
Zookeeper技術:分布式架構詳解、分布式技術詳解、分布式事務
1、分布式發展歷程
1.1 單點集中式
特點:App、DB、FileServer都部署在一臺機器上。並且訪問請求量較少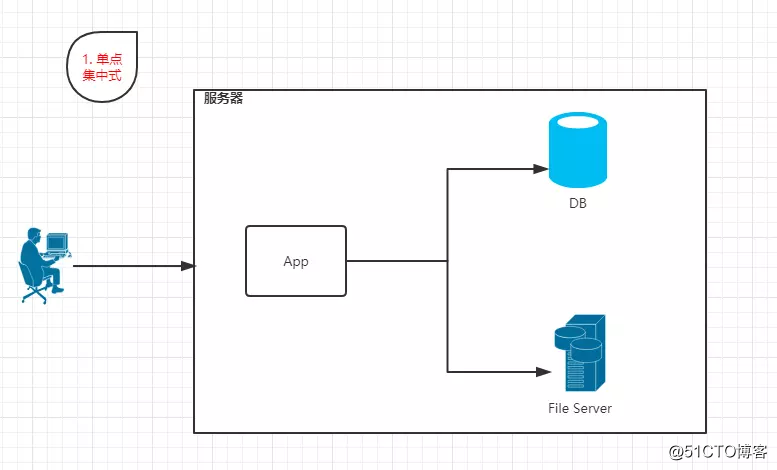
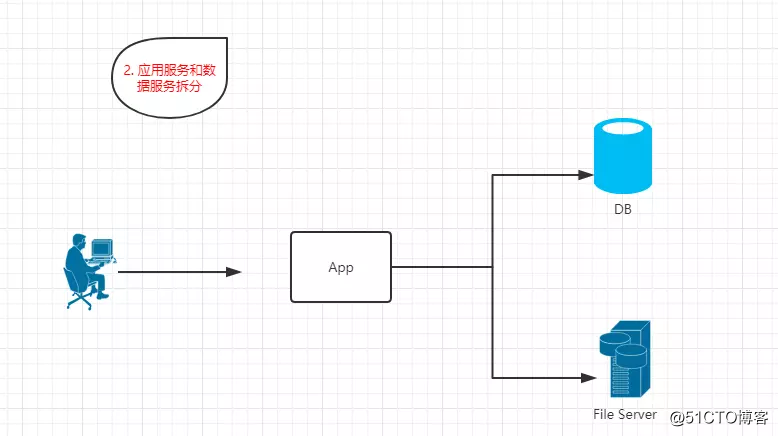
1.2? 應用服務和數據服務拆分
?特點:App、DB、FileServer分別部署在獨立服務器上。並且訪問請求量較少
1.3? 使用緩存改善性能
?特點:數據庫中頻繁訪問的數據存儲在緩存服務器中,減少數據庫的訪問次數,降低數據庫的壓力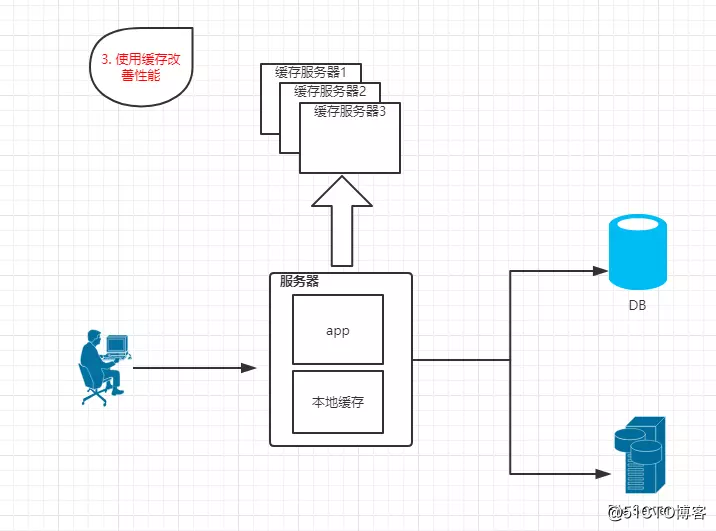
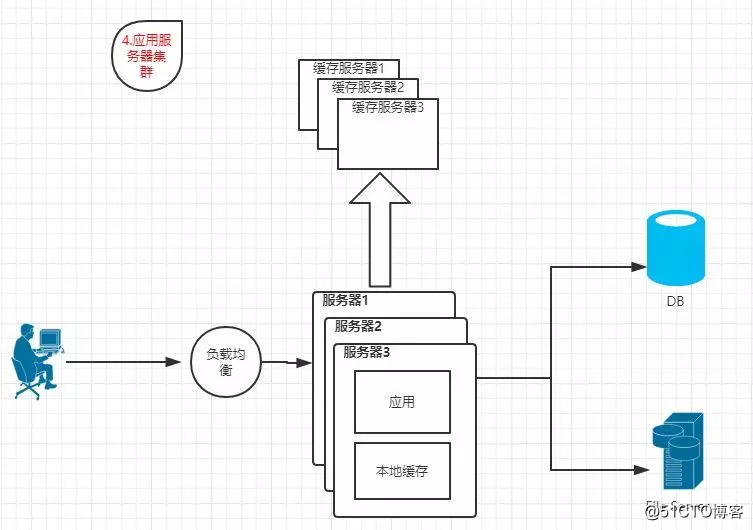
1.4 應用服務器集群
?特點:多臺應用服務器通過負載均衡同時對外提供服務,解決單臺服務器處理能力上限的問題
1.5 數據庫讀寫分離
特點:數據庫進行讀寫分離(主從)設計,解決數據庫的處理壓力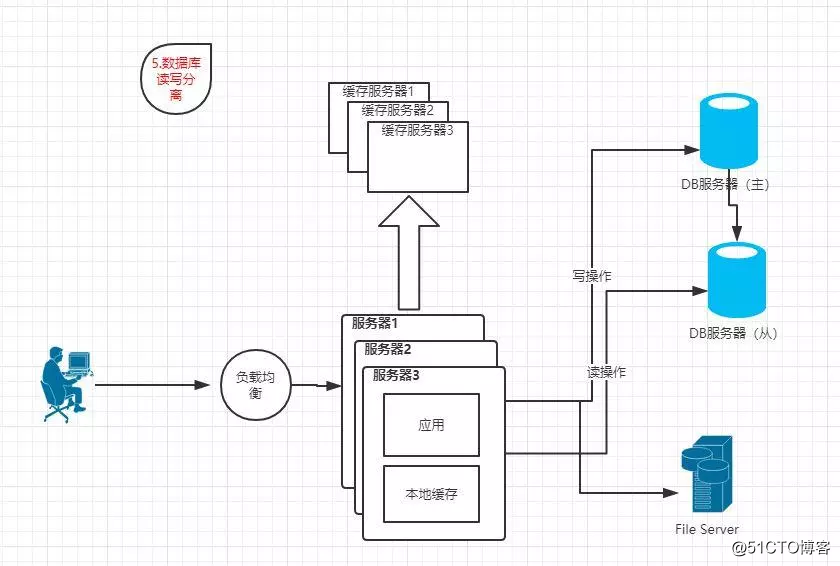
1.6 反向代理和CDN加速
?特點:采用反向代理和CDN加快系統的訪問速度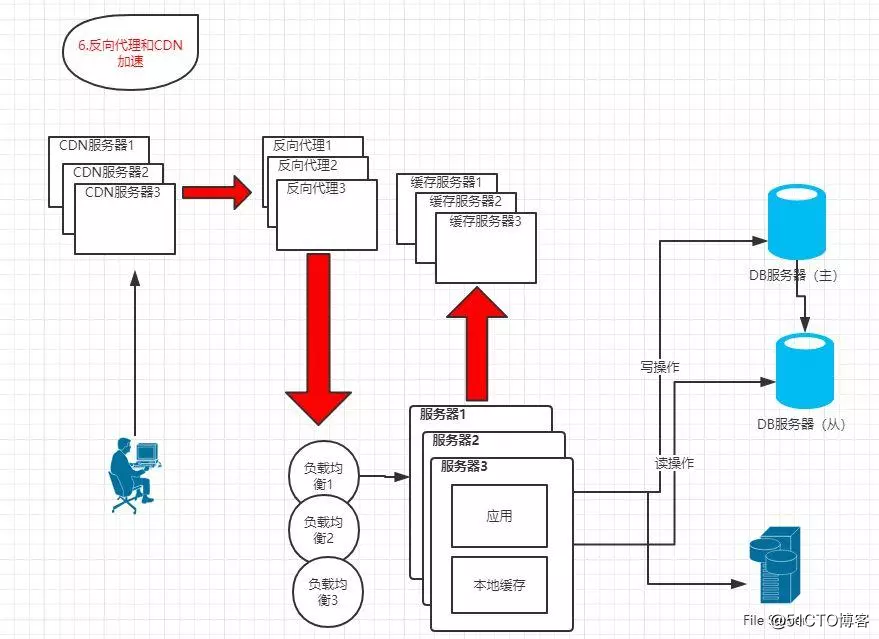
1.7 分布式文件系統和分布式數據庫
?特點:數據庫采用分布式數據庫,文件系統采用分布式文件系統
隨著業務的發展,最終數據庫讀寫分離也將無法滿足需求,需要采用分布式數據庫和分布式文件系統來支撐
分布式數據庫是數據庫拆分後的最後方法,只有在單表規模非常龐大的時候才使用,更常用的數據庫拆分手段是業務分庫,將不同業務的數據庫部署在不同的機器上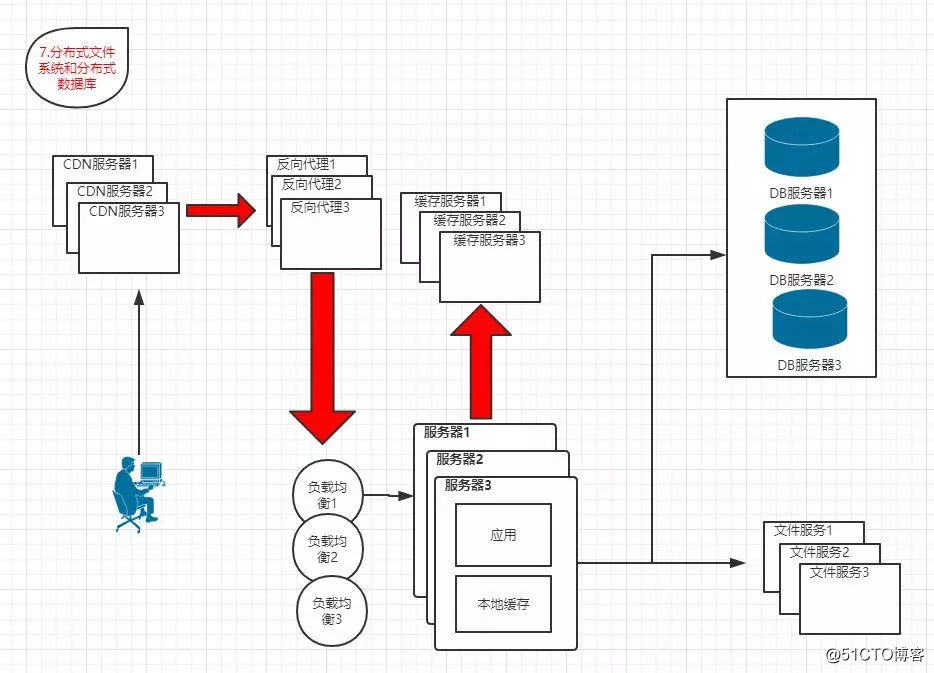
二、?分布式技術詳解
-
並發性
- 分布性
大任務拆分成多個任務部署到多臺機器上對外提供服務
- 缺乏全局時鐘 ?
時間要統一
- 對等性
一個服務部署在多臺機器上是一樣的,無任何差別
- 故障肯定會發生
?硬盤壞了 CPU燒了....
三、分布式事務
- ACID
原子性(Atomicity):一個事務(transaction)中的所有操作,要麽全部完成,要麽全部不完成,不會結束在中間某個環節。事務在執行過程中發生錯誤,會被恢復(Rollback)到事務開始前的狀態,就像這個事務從來沒有執行過一樣。
一致性(Consistency):在事務開始之前和事務結束以後,數據庫的完整性沒有被破壞。這表示寫入的資料必須完全符合所有的預設規則,這包含資料的精確度、串聯性以及後續數據庫可以自發性地完成預定的工作。
比如A有500元,B有300元,A向B轉賬100,無論怎麽樣,A和B的總和總是800元
隔離性(Isolation):數據庫允許多個並發事務同時對其數據進行讀寫和修改的能力,隔離性可以防止多個事務並發執行時由於交叉執行而導致數據的不一致。事務隔離分為不同級別,包括讀未提交(Read uncommitted)、讀提交(read committed)、可重復讀(repeatable read)和串行化(Serializable)。
持久性(Durability):事務處理結束後,對數據的修改就是永久的,即便系統故障也不會丟失。
- 2P/3P
2P= Two Phase commit ??二段提交(RDBMS(關系型數據庫管理系統)經常就是這種機制,保證強一致性)
3P= Three Phase commit ?三段提交
說明:2P/3P是為了保證事務的ACID(原子性、一致性、隔離性、持久性)
2.1 2P的兩個階段
階段1:提交事務請求(投票階段)詢問是否可以提交事務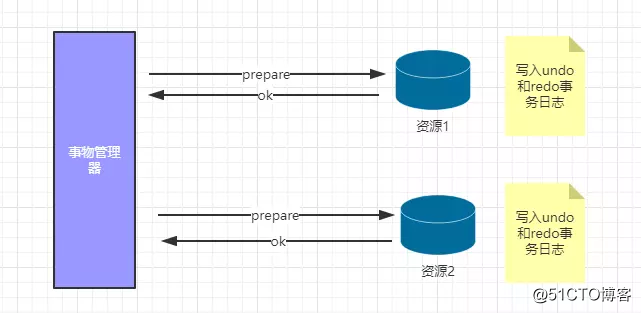
階段2:執行事務提交(commit、rollback)?真正的提交事務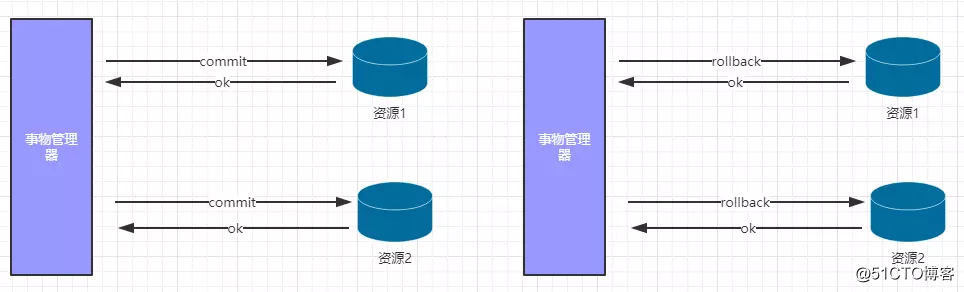
2.2 3P的三個階段
階段1:是否提交-詢問是否可以做事務提交
階段2:預先提交-預先提交事務
階段3:執行事務提交(commit、rollback)真正的提交事務
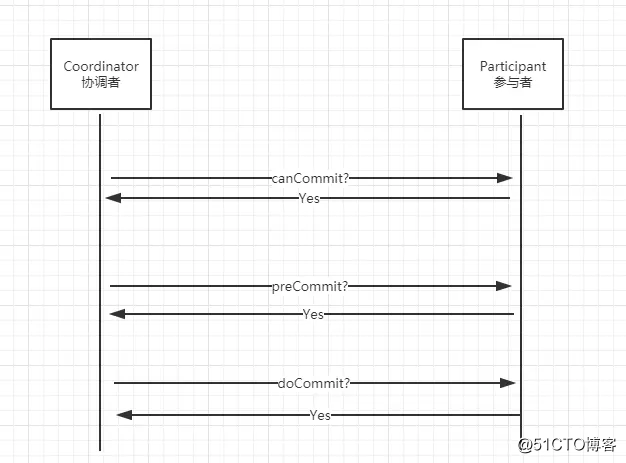
說明:3P把2P的階段一拆分成了前面兩個階段
- CAP理論
一致性(Consistency):分布式數據庫的數據保持一致
可用性(Availability):任何一個節點掛了,其他節點可以繼續對外提供服務
分區容錯性(網絡分區)Partition tolerance:一個數據庫所在的機器壞了,如硬盤壞了,數據丟失了,可以新增一臺機器,然後從其他正常的機器把備份的數據同步過來
CAP理論的特點:CAP只能滿足其中2條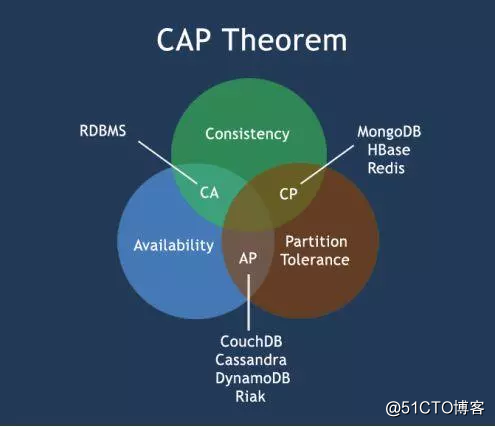
CA(放棄P):將所有的數據放在一個節點。滿足一致性、可用性。
AP(放棄C):放棄強一致性,用最終一致性來保證。
CP(放棄A):一旦系統遇見故障,受到影響的服務器需要等待一段時間,在恢復期間無法對外提供服務。
舉例說明CAP理論:
有3臺機器分別有3個數據庫分別有兩張表,數據都是一樣的
Machine1-db1-tbl_person、tbl_order
Machine2-db2-tbl_person、tbl_order
Machine3-db3-tbl_person、tbl_order
1)當向machine1的db1的表tbl_person、tbl_order插入數數據時,同時要把插入的數據同步到machine2、machine3,這就是一致性
2)當其中的一臺機器宕機了,可以繼續對外提供服務,把宕機的機器重新啟動起來可以繼續服務,這就是可用性
3)當machine1的機器壞了,數據全部丟失了,不會有任何問題,因為machine2和machine3上還有數據,重新加一臺機器machine4,把machine2和machine3其中一臺機器的備份數據同步過來就可以了,這就是分區容錯性
- BASE理論
基本可用(bascially available)、軟狀態(soft state)、最終一致性(Eventually consistent)
基本可用:在分布式系統出現故障,允許損失部分可用性(服務降級、頁面降級)
軟狀態:允許分布式系統出現中間狀態。而且中間狀態不影響系統的可用性。
1、這裏的中間狀態是指不同的data replication之間的數據更新可以出現延時的最終一致性
2、如CAP理論裏面的示例,當向machine1的db1的表tbl_person、tbl_order插入數數據時,同時要把插入的數據同步到machine2、machine3,當machine3的網絡有問題時,同步失敗,但是過一會網絡恢復了就同步成功了,這個同步失敗的狀態就稱為軟狀態,因為最終還是同步成功了。
最終一致性:data replications經過一段時間達到一致性。
- Paxos算法
5.1 介紹Paxos算法之前我們先來看一個小故事
拜占庭將軍問題
拜占庭帝國就是5~15世紀的東羅馬帝國,拜占庭即現在土耳其的伊斯坦布爾。我們可以想象,拜占庭軍隊有許多分支,駐紮在敵人城外,每一分支由各自的將軍指揮。假設有11位將軍,將軍們只能靠通訊員進行通訊。在觀察敵人以後,忠誠的將軍們必須制訂一個統一的行動計劃——進攻或者撤退。然而,這些將軍裏有叛徒,他們不希望忠誠的將軍們能達成一致,因而影響統一行動計劃的制訂與傳播。
問題是:將軍們必須有一個協議,使所有忠誠的將軍們能夠達成一致,而且少數幾個叛徒不能使忠誠的將軍們作出錯誤的計劃——使有些將軍進攻而另一些將軍撤退。
假設有9位忠誠的將軍,5位判斷進攻,4位判斷撤退,還有2個間諜惡意判斷撤退,雖然結果是錯誤的撤退,但這種情況完全是允許的。因為這11位將軍依然保持著狀態一致性。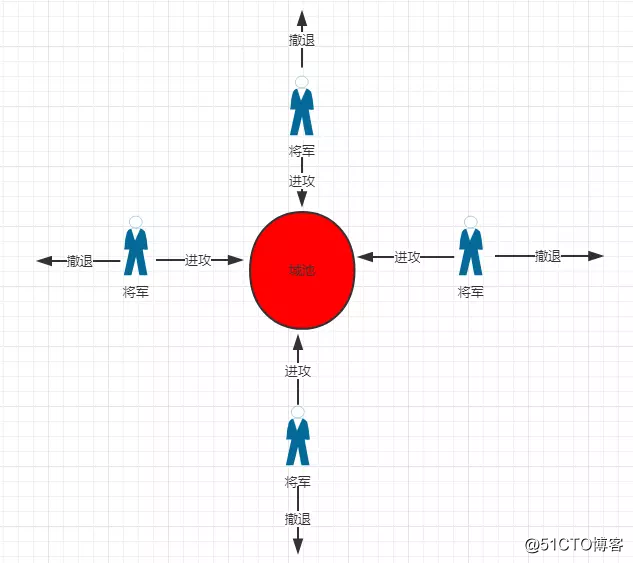
總結:
1)11位將軍進攻城池
2)同時進攻(議案、決議)、同時撤退(議案、決議)
3)不管撤退還是進攻,必須半數的將軍統一意見才可以執行
4)將軍裏面有叛徒,會幹擾決議生成
5.2 下面就來介紹一下Paxos算法
Google Chubby的作者Mike Burrows說過這個世界上只有一種一致性算法,那就是Paxos,其它的算法都是殘次品。?
Paxos:多數派決議(最終解決一致性問題)
Paxos算法有三種角色:Proposer,Acceptor,Learner
Proposer:提交者(議案提交者)
??????????提交議案(判斷是否過半),提交批準議案(判斷是否過半)
Acceptor:接收者(議案接收者)
??????????接受議案或者駁回議案,給proposer回應(promise)
Learner:學習者(打醬油的)
?????????如果議案產生,學習議案。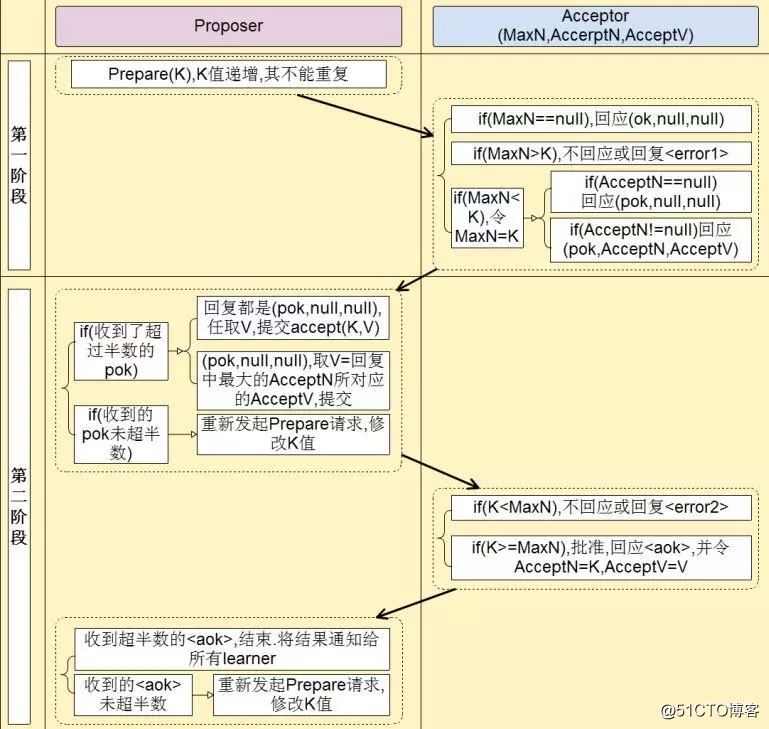
設定1:如果Acceptor沒有接受議案,那麽他必須接受第一個議案
設定2:每個議案必須有一個編號,並且編號只能增長,不能重復。越往後越大。
設定3:接受編號大的議案,如果小於之前接受議案編號,那麽不接受
設定4:議案有2種(提交的議案,批準的議案)
1)Prepare階段(議案提交)
a)Proposer希望議案V。首先發出Prepare請求至大多數Acceptor。Prepare請求內容為序列號K
b)Acceptor收到Prepare請求為編號K後,檢查自己手裏是否有處理過Prepare請求。
c)如果Acceptor沒有接受過任何Prepare請求,那麽用OK來回復Proposer,代表Acceptor必須接受收到的第一個議案(設定1)
d)否則,如果Acceptor之前接受過任何Prepare請求(如:MaxN),那麽比較議案編號,如果K<MaxN,則用reject或者error回復Proposer
e)如果K>=MaxN,那麽檢查之前是否有批準的議案,如果沒有則用OK來回復Proposer,並記錄K
f)如果K>=MaxN,那麽檢查之前是否有批準的議案,如果有則回復批準的議案編號和議案內容(如:<AcceptN, AcceptV>, AcceptN為批準的議案編號,AcceptV為批準的議案內容)
2)Accept階段(批準階段)
a)Proposer收到過半Acceptor發來的回復,回復都是OK,且沒有附帶任何批準過的議案編號和議案內容。那麽Proposer繼續提交批準請求,不過此時會連議案編號K和議案內容V一起提交(<K, V>這種數據形式)
b)Proposer收到過半Acceptor發來的回復,回復都是OK,且附帶批準過的議案編號和議案內容(<pok,議案編號,議案內容>)。那麽Proposer找到所有回復中超過半數的那個(假設為<pok,AcceptNx,AcceptVx>)作為提交批準請求(請求為<K,AcceptVx>)發送給Acceptor。
c)Proposer沒有收到過半Acceptor發來的回復,則修改議案編號K為K+1,並將編號重新發送給Acceptors(重復Prepare階段的過程)
d)Acceptor收到Proposer發來的Accept請求,如果編號K<MaxN則不回應或者reject。
e)Acceptor收到Proposer發來的Accept請求,如果編號K>=MaxN則批準該議案,並設置手裏批準的議案為<K,接受議案的編號,接受議案的內容>,回復Proposer。
f)經過一段時間Proposer對比手裏收到的Accept回復,如果超過半數,則結束流程(代表議案被批準),同時通知Leaner可以學習議案。
g) 經過一段時間Proposer對比手裏收到的Accept回復,如果未超過半數,則修改議案編號重新進入Prepare階段。
5.3 Paxos示例
示例1:先後提議的場景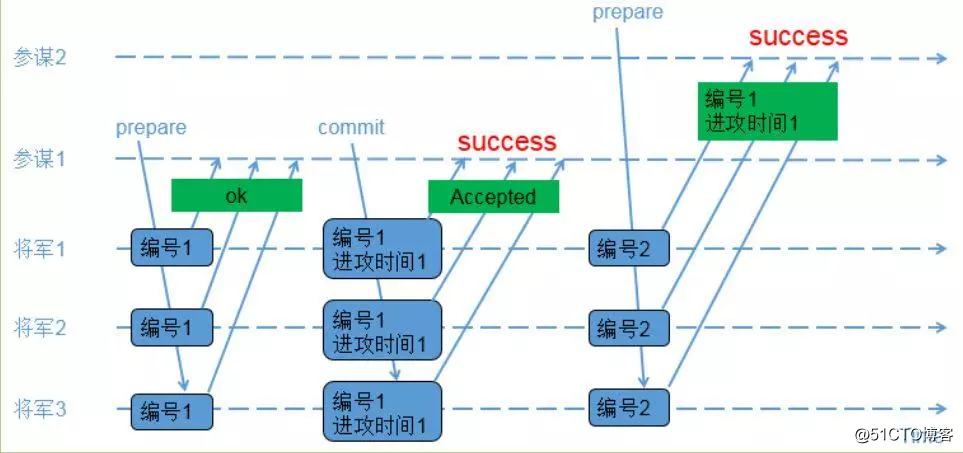
角色:
proposer:參謀1,參謀2
acceptor:將軍1,將軍2,將軍3(決策者)
1)參謀1發起提議,派通信兵帶信給3個將軍,內容為(編號1);
2)3個將軍收到參謀1的提議,由於之前還沒有保存任何編號,因此把(編號1)保存下來,避免遺忘;同時讓通信兵帶信回去,內容為(ok);
3)參謀1收到至少2個將軍的回復,再次派通信兵帶信給3個將軍,內容為(編號1,進攻時間1);
4)3個將軍收到參謀1的時間,把(編號1,進攻時間1)保存下來,避免遺忘;同時讓通信兵帶信回去,內容為(Accepted);
5)參謀1收到至少2個將軍的(Accepted)內容,確認進攻時間已經被大家接收;
6)參謀2發起提議,派通信兵帶信給3個將軍,內容為(編號2);
7)3個將軍收到參謀2的提議,由於(編號2)比(編號1)大,因此把(編號2)保存下來,避免遺忘;又由於之前已經接受參謀1的提議,因此讓通信兵帶信回去,內容為(編號1,進攻時間1);
8)參謀2收到至少2個將軍的回復,由於回復中帶來了已接受的參謀1的提議內容,參謀2因此不再提出新的進攻時間,接受參謀1提出的時間;
示例2:交叉場景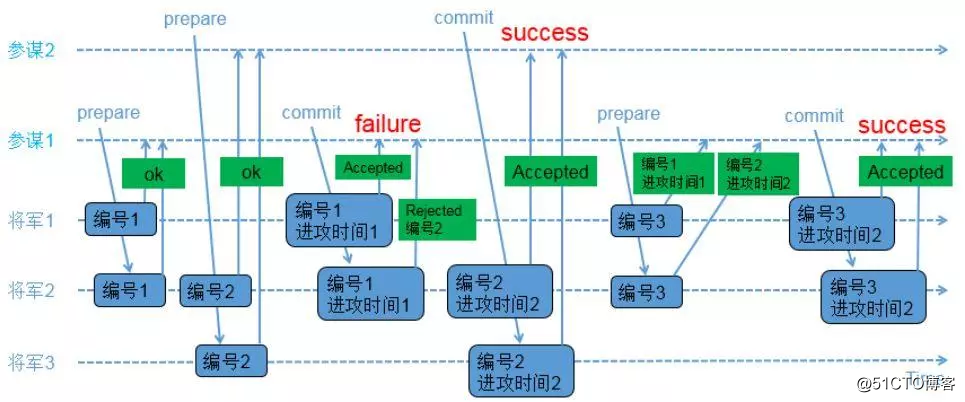
角色:
proposer:參謀1,參謀2
acceptor:將軍1,將軍2,將軍3(決策者)
1)參謀1發起提議,派通信兵帶信給3個將軍,內容為(編號1);
2)3個將軍的情況如下
a)將軍1和將軍2收到參謀1的提議,將軍1和將軍2把(編號1)記錄下來,如果有其他參謀提出更小的編號,將被拒絕;同時讓通信兵帶信回去,內容為(ok);
b)負責通知將軍3的通信兵被抓,因此將軍3沒收到參謀1的提議;
3)參謀2在同一時間也發起了提議,派通信兵帶信給3個將軍,內容為(編號2);
4)3個將軍的情況如下
a)將軍2和將軍3收到參謀2的提議,將軍2和將軍3把(編號2)記錄下來,如果有其他參謀提出更小的編號,將被拒絕;同時讓通信兵帶信回去,內容為(ok);
b)負責通知將軍1的通信兵被抓,因此將軍1沒收到參謀2的提議;
5)參謀1收到至少2個將軍的回復,再次派通信兵帶信給有答復的2個將軍,內容為(編號1,進攻時間1);
6)2個將軍的情況如下
a)將軍1收到了(編號1,進攻時間1),和自己保存的編號相同,因此把(編號1,進攻時間1)保存下來;同時讓通信兵帶信回去,內容為(Accepted);
b)將軍2收到了(編號1,進攻時間1),由於(編號1)小於已經保存的(編號2),因此讓通信兵帶信回去,內容為(Rejected,編號2);
7)參謀2收到至少2個將軍的回復,再次派通信兵帶信給有答復的2個將軍,內容為(編號2,進攻時間2);
8)將軍2和將軍3收到了(編號2,進攻時間2),和自己保存的編號相同,因此把(編號2,進攻時間2)保存下來,同時讓通信兵帶信回去,內容為(Accepted);
9)參謀2收到至少2個將軍的(Accepted)內容,確認進攻時間已經被多數派接受;
10)參謀1只收到了1個將軍的(Accepted)內容,同時收到一個(Rejected,編號2);參謀1重新發起提議,派通信兵帶信給3個將軍,內容為(編號3);
11)3個將軍的情況如下
a)將軍1收到參謀1的提議,由於(編號3)大於之前保存的(編號1),因此把(編號3)保存下來;由於將軍1已經接受參謀1前一次的提議,因此讓通信兵帶信回去,內容為(編號1,進攻時間1);
b)將軍2收到參謀1的提議,由於(編號3)大於之前保存的(編號2),因此把(編號3)保存下來;由於將軍2已經接受參謀2的提議,因此讓通信兵帶信回去,內容為(編號2,進攻時間2);
c)負責通知將軍3的通信兵被抓,因此將軍3沒收到參謀1的提議;
12)參謀1收到了至少2個將軍的回復,比較兩個回復的編號大小,選擇大編號對應的進攻時間作為最新的提議;參謀1再次派通信兵帶信給有答復的2個將軍,內容為(編號3,進攻時間2);
13)將軍1和將軍2收到了(編號3,進攻時間2),和自己保存的編號相同,因此保存(編號3,進攻時間2),同時讓通信兵帶信回去,內容為(Accepted);
14)參謀1收到了至少2個將軍的(accepted)內容,確認進攻時間已經被多數派接受。
四. Zookeeper ZAB協議
Zookeeper Automic Broadcast(ZAB),即Zookeeper原子性廣播,是Paxos經典實現
術語:
quorum:集群過半數的集合
- ZAB(zookeeper)中節點分四種狀態
looking:選舉Leader的狀態(崩潰恢復狀態下)
following:跟隨者(follower)的狀態,服從Leader命令
leading:當前節點是Leader,負責協調工作。
observing:observer(觀察者),不參與選舉,只讀節點。
2.?ZAB中的兩個模式(ZK是如何進行選舉的)
崩潰恢復、消息廣播
1)崩潰恢復
leader掛了,需要選舉新的leader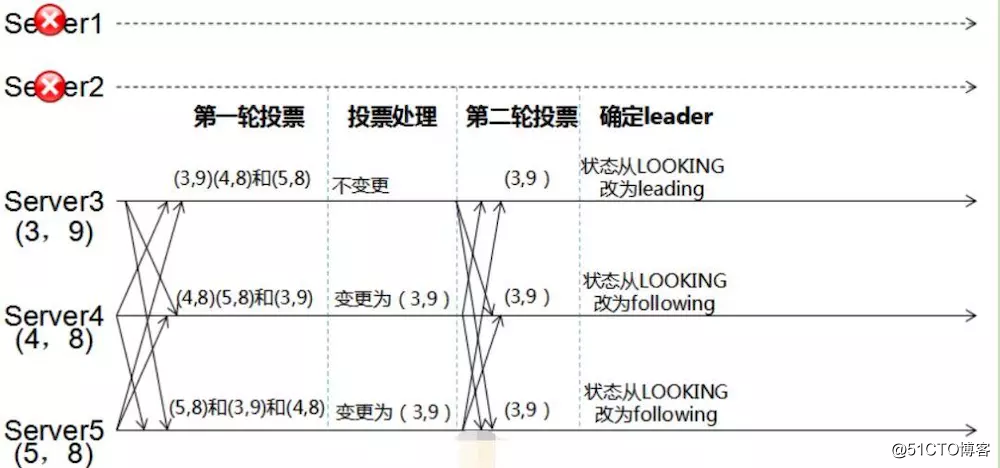
a.每個server都有一張選票,如(3,9),選票投自己。
b.每個server投完自己後,再分別投給其他還可用的服務器。如把Server3的(3,9)分別投給Server4和Server5,一次類推
c.比較投票,比較邏輯:優先比較Zxid,Zxid相同時才比較myid。比較Zxid時,大的做leader;比較myid時,小的做leader
d.改變服務器狀態(崩潰恢復->數據同步,或者崩潰恢復->消息廣播)
相關概念補充說明:
epoch周期值
acceptedEpoch(比喻:年號):follower已經接受leader更改年號的(newepoch)提議。
currentEpoch(比喻:當前的年號):當前的年號
lastZxid:history中最近接收到的提議zxid(最大的值)
history:當前節點接受到事務提議的log
Zxid數據結構說明:
cZxid = 0x10000001b
64位的數據結構
高32位:10000
Leader的周期編號+myid的組合
低32位:001b
事務的自增序列(單調遞增的序列)只要客戶端有請求,就+1
當產生新Leader的時候,就從這個Leader服務器上取出本地log中最大事務Zxid,從裏面讀出epoch+1,作為一個新epoch,並將低32位置0(保證id絕對自增)
2)消息廣播(類似2P提交)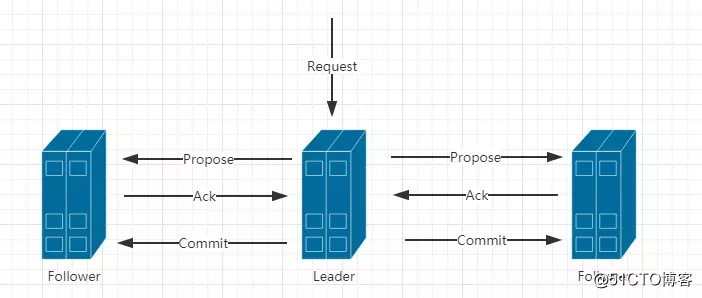
a.Leader接受請求後,將這個請求賦予全局的唯一64位自增Id(zxid)。
b.將zxid作為議案發給所有follower。
c.所有的follower接受到議案後,想將議案寫入硬盤後,馬上回復Leader一個ACK(OK)。
d.當Leader接受到合法數量(過半)Acks,Leader給所有follower發送commit命令。
e.follower執行commit命令。
註意:到了這個階段,ZK集群才正式對外提供服務,並且Leader可以進行消息廣播,如果有新節點加入,還需要進行同步。
3)數據同步
a.取出Leader最大lastZxid(從本地log日誌來)
b.找到對應zxid的數據,進行同步(數據同步過程保證所有follower一致)
c.只有滿足quorum同步完成,準Leader才能成為真正的Leader
Zookeeper技術:分布式架構詳解、分布式技術詳解、分布式事務