
塊裝置驅動之二
阿新 • • 發佈:2018-11-05
一、將塊裝置新增到系統
register_blkdev並沒有真正將裝置新增到系統中,想要將裝置新增到系統中,需要使用如下API:void blk_register_region(dev_t devt, unsigned long range, struct module *module,
struct kobject *(*probe)(dev_t, int *, void *),
int (*lock)(dev_t, void *), void *data)1.1 新增磁碟和分割槽到系統中
void add_disk(struct gendisk *disk);
它完成的工作主要包括:
- 根據磁碟的主次裝置號資訊為磁碟分配裝置號
- 呼叫disk_alloc_events初始化磁碟的事件(alloc|add|del|release)處理機制。在最開始磁碟事件會被設定為被阻塞的。
- 呼叫bdi_register_dev將磁碟註冊到bdi
- 呼叫blk_register_region將磁碟新增到bdev_map中
- 呼叫register_disk將磁碟新增到系統中。主要完成
- 將主裝置的分割槽(第0個分割槽)資訊標記設定為分割槽無效
- 呼叫device_add將裝置新增到系統中
- 在sys檔案系統中為裝置及其屬性建立目錄及檔案
- 發出裝置新增到系統的uevent事件(如果能獲取分割槽的資訊,則也為分割槽傳送uevent事件)。
- 呼叫blk_register_queue註冊磁碟的請求佇列。主要是為佇列和佇列的排程器在裝置的sys檔案系統目錄中建立相應的sys目錄/檔案,並且發出uevent事件。
- 呼叫__disk_unblock_events完成
- 在/sys檔案系統的裝置目錄下建立磁碟的事件屬性檔案
- 將磁碟事件新增到全域性連結串列disk_events中
- 解除對磁碟事件的阻塞。
當掃描到一個分割槽時,需要將它新增到磁碟中,這是通過以下API實現的:
struct hd_struct *add_partition(struct gendisk *disk, int partno,
sector_t start, sector_t len, int flags,
struct partition_meta_info *info);- disk:分割槽所屬的磁碟
- partno:分割槽在磁碟的分割槽號
- start:起始扇區號
- len:該分割槽包括多少個扇區
- flags:該扇區的標誌
- info:該分割槽的partition_meta_info資訊
- 擴充套件磁碟的分割槽表
- 分配分割槽資料結構並進行初始化
- 呼叫device_initialize初始化分割槽的裝置資料結構
- 設定分割槽的裝置號
- 呼叫device_add將分割槽新增到系統中
- 建立分割槽裝置相關的sys檔案系統檔案
- 傳送新增分割槽的uevent事件
- 初始化分割槽的引用計數
二、塊裝置操作
2.1 開啟塊裝置
在所有的檔案系統的實現中,在獲取檔案的inode時,對於不是常規檔案、目錄檔案、連線檔案的特殊檔案都會呼叫init_special_inode,該函式的程式碼在學習字元裝置時已經貼出來過,對於塊裝置檔案,該函式會將inode的檔案操作函式結構設定為def_blk_fops,其中的開啟檔案函式為blkdev_open。其原型為:int blkdev_open(struct inode * inode, struct file * filp);- 呼叫bd_acquire獲取塊裝置檔案的block_device結構。該函式會呼叫bdget嘗試從bdev檔案系統中查詢裝置檔案對應的inode,如果有就直接返回,如果沒有會分配一個新的inode並且初始化該inode再返回。裝置檔案的inode會被新增到block_device的bd_inodes連結串列中。塊裝置對應的block_device也會在這一步被新增到全域性的all_bdevs中。
- 設定file結構的f_mapping為bdev->bd_inode->i_mapping。bdev->bd_inode在inode的建立和初始化中北初始化,具體的函式為alloc_inode和bdget。其中的address_space_operations被設定為def_blk_aops,這是後續要用到的函式,這是和裝置互動的介面。
- 呼叫blkdev_get。該函式最主要的工作時完成塊裝置的開啟動作,同時根據傳入的模式還可能宣告裝置的持有者。
- 呼叫get_gendisk獲取塊裝置所對應的通用磁碟結構,這裡可能需要查詢bdev_map資料庫。
- 阻塞磁碟的事件處理
- 如果是第一次開啟該塊裝置,則
- 填充塊裝置資料結構的bd_disk,bd_queue,bd_contains(它會設定為自身)
- 如果是主裝置(即不是分割槽),則
- 設定塊裝置資料結構的bd_part
- 如果提供了disk->fops->open,則呼叫它
- 如果分割槽無效,則呼叫rescan_partitions重新掃描分割槽
- 如果開啟裝置時返回了ENOMEDIUM錯誤,則呼叫invalidate_partitions將所有分割槽設定為無效
- 否則,如果是分割槽裝置,則
- 獲取主裝置的塊裝置資料結構
- 遞迴呼叫__blkdev_get,但是這次傳入的是主裝置的塊裝置資料結構。本次呼叫會走第一次開啟裝置並且是主裝置的分支,由於是第一次開啟,因而分割槽資訊應該是無效的,這就會走到重新掃描分割槽的分支。
- 設定塊裝置資料結構的bd_contains(它被設定為主裝置的block_device),bd_part
- 呼叫bd_set_size設定分割槽的大小資訊
- 否則如果不是第一次開啟裝置,則
- 如果是主裝置(這裡是通過bdev->bd_contains == bdev判斷的,因為根據該函式的前邊流程,只有主裝置的這個條件才能成立),則
- 如果提供了disk->fops->open,則呼叫它
- 如果分割槽無效,則呼叫rescan_partitions重新掃描分割槽
- 如果開啟裝置時返回了ENOMEDIUM錯誤,則呼叫invalidate_partitions將所有分割槽設定為無效
- 如果是主裝置(這裡是通過bdev->bd_contains == bdev判斷的,因為根據該函式的前邊流程,只有主裝置的這個條件才能成立),則
- 增加裝置的開啟計數
- 解除對裝置事件的阻塞
2.2 讀寫操作
在開啟塊裝置檔案後,塊裝置檔案的操作函式集也被設定為def_blk_fops,隨後即可用其中的函式進行讀寫。其讀函式為do_sync_read,寫函式為do_sync_write,但是它們最終分別呼叫generic_file_aio_read和blkdev_aio_write來完成實際的讀寫操作。generic_file_aio_read的原型為:
ssize_t generic_file_aio_read(struct kiocb *iocb, const struct iovec *iov, unsigned long nr_segs, loff_t pos);- iocb:核心I/O控制塊
- iov:I/O請求向量
- nr_segs:I/O請求向量中有多少個請求
- pos:當前檔案位置
- 如果是直接IO,則呼叫filp->f_mapping->a_ops->direct_IO進行直接IO。在open時已經將filp->f_mapping->a_ops設定def_blk_aops了。
- 對於請求向量中的每一個請求,建立一個read_descriptor_t並呼叫do_generic_file_read進行處理
ssize_t blkdev_aio_write(struct kiocb *iocb, const struct iovec *iov, unsigned long nr_segs, loff_t pos);- 呼叫__generic_file_aio_write進行處理。該函式也會分別對待直接IO和常規的寫。流程和讀類似。
無論是讀寫都是和緩衝區互動,緩衝區位於檔案資料結構的struct address_space型別的變數f_mapping中,並以radix樹的形式被管理。核心在合適的時機會向裝置發起實際的IO操作,這是通過檔案資料結構的struct address_space型別的成員變數f_mapping中的address_space_operations型別的成員中的函式來實現的,在開啟塊裝置檔案時,該成員被設定為了def_blk_aops。對於讀會呼叫該地址空間操作集的readpage(對於塊裝置readpage成員函式為blkdev_readpage)成員函式或者其它讀成員函式,對於寫會呼叫該地址空間操作集的writepage(對於塊裝置為blkdev_writepage)成員函式或者其它相關成員函式函式。在def_blk_aops提供的這些函式中會將讀寫轉變成IO請求提交給裝置,到了此時才真正是要和裝置進行資料交換。
因此對於塊裝置來說,使用者是和緩衝區互動(直接IO除外),而核心負責在合適的時機完成緩衝區和裝置之間的互動。操作緩衝區的函式,緩衝區本身,以及緩衝區與裝置之間的互動方式都儲存在file結構中。
2.3 請求結構
當核心通過address_space_operations中的成員函式向裝置發起讀寫操作時,讀寫操作都會被轉變成一個對塊裝置的IO請求提交給裝置。核心使用資料結構struct bio來表示一個對塊裝置的IO,其定義如下:struct bio {
sector_t bi_sector; /* device address in 512 byte sectors */
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev;
unsigned long bi_flags; /* status, command, etc */
unsigned long bi_rw; /* bottom bits READ/WRITE,
* top bits priority
*/
unsigned short bi_vcnt; /* how many bio_vec's */
unsigned short bi_idx; /* current index into bvl_vec */
/* Number of segments in this BIO after
* physical address coalescing is performed.
*/
unsigned int bi_phys_segments;
unsigned int bi_size; /* residual I/O count */
/*
* To keep track of the max segment size, we account for the
* sizes of the first and last mergeable segments in this bio.
*/
unsigned int bi_seg_front_size;
unsigned int bi_seg_back_size;
unsigned int bi_max_vecs; /* max bvl_vecs we can hold */
atomic_t bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
bio_end_io_t *bi_end_io;
void *bi_private;
#if defined(CONFIG_BLK_DEV_INTEGRITY)
struct bio_integrity_payload *bi_integrity; /* data integrity */
#endif
bio_destructor_t *bi_destructor; /* destructor */
/*
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
*/
struct bio_vec bi_inline_vecs[0];
};- bi_sector:傳輸開始的扇區號
- bi_next:將與一個請求相關的bio連線到同一個連結串列中
- bi_bdev:與請求相關聯的裝置的資料結構
- bi_phys_segments:在經過合併之後,該BIO所對應的的段數目
- bi_size:該BIO涉及到的資料的長度
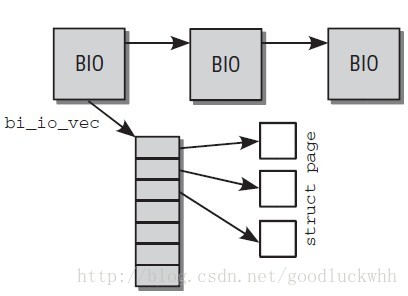
- bi_io_vec:指向了包含了實際的IO資料結構的陣列。
- bi_end_io:當IO完成時,將被呼叫用於完成此次IO
- bi_destructor:解構函式,當從記憶體刪除一個BIO結構時被呼叫
bi_io_vec的每個陣列項都指向一個記憶體頁,這個記憶體頁用於從裝置讀取資料或者向裝置傳輸資料。這些記憶體頁可以是連續的也可以不是連續的。其結構如圖所示:
BIO是核心用於表示一個IO請求的結構,它會被提交給裝置,當需要和裝置互動時,核心會先準備BIO結構,然後通過目標裝置的請求佇列上的make_request_fn函式將BIO轉變成一個請求,核心使用資料結構struct request來表示一個對塊裝置的請求,其資料結構定義如下:
struct request {
struct list_head queuelist;
struct call_single_data csd;
struct request_queue *q;
unsigned int cmd_flags;
enum rq_cmd_type_bits cmd_type;
unsigned long atomic_flags;
int cpu;
/* the following two fields are internal, NEVER access directly */
unsigned int __data_len; /* total data len */
sector_t __sector; /* sector cursor */
struct bio *bio;
struct bio *biotail;
struct hlist_node hash; /* merge hash */
/*
* The rb_node is only used inside the io scheduler, requests
* are pruned when moved to the dispatch queue. So let the
* completion_data share space with the rb_node.
*/
union {
struct rb_node rb_node; /* sort/lookup */
void *completion_data;
};
/*
* Three pointers are available for the IO schedulers, if they need
* more they have to dynamically allocate it. Flush requests are
* never put on the IO scheduler. So let the flush fields share
* space with the elevator data.
*/
union {
struct {
struct io_cq *icq;
void *priv[2];
} elv;
struct {
unsigned int seq;
struct list_head list;
rq_end_io_fn *saved_end_io;
} flush;
};
struct gendisk *rq_disk;
struct hd_struct *part;
unsigned long start_time;
#ifdef CONFIG_BLK_CGROUP
unsigned long long start_time_ns;
unsigned long long io_start_time_ns; /* when passed to hardware */
#endif
/* Number of scatter-gather DMA addr+len pairs after
* physical address coalescing is performed.
*/
unsigned short nr_phys_segments;
#if defined(CONFIG_BLK_DEV_INTEGRITY)
unsigned short nr_integrity_segments;
#endif
unsigned short ioprio;
int ref_count;
void *special; /* opaque pointer available for LLD use */
char *buffer; /* kaddr of the current segment if available */
int tag;
int errors;
/*
* when request is used as a packet command carrier
*/
unsigned char __cmd[BLK_MAX_CDB];
unsigned char *cmd;
unsigned short cmd_len;
unsigned int extra_len; /* length of alignment and padding */
unsigned int sense_len;
unsigned int resid_len; /* residual count */
void *sense;
unsigned long deadline;
struct list_head timeout_list;
unsigned int timeout;
int retries;
/*
* completion callback.
*/
rq_end_io_fn *end_io;
void *end_io_data;
/* for bidi */
struct request *next_rq;
};- queuelist:用於將請求連線到請求佇列上
- q:請求所屬的請求佇列
- cmd_flags:請求的標誌
- cmd_type:請求的型別
- bio:該請求的多個bio中當前正被處理的bio
- biotail:該請求的最後一個bio。一個請求上的所有BIO會儲存在一個連結串列中。
- __data_len:請求所涉及到的資料的總長度
- __sector:扇區遊標
- elv:IO排程器相關資訊。
- rq_disk:請求對應的磁碟
- part:請求所對應的磁碟分割槽
- end_io:該請求被完成時被呼叫,用於完成該請求
- end_io_data:回撥end_io時的引數
請求所支援的標誌及其含義如下:
enum rq_flag_bits {
/* common flags */
__REQ_WRITE, /* not set, read. set, write */
__REQ_FAILFAST_DEV, /* no driver retries of device errors */
__REQ_FAILFAST_TRANSPORT, /* no driver retries of transport errors */
__REQ_FAILFAST_DRIVER, /* no driver retries of driver errors */
__REQ_SYNC, /* request is sync (sync write or read) */
__REQ_META, /* metadata io request */
__REQ_PRIO, /* boost priority in cfq */
__REQ_DISCARD, /* request to discard sectors */
__REQ_SECURE, /* secure discard (used with __REQ_DISCARD) */
__REQ_NOIDLE, /* don't anticipate more IO after this one */
__REQ_FUA, /* forced unit access */
__REQ_FLUSH, /* request for cache flush */
/* bio only flags */
__REQ_RAHEAD, /* read ahead, can fail anytime */
__REQ_THROTTLED, /* This bio has already been subjected to
* throttling rules. Don't do it again. */
/* request only flags */
__REQ_SORTED, /* elevator knows about this request */
__REQ_SOFTBARRIER, /* may not be passed by ioscheduler */
__REQ_NOMERGE, /* don't touch this for merging */
__REQ_STARTED, /* drive already may have started this one */
__REQ_DONTPREP, /* don't call prep for this one */
__REQ_QUEUED, /* uses queueing */
__REQ_ELVPRIV, /* elevator private data attached */
__REQ_FAILED, /* set if the request failed */
__REQ_QUIET, /* don't worry about errors */
__REQ_PREEMPT, /* set for "ide_preempt" requests */
__REQ_ALLOCED, /* request came from our alloc pool */
__REQ_COPY_USER, /* contains copies of user pages */
__REQ_FLUSH_SEQ, /* request for flush sequence */
__REQ_IO_STAT, /* account I/O stat */
__REQ_MIXED_MERGE, /* merge of different types, fail separately */
__REQ_NR_BITS, /* stops here */
};enum rq_cmd_type_bits {
REQ_TYPE_FS = 1, /* fs request */
REQ_TYPE_BLOCK_PC, /* scsi command */
REQ_TYPE_SENSE, /* sense request */
REQ_TYPE_PM_SUSPEND, /* suspend request */
REQ_TYPE_PM_RESUME, /* resume request */
REQ_TYPE_PM_SHUTDOWN, /* shutdown request */
REQ_TYPE_SPECIAL, /* driver defined type */
/*
* for ATA/ATAPI devices. this really doesn't belong here, ide should
* use REQ_TYPE_SPECIAL and use rq->cmd[0] with the range of driver
* private REQ_LB opcodes to differentiate what type of request this is
*/
REQ_TYPE_ATA_TASKFILE,
REQ_TYPE_ATA_PC,
};2.4 提交請求
當核心需要和裝置進行互動時,它都會首先準備相關的bio,然後呼叫submit_bio將bio提交給裝置。該函式最終會呼叫裝置相關連的請求佇列上的make_request_fn函式將BIO轉變成一個請求,其處理邏輯很簡單:- 更新統計資訊
- 呼叫generic_make_request提交bio
- 做合法性檢查
- 如果current->bio_list不為NULL,則將新的bio新增到current->bio_list上並返回
- 將current->bio_list 初始化為 &bio_list_on_stack
- 獲取所請求裝置的請求佇列
- 呼叫請求佇列上的make_request_fn產生一個請求
- 如果current->bio_list不為空,就回到第四步
- 將current->bio_list設定為NULL
如果沒有修改過佇列的make_request_fn,則它使用核心提供的預設版本blk_queue_bio。
blk_queue_bio的大致處理流程:
- 呼叫blk_queue_bounce進行一些特殊處理(如果底層驅動表示它想要將在某個限制之上的頁地址回彈到低地址)
- 呼叫attempt_plug_merge嘗試將新的請求同已經被plugged的請求進行合併,已經被plugged的請求會被儲存在current->plug連結串列中
- 呼叫elv_merge判斷新的bio是否可以同請求佇列上已經存在的請求的bio進行合併,如果可以合併,就進行合併。這裡的是否可以合併以及如何合併都取決於所採用的IO排程演算法。
- 走到這一步就說明無法進行合併,開始建立一個新的請求,呼叫get_request_wait來獲取一個新的請求結構
- 呼叫init_request_from_bio來使用bio中的資料來初始化這個新的請求。
- 如果current->plug不空,則表示當前佇列是plug的,如果該連結串列上已經有足夠數目的請求,則呼叫blk_flush_plug_list進行處理(該函式會呼叫__elv_add_request將 請求新增到請求佇列,還可能呼叫queue_unplugged進行實際的請求處理),最後會將新的請求新增到current->plug上並更新統計資訊。
- 如果current->plug為空,則呼叫__blk_run_queue直接處理請求,這會呼叫請求佇列上的request_fn,也就是要求驅動必須提供的那個函式來進行請求的處理。
到了這一步,IO的讀寫已經被提交給了硬體,由驅動所提供的request_fn進行處理。