
python爬蟲-基礎入門-爬取整個網站《1》
阿新 • • 發佈:2018-11-04
python爬蟲-基礎入門-爬取整個網站《1》
描述:
使用環境:python2.7.15 ,開發工具:pycharm,現爬取一個網站頁面(http://www.baidu.com)所有資料。
python程式碼如下:
1 # -*- coding: utf-8 -*- 2 3 import urllib2 4 5 def baiduNet() : 6 7 request = urllib2.Request("http://www.baidu.com") 8 response = urllib2.urlopen(request) 9 netcontext = response.read()10 11 file = open("baidutext.txt","w") 12 file.write(netcontext) 13 14 15 if __name__ == "__main__" : 16 baiduNet()
執行後baidutext.txt資料,部分截圖如下:
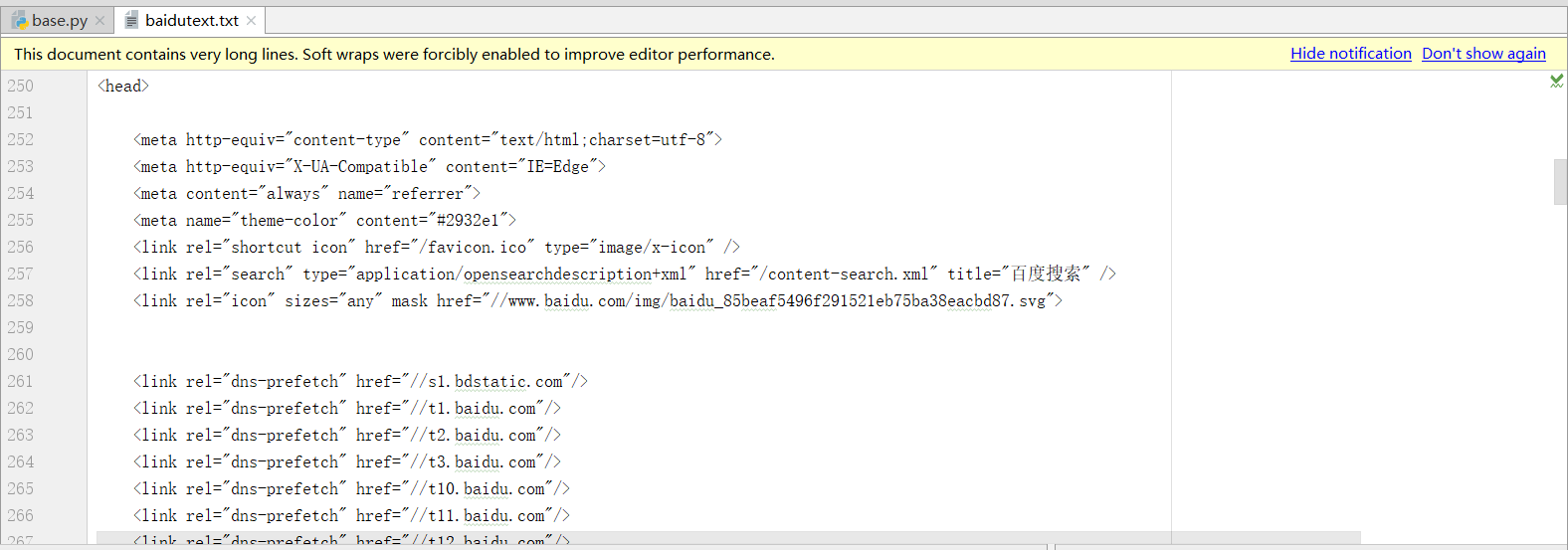
開啟瀏覽器,訪問百度,滑鼠右鍵頁面,檢視原始碼,如下:
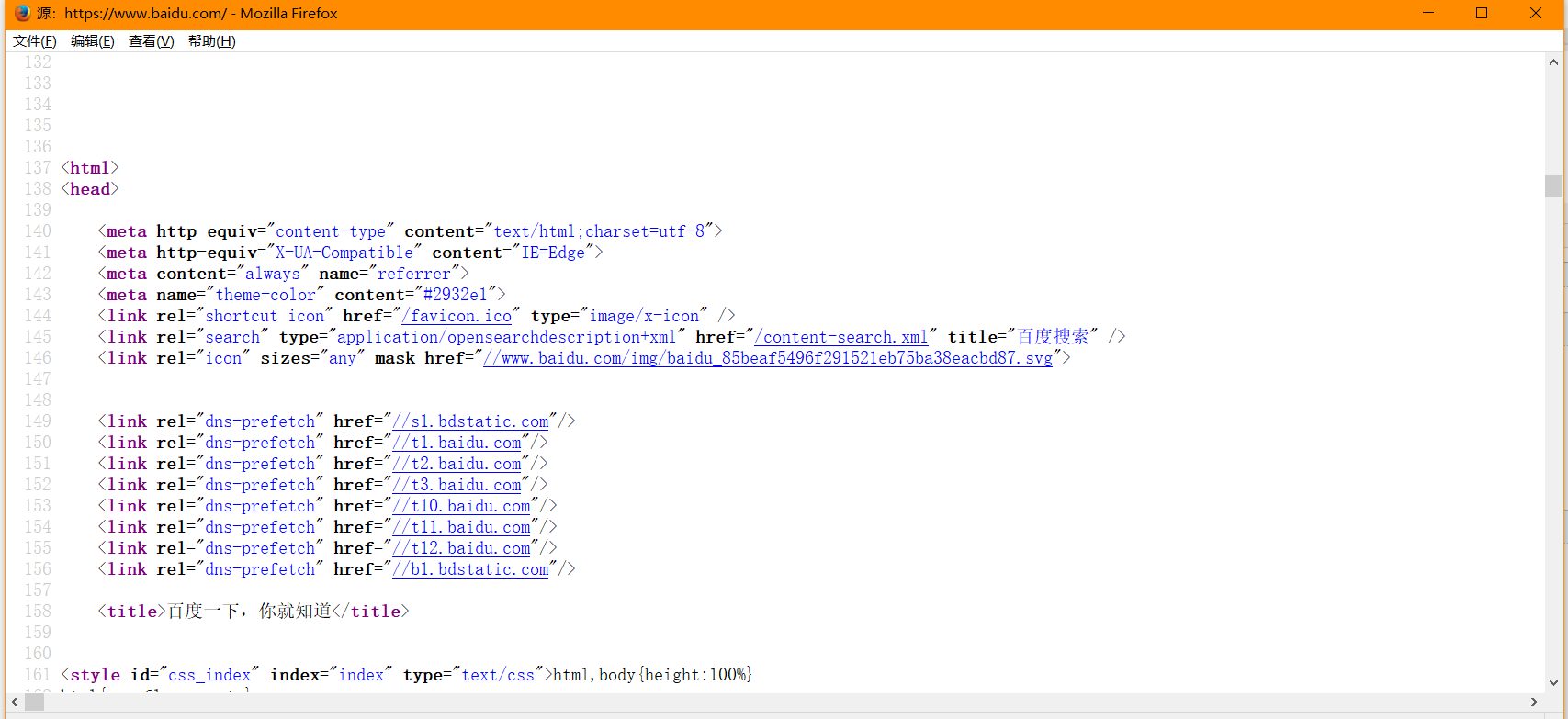
使用程式碼爬取到的頁面資料和源網站頁面資料是一樣的,爬取網頁成功。
如有問題,歡迎糾正!!!
如有轉載,請標明源處:https://www.cnblogs.com/Charles-Yuan/p/9903221.html