
Hufman編碼實現運用1 (原理不描述)
阿新 • • 發佈:2018-11-04
思路:
編碼
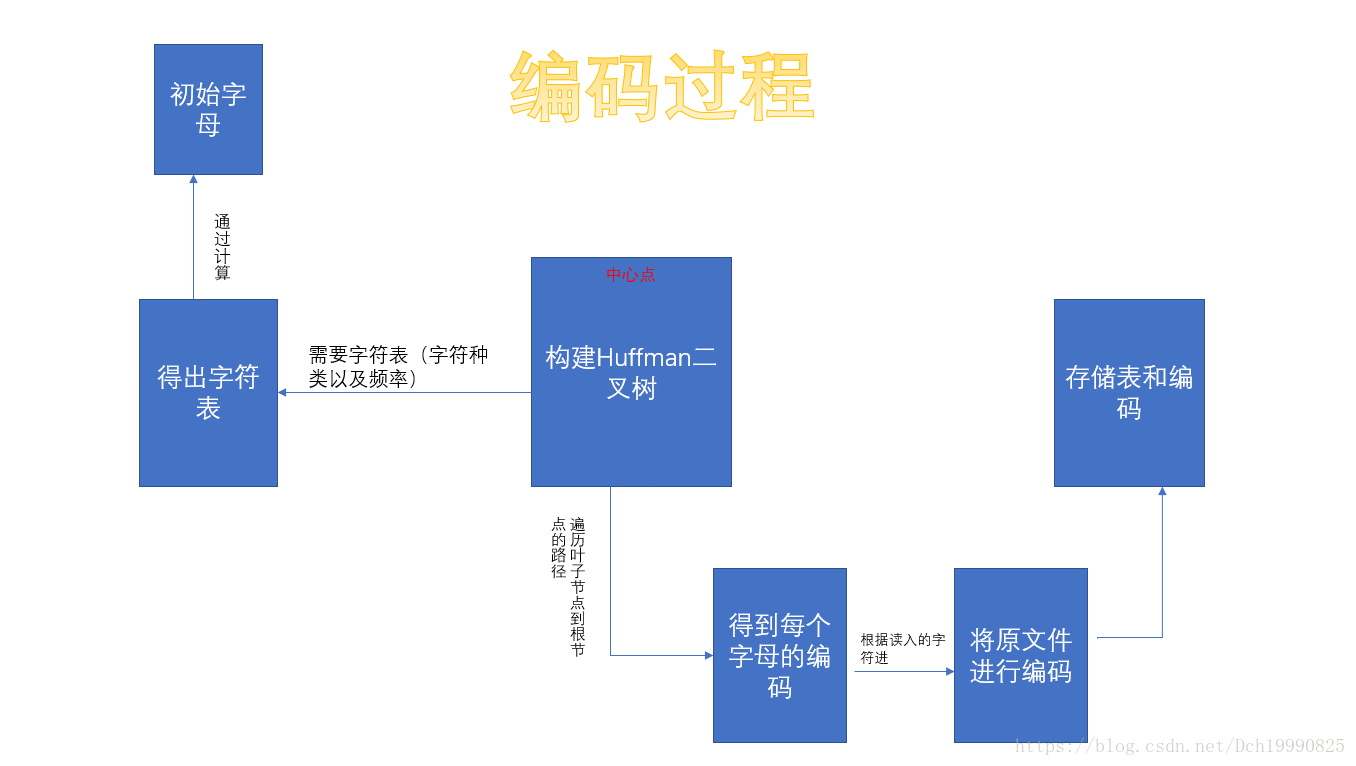
所需標頭檔案:
#ifndef HEAD1_H_INCLUDED #define HEAD1_H_INCLUDED #include<stdio.h> #include<iostream> #include<stdlib.h> #include<string.h> #include<map> #include<set> #include<fstream> using namespace std; struct HTnode { int parent,lchild,rchild; int weight,index; HTnode() { parent=lchild=rchild=-1; weight=0; index=-1; } }; bool operator <(HTnode b,HTnode a)//對節點結構體進行運算子過載 { return b.weight<a.weight; } struct _Date { char cc; int cnt; } ; bool Getbit(char *p,int k)//得到一個位元組從左到右數的第k位 { if(*p&(1<<(8-k))) return 1; return 0; } void printbit(char*p) { for(int i=1; i<=8; ++i) printf("%d",Getbit(p,i)); } void Getbitpos(int bitsize,int &sizepos,int &bitpos)//得到第幾個位元組的第幾位 { int mid=bitsize/8; if(bitsize%8) { sizepos=mid+1; bitpos=bitsize%8; return; } sizepos=mid; bitpos=8; return; } void evalubit(char *p,int k,int flag)//給以一個位元組的從左到右第k位賦0 1 { if(flag) { *p=*p|(1<<(8-k)); return; } *p=*p&(~(1<<(8-k))); } #endif // HEAD1_H_INCLUDED
編碼程式碼:(因為是雛形 所以這裡採用的是以每一個位元組當作一個字元)
檔名稱說明:
yuandoc.txt 需要壓縮的檔案
date1.txt 壓縮後的檔案
info1.txt 解壓後的檔案
/* 原理: if 前i個字元是週期性的 then i-next[i]==T[next[i]] else T[i]=i; */ /* Huffman樹 功能: 將TXT文字壓縮 1.計算字元編碼權值 2.構建編碼樹 3.將字串轉化為編碼 4.儲存赫夫曼編碼樹 5.將編碼轉化為字串 程式缺陷 : 只有一種字元編碼時 該字元的編碼為空 */ #include"head1.h" class HuffmanTree { public: int charsize;//字元種類數 int slen;//讀入的位元組數 char *read_str;//讀入的字串 _Date *dateArr;//字元表(字元種類 已經對應出現的次數) HTnode *hufArr;//赫夫曼陣列 char **charCodeArr;//每類字元對應的編碼 int Allcodesize; char *codebitArr; HuffmanTree(char *str,int info_size) { /* 需要:讀入字元,和位元組數 結果:輸出字母表dateArr,儲存讀入字元,得到字元種類數charsize, */ hufArr=NULL; charCodeArr=NULL; codebitArr=NULL; slen=info_size; read_str=new char[slen]; for(int i=0;i<slen;++i) read_str[i]=str[i]; map<char,int>mmp; map<char,int>::iterator it; for(int i=0; i<slen; ++i) { it=mmp.find(read_str[i]); if(it==mmp.end()) mmp.insert(pair<char,int>(read_str[i],1)); else it->second++; } charsize=mmp.size(); dateArr=new _Date[charsize]; int top=0; for(it=mmp.begin(); it!=mmp.end(); ++it) { dateArr[top].cc=it->first; dateArr[top++].cnt=it->second; } mmp.clear(); } void BulidTree() { /* 需要:字元表,字元個數, 輸出:哈夫曼陣列, */ hufArr=new HTnode[2*charsize-1]; multiset<HTnode>hufset; for(int i=0; i<charsize; ++i) { hufArr[i].weight=dateArr[i].cnt; hufArr[i].index=i; hufset.insert(hufArr[i]); }//前n個節點儲存樹節點兵器人加入set容器中 int top=charsize; int lc,rc; multiset<HTnode>::iterator it; while(top!=2*charsize-1) { it=hufset.begin(); lc=it->index; hufset.erase(it); it=hufset.begin(); rc=it->index; hufset.erase(it); hufArr[top].lchild=lc; hufArr[top].rchild=rc; hufArr[top].weight=hufArr[lc].weight+hufArr[rc].weight; hufArr[top].index=top; hufArr[lc].parent=top; hufArr[rc].parent=top; hufset.insert(hufArr[top]); top++; } /* 二叉樹構建完成 陣列為hufArr 根節點為2*charsize-2 對應的字元在dateArr.cc裡面 */ } void Getcharcode() { /* 需要:哈夫曼節點陣列hufArr[],字元表種類數charsize 輸出:字元對應的編碼 存到charcodeArr[][] */ charCodeArr=new char*[charsize]; char *midc=new char[charsize+1];//作為中間字串 int top,now_node,next_node; Allcodesize=0; for(int i=0; i<charsize; ++i) { top=0; now_node=i; while(hufArr[now_node].parent!=-1) { next_node=hufArr[now_node].parent; if(hufArr[next_node].lchild==now_node) midc[top++]='0'; else midc[top++]='1'; now_node=next_node; } midc[top]=0; Allcodesize+=top*dateArr[i].cnt;//計算總共需要的位元位數 charCodeArr[i]=new char[top+1]; for(int j=0; j<top; ++j) //將第i個字元對應的吧編碼儲存進去 { charCodeArr[i][j]=midc[top-1-j]; } charCodeArr[i][top]='\0'; } delete []midc; /* 得到字元對應的編碼 */ } void Getbitcode() { /* 需要:讀入的字串 read_str ,字元表,每個字元對應的編碼陣列charcodeArr[][], 輸出:編碼 */ int index;//找到字元對應的索引 int mid;//存這些二進位制數需要的位元組數 int sizepos,bitpos; mid=Allcodesize/8; if(Allcodesize%8) mid++; codebitArr=new char[mid];//申請編碼記憶體 int top=0; for(int i=0; i<slen; ++i) { for(int j=0; j<charsize; ++j) if(dateArr[j].cc==read_str[i]) { index=j; break; } int j=0; //將此字元對應的編碼儲存到codebitArr陣列中 while(charCodeArr[index][j]) { ++top; Getbitpos(top,sizepos,bitpos); if(charCodeArr[index][j]=='0') { evalubit(&codebitArr[sizepos-1],bitpos,0); } else { evalubit(&codebitArr[sizepos-1],bitpos,1); } j++; } } cout<<endl; while(top<mid*8)//不夠一個位元組的補上0補夠一個位元組 { ++top; Getbitpos(top,sizepos,bitpos); evalubit(&codebitArr[sizepos-1],bitpos,0); } /* 得到編碼陣列 codebitArr 共Allcodesize 編碼總長度 */ } void Printcharcode() { /* 輸出字元表對應的編碼 */ } void save_date() { /* 初始:字元表種類數 ,bit位的數目, 字母表, Huffman樹 ,編碼 輸出:儲存 */ int mid; mid=Allcodesize/8; if(Allcodesize%8) mid++; FILE *fp; fp=fopen("../date.txt","wb"); fwrite(&charsize,4,1,fp);//寫入 字元種類數目 fwrite(&Allcodesize,4,1,fp);//寫入 bit位數目 fwrite(&slen,4,1,fp); //寫入原來的位元組數目 char *chartable; chartable=new char[charsize]; for(int i=0; i<charsize; ++i) chartable[i]=dateArr[i].cc; fwrite(chartable,1,charsize,fp);//寫入字母表 delete []chartable; fwrite(hufArr,sizeof(HTnode),charsize*2-1,fp);//寫入Huffman 陣列 fwrite(codebitArr,1,mid,fp);//寫入 編碼 fclose(fp); } ~HuffmanTree() { delete []read_str; delete []dateArr; if(hufArr) delete []hufArr; if(codebitArr) delete []codebitArr; if(charCodeArr) { for(int i=0; i<charsize; ++i) delete []charCodeArr[i]; delete []charCodeArr; } } }; //編碼程式 int main() { char *str; int info_size; FILE *fp; fp=fopen("../yuandoc.txt","rb");//讀取需要壓縮的檔案 fseek(fp,0L,SEEK_END); info_size=ftell(fp);//計算需要壓縮檔案的位元組 fseek(fp,0L,SEEK_SET); str=new char[info_size]; fread(str,1,info_size,fp); HuffmanTree huftree(str,info_size); //讀取字串到str huftree.BulidTree(); huftree.Getcharcode(); huftree.Getbitcode(); huftree.save_date(); fclose(fp); delete []str; //over~~~~~ }
此程式碼儲存到文字時按照如下方式儲存

譯碼就比較簡單了:

程式碼:
/* 解壓程式 */ #include"head1.h" void Compress_file(FILE *fp)//對檔案進行解壓 當成解壓字元ASSIC碼並存到文本里面(二進位制儲存) { int charsize,Allcodesize,info_size; int sizepos,bitpos,now_index; char *codetable; char *codebitArr; char *InfoArr; HTnode* hufcodeArr; int mid; fread(&charsize,4,1,fp);//讀取 charsize fread(&Allcodesize,4,1,fp);//讀取 有用的編碼位數 fread(&info_size,4,1,fp);//讀取 原來的位元組數目 codetable=new char[charsize];//申請 字母表記憶體 hufcodeArr=new HTnode[2*charsize-1];//申請 hufmantree記憶體 fread(codetable,1,charsize,fp);//讀取 字母表 fread(hufcodeArr,sizeof(HTnode),charsize*2-1,fp);//讀取哈夫曼樹 mid=Allcodesize/8; if(mid%Allcodesize) mid++; codebitArr=new char[mid];//申請編碼記憶體 fread(codebitArr,1,mid,fp);//讀取編碼 int top=0; int cnt=0; now_index=2*charsize-2; InfoArr=new char[info_size]; while(top<Allcodesize) { ++top; Getbitpos(top,sizepos,bitpos); if(Getbit(&codebitArr[sizepos-1],bitpos)) { now_index=hufcodeArr[now_index].rchild; } else { now_index=hufcodeArr[now_index].lchild; } if(hufcodeArr[now_index].lchild==-1) { InfoArr[cnt++]=codetable[now_index]; // printf("now index=%d\n",now_index); now_index=2*charsize-2; // printf(" cnt=%d, char=%c,ASSIC=%d\n",cnt,InfoArr[cnt-1],(int)InfoArr[cnt-1]); } } FILE *fp2; fp2=fopen("../info.txt","wb"); // printf("infoArr=%s\n",InfoArr); fwrite(InfoArr,1,info_size,fp2); fclose(fp2); delete []codetable; delete []hufcodeArr; delete []codebitArr; delete []InfoArr; } int main() { FILE *fp; fp=fopen("../date.txt","rb"); if(fp==NULL) { printf("error!\n"); exit(1); } if(!fp) exit(1); Compress_file(fp); fclose(fp); }
缺陷:
1.只有一種字元無編碼
2.把一個位元組當作一個一種字元 壓縮力度小
後續跟更新4個位元組為以一個字元的編碼程式碼