷為中性(即權值為0)。分類完成後,對所有詞頻為正和為負的分別統計各個詞頻,我們發現,新詞語“黑心”在負面評論中出現很多次,但是在正面評論中幾乎沒有出現,那麼我們就將黑心這個詞語新增到我們的消極情感詞典中,然後更新我們的分類結果:
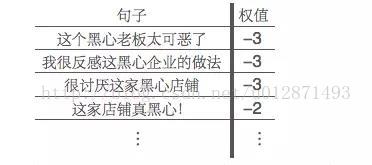
於是我們就通過無監督式的學習擴充了詞典,同時提高了準確率,增強了模型的效能。這是一個反覆迭代的過程,前一步的結果可以幫助後一步的進行。
綜合上述研究,我們得出如下結論:
基於情感詞典的文字情感分類是容易實現的,其核心之處在於情感詞典的訓練。
語言系統是相當複雜的,基於情感詞典的文字情感分類只是一個線性的模型,其效能是有限的。
在文字情感分類中適當地引入非線性特徵,能夠有效地提高模型的準確率。
引入擴充詞典的無監督學習機制,可以有效地發現新的情感詞,保證模型的強健性和時效性。
在文字情感分類傳統模型的思路簡單易懂,而且穩定性也比較強,然而存在著兩個難以克服的侷限性:
一、精度問題,傳統思路差強人意,當然一般的應用已經足夠了,但是要進一步提高精度,卻缺乏比較好的方法;
二、背景知識問題,傳統思路需要事先提取好情感詞典,而這一步驟,往往需要人工操作才能保證準確率,換句話說,做這個事情的人,不僅僅要是資料探勘專家,還需要語言學家,這個背景知識依賴性問題會阻礙著自然語言處理的進步。
慶幸的是,深度學習解決了這個問題(至少很大程度上解決了),它允許我們在幾乎“零背景”的前提下,為某個領域的實際問題建立模型。本文延續上一篇文章所談及的文字情感分類為例,簡單講解深度學習模型。其中上一篇文章已經詳細討論過的部分,本文不再詳細展開。
深度學習與自然語言處理
近年來,深度學習演算法被應用到了自然語言處理領域,獲得了比傳統模型更優秀的成果。如Bengio等學者基於深度學習的思想構建了神經概率語言模型,並進一步利用各種深層神經網路在大規模英文語料上進行語言模型的訓練,得到了較好的語義表徵,完成了句法分析和情感分類等常見的自然語言處理任務,為大資料時代的自然語言處理提供了新的思路。
經過筆者的測試,基於深度神經網路的情感分析模型,其準確率往往有95%以上,深度學習演算法的魅力和威力可見一斑!
關於深度學習進一步的資料,請參考以下文獻:
-
[1] Yoshua Bengio, Réjean Ducharme Pascal Vincent, Christian Jauvin. A Neural Probabilistic Language Model, 2003
-
[2] 一種新的語言模型:http://blog.sciencenet.cn/blog-795431-647334.html
-
[3] Deep Learning(深度學習)學習筆記整理:http://blog.csdn.net/zouxy09/article/details/8775360
-
[4] Deep Learning:http://deeplearning.net
-
[5] 漫話中文自動分詞和語義識別:http://www.matrix67.com/blog/archives/4212
-
[6] Deep Learning 在中文分詞和詞性標註任務中的應用:http://blog.csdn.net/itplus/article/details/13616045
語言的表達
建模環節中最重要的一步是特徵提取,在自然語言處理中也不例外。在自然語言處理中,最核心的一個問題是,如何把一個句子用數字的形式有效地表達出來?如果能夠完成這一步,句子的分類就不成問題了。顯然,一個最初等的思路是:給每個詞語賦予唯一的編號1,2,3,4...,然後把句子看成是編號的集合,比如假設1,2,3,4分別代表“我”、“你”、“愛”、“恨”,那麼“我愛你”就是[1, 3, 2],“我恨你”就是[1, 4, 2]。這種思路看起來有效,實際上非常有問題,比如一個穩定的模型會認為3跟4是很接近的,因此[1, 3, 2]和[1, 4, 2]應當給出接近的分類結果,但是按照我們的編號,3跟4所代表的詞語意思完全相反,分類結果不可能相同。因此,這種編碼方式不可能給出好的結果。
讀者也許會想到,我將意思相近的詞語的編號湊在一堆(給予相近的編號)不就行了?嗯,確實如果,如果有辦法把相近的詞語編號放在一起,那麼確實會大大提高模型的準確率。可是問題來了,如果給出每個詞語唯一的編號,並且將相近的詞語編號設為相近,實際上是假設了語義的單一性,也就是說,語義僅僅是一維的。然而事實並非如此,語義應該是多維的。
比如我們談到“家園”,有的人會想到近義詞“家庭”,從“家庭”又會想到“親人”,這些都是有相近意思的詞語;另外,從“家園”,有的人會想到“地球”,從“地球”又會想到“火星”。換句話說,“親人”、“火星”都可以看作是“家園”的二級近似,但是“親人”跟“火星”本身就沒有什麼明顯的聯絡了。此外,從語義上來講,“大學”、“舒適”也可以看做是“家園”的二級近似,顯然,如果僅通過一個唯一的編號,是很難把這些詞語放到適合的位置的。
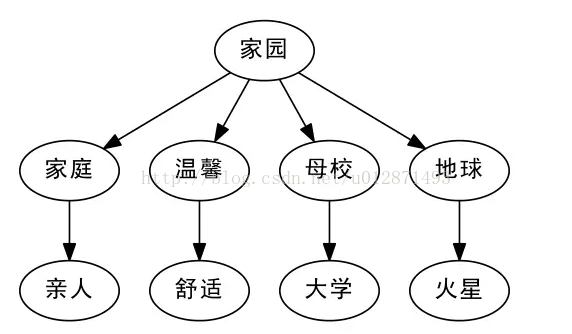
Word2Vec:高維來了
從上面的討論可以知道,很多詞語的意思是各個方向發散開的,而不是單純的一個方向,因此唯一的編號不是特別理想。那麼,多個編號如何?換句話說,將詞語對應一個多維向量?不錯,這正是非常正確的思路。
為什麼多維向量可行?首先,多維向量解決了詞語的多方向發散問題,僅僅是二維向量就可以360度全方位旋轉了,何況是更高維呢(實際應用中一般是幾百維)。其次,還有一個比較實際的問題,就是多維向量允許我們用變化較小的數字來表徵詞語。怎麼說?我們知道,就中文而言,詞語的數量就多達數十萬,如果給每個詞語唯一的編號,那麼編號就是從1到幾十萬變化,變化幅度如此之大,模型的穩定性是很難保證的。如果是高維向量,比如說20維,那麼僅需要0和1就可以表達220=1048576
(100萬)個詞語了。變化較小則能夠保證模型的穩定性。
扯了這麼多,還沒有真正談到點子上。現在思路是有了,問題是,如何把這些詞語放到正確的高維向量中?而且重點是,要在沒有語言背景的情況下做到這件事情?(換句話說,如果我想處理英語語言任務,並不需要先學好英語,而是隻需要大量收集英語文章,這該多麼方便呀!)在這裡我們不可能也不必要進行更多的原理上的展開,而是要介紹:而基於這個思路,有一個Google開源的著名的工具——Word2Vec。
簡單來說,Word2Vec就是完成了上面所說的我們想要做的事情——用高維向量(詞向量,Word Embedding)表示詞語,並把相近意思的詞語放在相近的位置,而且用的是實數向量(不侷限於整數)。我們只需要有大量的某語言的語料,就可以用它來訓練模型,獲得詞向量。詞向量好處前面已經提到過一些,或者說,它就是問了解決前面所提到的問題而產生的。另外的一些好處是:詞向量可以方便做聚類,用歐氏距離或餘弦相似度都可以找出兩個具有相近意思的詞語。這就相當於解決了“一義多詞”的問題(遺憾的是,似乎沒什麼好思路可以解決一詞多義的問題。)
而Word2Vec的實現,Google官方提供了C語言的原始碼,讀者可以自行編譯。而Python的Gensim庫中也提供現成的Word2Vec作為子庫(事實上,這個版本貌似比官方的版本更加強大)。
表達句子:句向量
接下來要解決的問題是:我們已經分好詞,並且已經將詞語轉換為高維向量,那麼句子就對應著詞向量的集合,也就是矩陣,類似於影象處理,影象數字化後也對應一個畫素矩陣;可是模型的輸入一般只接受一維的特徵,那怎麼辦呢?一個比較簡單的想法是將矩陣展平,也就是將詞向量一個接一個,組成一個更長的向量。這個思路是可以,但是這樣就會使得我們的輸入維度高達幾千維甚至幾萬維,事實上是難以實現的。(如果說幾萬維對於今天的計算機來說不是問題的話,那麼對於1000x1000的影象,就是高達100萬維了!)
事實上,對於影象處理來說,已經有一套成熟的方法了,叫做卷積神經網路(CNNs),它是神經網路的一種,專門用來處理矩陣輸入的任務,能夠將矩陣形式的輸入編碼為較低維度的一維向量,而保留大多數有用資訊。卷積神經網路那一套也可以直接搬到自然語言處理中,尤其是文字情感分類中,效果也不錯,相關的文章有《Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts》。但是句子的原理不同於影象,直接將影象那一套用於語言,雖然略有小成,但總讓人感覺不倫不類。因此,這並非自然語言處理中的主流方法。
在自然語言處理中,通常用到的方法是遞迴神經網路或迴圈神經網路(都叫RNNs)。它們的作用跟卷積神經網路是一樣的,將矩陣形式的輸入編碼為較低維度的一維向量,而保留大多數有用資訊。跟卷積神經網路的區別在於,卷積神經網路更注重全域性的模糊感知(好比我們看一幅照片,事實上並沒有看清楚某個畫素,而只是整體地把握圖片內容),而RNNs則是注重鄰近位置的重構,由此可見,對於語言任務,RNNs更具有說服力(語言總是由相鄰的字構成詞,相鄰的詞構成短語,相鄰的短語構成句子,等等,因此,需要有效地把鄰近位置的資訊進行有效的整合,或者叫重構)。
說到模型的分類,可真謂無窮無盡。在RNNs這個子集之下,又有很多個變種,如普通的RNNs,以及GRU、LSTM等,讀者可以參考Keras的官方文件:http://keras.io/models/,它是Python是一個深度學習庫,提供了大量的深度學習模型,它的官方文件既是一個幫助教程,也是一個模型的列表——它基本實現了目前流行的深度學習模型。
搭建LSTM模型
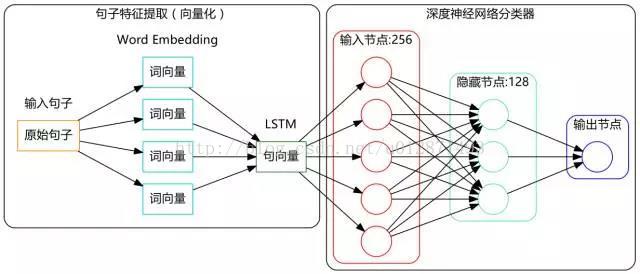
吹了那麼久水,是該乾點實事了。現在我們基於LSTM(Long-Short Term Memory,長短期記憶人工神經網路)搭建一個文字情感分類的深度學習模型,其結構圖如下:
模型結構很簡單,沒什麼複雜的,實現也很容易,用的就是Keras,它都為我們實現好了現成的演算法了。
現在我們來談談有意思的兩步。
第一步是標註語料的收集。要注意我們的模型是監督訓練的(至少也是半監督),所以需要收集一些已經分好類的句子,數量嘛,當然越多越好。而對於中文文字情感分類來說,這一步著實不容易,中文的資料往往是相當匱乏的。筆者在做模型的時候,東拼西湊,通過各種渠道(有在網上搜索下載的、有在資料堂花錢購買的)收集了兩萬多條中文標註語料(涉及六個領域)用來訓練模型。
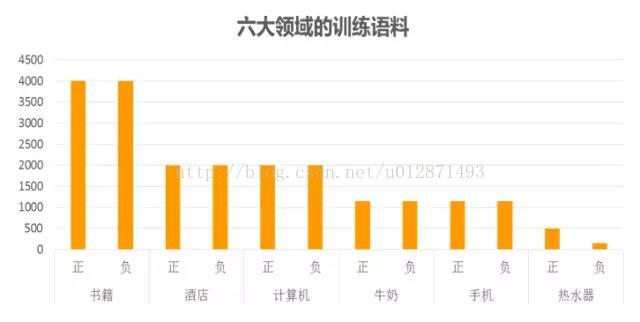
第二步是模型閾值選取問題。事實上,訓練的預測結果是一個[0, 1]區間的連續的實數,而程式預設情況下會將0.5設為閾值,也就是將大於0.5的結果判斷為正,將小於0.5的結果判斷為負。這樣的預設值在很多情況下並不是最好的。如下圖所示,我們在研究不同的閾值對真正率和真負率的影響之時,發現在(0.391, 0.394)區間內曲線曲線了陡變。
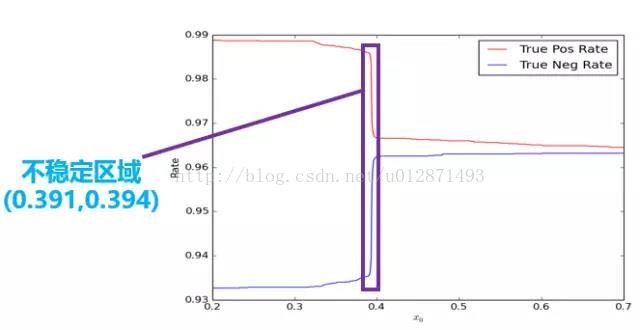
雖然從絕對值看,只是從0.99下降到了0.97,變化不大,但是其變化率是非常大的。正常來說都是平穩變化的,陡變意味著肯定出現了什麼異常情況,而顯然這個異常的原因我們很難發現。換句話說,這裡存在一個不穩定的區域,這個區域內的預測結果事實上是不可信的,因此,保險起見,我們扔掉這個區間。只有結果大於0.394的,我們才認為是正,小於0.391的,我們才認為是負,是0.391到0.394之間的,我們待定。實驗表明這個做法有助於提高模型的應用準確率。
說點總結
文章很長,粗略地介紹了深度學習在文字情感分類中的思路和實際應用,很多東西都是泛泛而談。筆者並非要寫關於深度學習的教程,而是隻想把關鍵的地方指出來,至少是那些我認為是比較關鍵的地方。關於深度學習,有很多不錯的教程,最好還是閱讀英文的論文,中文的比較好的就是部落格http://blog.csdn.net/itplus了,筆者就不在這方面獻醜了。
下面是我的語料和程式碼。讀者可能會好奇我為什麼會把這些“私人珍藏”共享呢?其實很簡單,因為我不是幹這行的哈,資料探勘對我來說只是一個愛好,一個數學與Python結合的愛好,因此在這方面,我不用擔心別人比我領先哈。
語料下載,和採集到的評論資料,密碼:dva4
搭建LSTM做文字情感分類的程式碼:
import pandas as pd #匯入Pandas
import numpy as np #匯入Numpy
import jieba #匯入結巴分詞
from keras.preprocessing import sequence
from keras.optimizers import SGD, RMSprop, Adagrad
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM, GRU
from __future__ import absolute_import #匯入3.x的特徵函式
from __future__ import print_function
neg=pd.read_excel('neg.xls',header=None,index=None)
pos=pd.read_excel('pos.xls',header=None,index=None) #讀取訓練語料完畢
pos['mark']=1
neg['mark']=0 #給訓練語料貼上標籤
pn=pd.concat([pos,neg],ignore_index=True) #合併語料
neglen=len(neg)
poslen=len(pos) #計算語料數目
cw = lambda x: list(jieba.cut(x)) #定義分詞函式
pn['words'] = pn[0].apply(cw)
comment = pd.read_excel('sum.xls') #讀入評論內容
#comment = pd.read_csv('a.csv', encoding='utf-8')
comment = comment[comment['rateContent'].notnull()] #僅讀取非空評論
comment['words'] = comment['rateContent'].apply(cw) #評論分詞
d2v_train = pd.concat([pn['words'], comment['words']], ignore_index = True)
w = [] #將所有詞語整合在一起
for i in d2v_train:
w.extend(i)
dict = pd.DataFrame(pd.Series(w).value_counts()) #統計詞的出現次數
del w,d2v_train
dict['id']=list(range(1,len(dict)+1))
get_sent = lambda x: list(dict['id'][x])
pn['sent'] = pn['words'].apply(get_sent) #速度太慢
maxlen = 50
print("Pad sequences (samples x time)")
pn['sent'] = list(sequence.pad_sequences(pn['sent'], maxlen=maxlen))
x = np.array(list(pn['sent']))[::2] #訓練集
y = np.array(list(pn['mark']))[::2]
xt = np.array(list(pn['sent']))[1::2] #測試集
yt = np.array(list(pn['mark']))[1::2]
xa = np.array(list(pn['sent'])) #全集
ya = np.array(list(pn['mark']))
print('Build model...')
model = Sequential()
model.add(Embedding(len(dict)+1, 256))
model.add(LSTM(256, 128)) # try using a GRU instead, for fun
model.add(Dropout(0.5))
model.add(Dense(128, 1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', class_mode="binary")
model.fit(xa, ya, batch_size=16, nb_epoch=10) #訓練時間為若干個小時
classes = model.predict_classes(xa)
acc = np_utils.accuracy(classes, ya)
print('Test accuracy:', acc)