
記一次資料庫分表的初體驗!
業務前景
由於小編所在的公司是傳統型公司,而業務對接的確實像螞蟻貨運險這樣的大業務,從2017年中旬對接到公司的業務資料量大約一天150W左右資料,而去年的雙十一最高峰值則達到2000W一天的資料量!公司所入的資料量全部存在10多張不同業務的表中,而中途資料庫已經告警過幾次,顯然這樣的架構是不符合現在的交易規模的。。。預計今年雙十一的資料量會暴增2倍,也就是4000W左右一天。而為了提前預防這樣的爆表措施,老大提出了一次分表的優化!我一聽,當時激動的心情就像這樣:

優化方案
所以呢,有了需求就是幹!優化方案如下:
在不影響原來的10+張表相對應的業務邏輯基礎上,將其揉合成一張表,其中這張表所包含的欄位是10+張表所重要
重點實現思路
本次優化採用的是水平分表,水平分表的含義:分表之後的所有表結構都是相同的。
將上述Ant表分為每個季度16張表,也就是一共64張表,採用對貨運險中的保單號值進行hash計算,經算出來的值在進行相應的位運算,最終算出每筆交易落在哪個季度的哪個表中。
表名設定:
- 一年有四季度,故採用計算機中常用的索引表達,0 - 3來表示4個季度,0代表第一季度,1代表第二季度,2代表第三季度,3代表第四季度。
- 合成後的一張表對其進行拆分成16張表,同樣採用計算機中常用的索引表達,0 - 15,來表示16張表的索引值,比如0 代表分割後的第一張表,15代表分割後的第16張表。
有了以上兩個邏輯,可以得出的表名設定:Ant_0_0,代表第一季度的第一張表,Ant_1_2代表第二季度的第三張表,Ant_2_0代表第三季度的第一張表。。。以此類推。。。
實際上,此專案業務邏輯分為了兩部分,一部分是入庫邏輯,還有一部分是查詢邏輯。入庫邏輯部分採用python語言進行編寫(指令碼語言的好處:與螞蟻對接後直接讀取檔案進行sql拼接入庫,入庫週期較短,節省流程的耗時);查詢部分是鑲嵌在web專案中的,所以是用java語言進行實現的。有了思路,一切都是浮雲了好吧~一個字幹!

部分重點程式碼實現
下面分別給出兩部分重點的程式碼實現思路。
python部分:
- 計算出對應的16張表所屬欄位:

- 獲取當前季度:
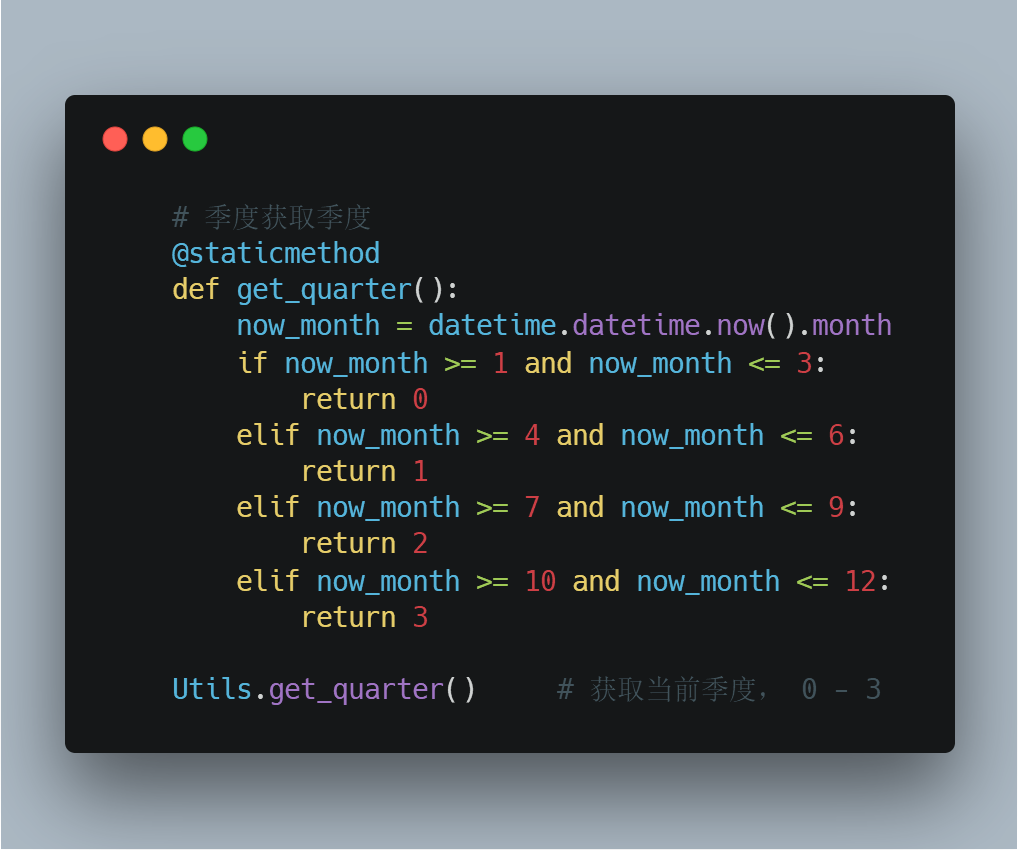

java部分:
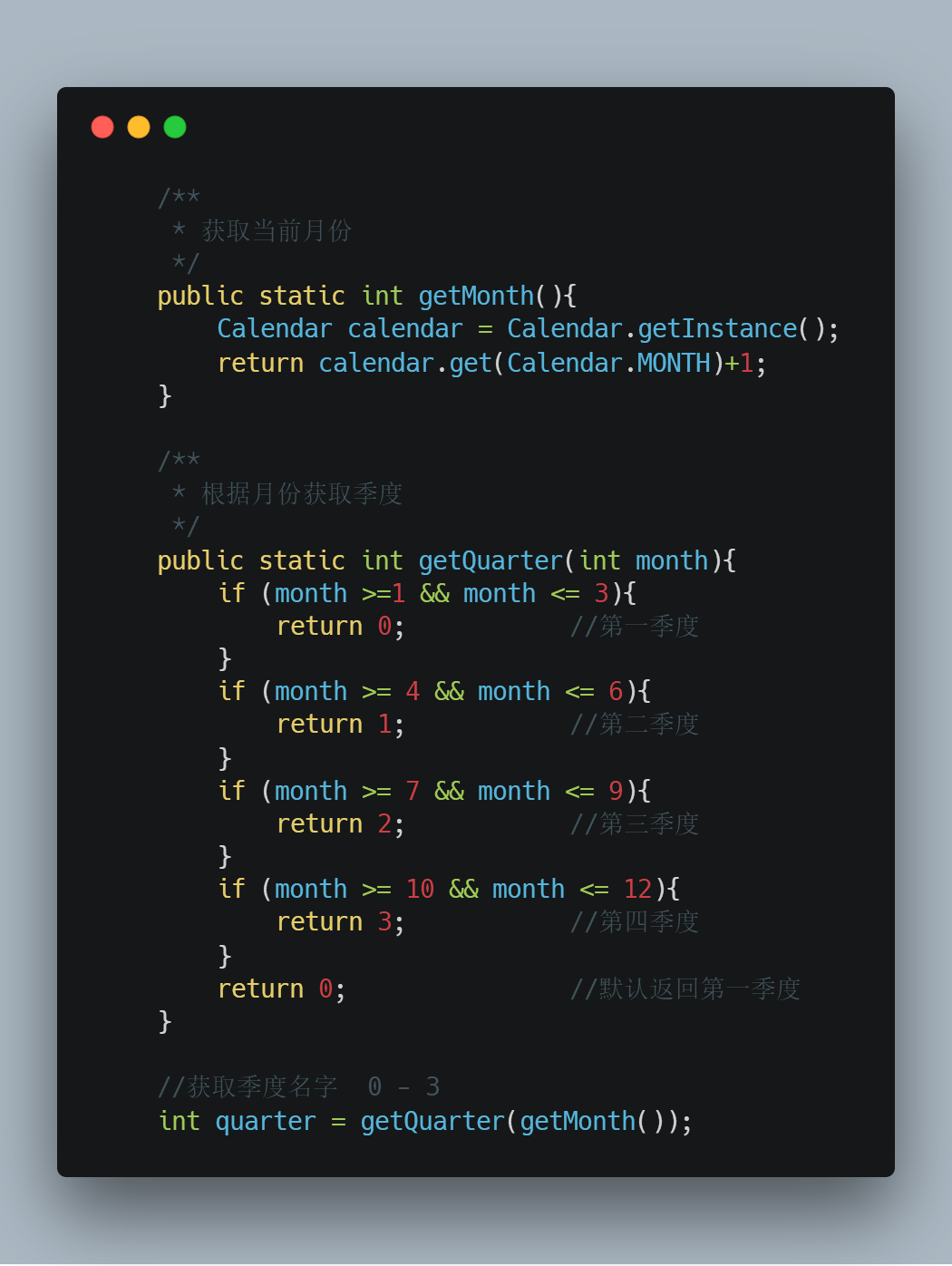
- 計算出對應的16張表所屬欄位:

- 獲取當前季度:

總結
基本上述就是本次分表的設計主思路,可以看到,入庫和查庫,為了保證一致性,需要設計相同的演算法才可以保證資料一致,所以python版迎合了java版的hashcode演算法,最終入庫的同一筆交易可以在java中查到。其中還有一個程式設計上的小技巧,就是在求具體0 - 15的時候,當初編碼的時候沒有用求餘的方式,而採用了位運算,感興趣的同學可以看下jdk7中HashMap的實現原始碼,在計算時,是可以用位運算替代求餘操作的!優勢就在於位運算的速度比較快。。。
以上!就是最近了解到的新知識,感謝老大帶我初體驗了一波分表的操作!後來還問了相關的設計,在分庫分表上優先考慮分表,原因是分表相對分庫來說簡單,減少多筆資料對一個表的訪問壓力就是分表的核心。若有更好的想法,歡迎小夥伴們留言區探討!