
jpa使用教程
本篇進行Spring-data-jpa的介紹,幾乎涵蓋該框架的所有方面,在日常的開發當中,基本上能滿足所有需求。這裡不講解JPA和Spring-data-jpa單獨使用,所有的內容都是在和Spring整合的環境中實現。如果需要了解該框架的入門,百度一下,很多入門的介紹。在這篇文章的接下來一篇,會有一個系列來講解mybatis,這個系列從mybatis的入門開始,到基本使用,和spring整合,和第三方外掛整合,快取,外掛,最後會持續到mybatis的架構,原始碼解釋,重點會介紹幾個重要的設計模式,這樣一個體系。基本上講完之後,mybatis在你面前就沒有了祕密,你能解決mybatis的幾乎所有問題,並且在開發過程中相當的方便,駕輕就熟。
這篇文章由於介紹的類容很全,因此很長,如果你需要,那麼可以耐心的看完,本人經歷了很長時間的學識,使用,研究的心血濃縮成為這麼短短的一篇部落格。
大致整理一個提綱:
1、Spring-data-jpa的基本介紹;
2、和Spring整合;
3、基本的使用方式;
4、複雜查詢,包括多表關聯,分頁,排序等;
現在開始:
1、Spring-data-jpa的基本介紹:JPA誕生的緣由是為了整合第三方ORM框架,建立一種標準的方式,百度百科說是JDK為了實現ORM的天下歸一,目前也是在按照這個方向發展,但是還沒能完全實現。在ORM框架中,Hibernate是一支很大的部隊,使用很廣泛,也很方便,能力也很強,同時Hibernate也是和JPA整合的比較良好,我們可以認為JPA是標準,事實上也是,JPA幾乎都是介面,實現都是Hibernate在做,巨集觀上面看,在JPA的統一之下Hibernate很良好的執行。
上面闡述了JPA和Hibernate的關係,那麼Spring-data-jpa又是個什麼東西呢?這地方需要稍微解釋一下,我們做Java開發的都知道Spring的強大,到目前為止,企業級應用Spring幾乎是無所不能,無所不在,已經是事實上的標準了,企業級應用不使用Spring的幾乎沒有,這樣說沒錯吧。而Spring整合第三方框架的能力又很強,他要做的不僅僅是個最早的IOC容器這麼簡單一回事,現在Spring涉及的方面太廣,主要是體現在和第三方工具的整合上。而在與第三方整合這方面,Spring做了持久化這一塊的工作,我個人的感覺是Spring希望把持久化這塊內容也拿下。於是就有了Spring-data-**這一系列包。包括,Spring-data-jpa,Spring-data-template,Spring-data-mongodb,Spring-data-redis,還有個民間產品,mybatis-spring,和前面類似,這是和mybatis整合的第三方包,這些都是乾的持久化工具乾的事兒。
這裡介紹Spring-data-jpa,表示與jpa的整合。
2、我們都知道,在使用持久化工具的時候,一般都有一個物件來操作資料庫,在原生的Hibernate中叫做Session,在JPA中叫做EntityManager,在MyBatis中叫做SqlSession,通過這個物件來操作資料庫。我們一般按照三層結構來看的話,Service層做業務邏輯處理,Dao層和資料庫打交道,在Dao中,就存在著上面的物件。那麼ORM框架本身提供的功能有什麼呢?答案是基本的CRUD,所有的基礎CRUD框架都提供,我們使用起來感覺很方便,很給力,業務邏輯層面的處理ORM是沒有提供的,如果使用原生的框架,業務邏輯程式碼我們一般會自定義,會自己去寫SQL語句,然後執行。在這個時候,Spring-data-jpa的威力就體現出來了,ORM提供的能力他都提供,ORM框架沒有提供的業務邏輯功能Spring-data-jpa也提供,全方位的解決使用者的需求。使用Spring-data-jpa進行開發的過程中,常用的功能,我們幾乎不需要寫一條sql語句,至少在我看來,企業級應用基本上可以不用寫任何一條sql,當然spring-data-jpa也提供自己寫sql的方式,這個就看個人怎麼選擇,都可以。我覺得都行。
2.1與Spring整合我們從spring配置檔案開始,為了節省篇幅,這裡我只寫出配置檔案的結構。

<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:context="http://www.springframework.org/schema/context" xmlns:mongo="http://www.springframework.org/schema/data/mongo" xmlns:jpa="http://www.springframework.org/schema/data/jpa" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.0.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd http://www.springframework.org/schema/data/mongo http://www.springframework.org/schema/data/mongo/spring-mongo-1.0.xsd http://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa.xsd"> <!-- 資料庫連線 --> <context:property-placeholder location="classpath:your-config.properties" ignore-unresolvable="true" /> <!-- service包 --> <context:component-scan base-package="your service package" /> <!-- 使用cglib進行動態代理 --> <aop:aspectj-autoproxy proxy-target-class="true" /> <!-- 支援註解方式宣告式事務 --> <tx:annotation-driven transaction-manager="transactionManager" proxy-target-class="true" /> <!-- dao --> <jpa:repositories base-package="your dao package" repository-impl-postfix="Impl" entity-manager-factory-ref="entityManagerFactory" transaction-manager-ref="transactionManager" /> <!-- 實體管理器 --> <bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="packagesToScan" value="your entity package" /> <property name="persistenceProvider"> <bean class="org.hibernate.ejb.HibernatePersistence" /> </property> <property name="jpaVendorAdapter"> <bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"> <property name="generateDdl" value="false" /> <property name="database" value="MYSQL" /> <property name="databasePlatform" value="org.hibernate.dialect.MySQL5InnoDBDialect" /> <!-- <property name="showSql" value="true" /> --> </bean> </property> <property name="jpaDialect"> <bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect" /> </property> <property name="jpaPropertyMap"> <map> <entry key="hibernate.query.substitutions" value="true 1, false 0" /> <entry key="hibernate.default_batch_fetch_size" value="16" /> <entry key="hibernate.max_fetch_depth" value="2" /> <entry key="hibernate.generate_statistics" value="true" /> <entry key="hibernate.bytecode.use_reflection_optimizer" value="true" /> <entry key="hibernate.cache.use_second_level_cache" value="false" /> <entry key="hibernate.cache.use_query_cache" value="false" /> </map> </property> </bean> <!-- 事務管理器 --> <bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager"> <property name="entityManagerFactory" ref="entityManagerFactory"/> </bean> <!-- 資料來源 --> <bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <property name="driverClassName" value="${driver}" /> <property name="url" value="${url}" /> <property name="username" value="${userName}" /> <property name="password" value="${password}" /> <property name="initialSize" value="${druid.initialSize}" /> <property name="maxActive" value="${druid.maxActive}" /> <property name="maxIdle" value="${druid.maxIdle}" /> <property name="minIdle" value="${druid.minIdle}" /> <property name="maxWait" value="${druid.maxWait}" /> <property name="removeAbandoned" value="${druid.removeAbandoned}" /> <property name="removeAbandonedTimeout" value="${druid.removeAbandonedTimeout}" /> <property name="timeBetweenEvictionRunsMillis" value="${druid.timeBetweenEvictionRunsMillis}" /> <property name="minEvictableIdleTimeMillis" value="${druid.minEvictableIdleTimeMillis}" /> <property name="validationQuery" value="${druid.validationQuery}" /> <property name="testWhileIdle" value="${druid.testWhileIdle}" /> <property name="testOnBorrow" value="${druid.testOnBorrow}" /> <property name="testOnReturn" value="${druid.testOnReturn}" /> <property name="poolPreparedStatements" value="${druid.poolPreparedStatements}" /> <property name="maxPoolPreparedStatementPerConnectionSize" value="${druid.maxPoolPreparedStatementPerConnectionSize}" /> <property name="filters" value="${druid.filters}" /> </bean> <!-- 事務 --> <tx:advice id="txAdvice" transaction-manager="transactionManager"> <tx:attributes> <tx:method name="*" /> <tx:method name="get*" read-only="true" /> <tx:method name="find*" read-only="true" /> <tx:method name="select*" read-only="true" /> <tx:method name="delete*" propagation="REQUIRED" /> <tx:method name="update*" propagation="REQUIRED" /> <tx:method name="add*" propagation="REQUIRED" /> <tx:method name="insert*" propagation="REQUIRED" /> </tx:attributes> </tx:advice> <!-- 事務入口 --> <aop:config> <aop:pointcut id="allServiceMethod" expression="execution(* your service implements package.*.*(..))" /> <aop:advisor pointcut-ref="allServiceMethod" advice-ref="txAdvice" /> </aop:config> </beans>
2.2對上面的配置檔案進行簡單的解釋,只對“實體管理器”和“dao”進行解釋,其他的配置在任何地方都差不太多。
1.對“實體管理器”解釋:我們知道原生的jpa的配置資訊是必須放在META-INF目錄下面的,並且名字必須叫做persistence.xml,這個叫做persistence-unit,就叫做持久化單元,放在這下面我們感覺不方便,不好,於是Spring提供了
org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean
這樣一個類,可以讓你的隨心所欲的起這個配置檔案的名字,也可以隨心所欲的修改這個檔案的位置,只需要在這裡指向這個位置就行。然而更加方便的做法是,直接把配置資訊就寫在這裡更好,於是就有了這實體管理器這個bean。使用
<property name="packagesToScan" value="your entity package" />
這個屬性來載入我們的entity。
2.3 解釋“dao”這個bean。這裡衍生一下,進行一下名詞解釋,我們知道dao這個層叫做Data Access Object,資料庫訪問物件,這是一個廣泛的詞語,在jpa當中,我們還有一個詞語叫做Repository,這裡我們一般就用Repository結尾來表示這個dao,比如UserDao,這裡我們使用UserRepository,當然名字無所謂,隨意取,你可以意會一下我的意思,感受一下這裡的含義和區別,同理,在mybatis中我們一般也不叫dao,mybatis由於使用xml對映檔案(當然也提供註解,但是官方文件上面表示在有些地方,比如多表的複雜查詢方面,註解還是無解,只能xml),我們一般使用mapper結尾,比如我們也不叫UserDao,而叫UserMapper。
上面拓展了一下關於dao的解釋,那麼這裡的這個配置資訊是什麼意思呢?首先base-package屬性,代表你的Repository介面的位置,repository-impl-postfix屬性代表介面的實現類的字尾結尾字元,比如我們的UserRepository,那麼他的實現類就叫做UserRepositoryImpl,和我們平時的使用習慣完全一致,於此同時,spring-data-jpa的習慣是介面和實現類都需要放在同一個包裡面(不知道有沒有其他方式能分開放,這不是重點,放在一起也無所謂,影響不大),再次的,這裡我們的UserRepositoryImpl這個類的定義的時候我們不需要去指定實現UserRepository介面,根據spring-data-jpa自動就能判斷二者的關係。
比如:我們的UserRepository和UserRepositoryImpl這兩個類就像下面這樣來寫。
public interface UserRepository extends JpaRepository<User, Integer>{} public class UserRepositoryImpl {}
那麼這裡為什麼要這麼做呢?原因是:spring-data-jpa提供基礎的CRUD工作,同時也提供業務邏輯的功能(前面說了,這是該框架的威力所在),所以我們的Repository介面要做兩項工作,繼承spring-data-jpa提供的基礎CRUD功能的介面,比如JpaRepository介面,同時自己還需要在UserRepository這個介面中定義自己的方法,那麼導致的結局就是UserRepository這個介面中有很多的方法,那麼如果我們的UserRepositoryImpl實現了UserRepository介面,導致的後果就是我們勢必需要重寫裡面的所有方法,這是Java語法的規定,如此一來,悲劇就產生了,UserRepositoryImpl裡面我們有很多的@Override方法,這顯然是不行的,結論就是,這裡我們不用去寫implements部分。
spring-data-jpa實現了上面的能力,那他是怎麼實現的呢?這裡我們通過原始碼的方式來呈現他的來龍去脈,這個過程中cglib發揮了傑出的作用。
在spring-data-jpa內部,有一個類,叫做
public class SimpleJpaRepository<T, ID extends Serializable> implements JpaRepository<T, ID>, JpaSpecificationExecutor<T>
我們可以看到這個類是實現了JpaRepository介面的,事實上如果我們按照上面的配置,在同一個包下面有UserRepository,但是沒有UserRepositoryImpl這個類的話,在執行時期UserRepository這個介面的實現就是上面的SimpleJpaRepository這個介面。而如果有UserRepositoryImpl這個檔案的話,那麼UserRepository的實現類就是UserRepositoryImpl,而UserRepositoryImpl這個類又是SimpleJpaRepository的子類,如此一來就很好的解決了上面的這個不用寫implements的問題。我們通過閱讀這個類的原始碼可以發現,裡面包裝了entityManager,底層的呼叫關係還是entityManager在進行CRUD。
3. 下面我們通過一個完整的專案來基本使用spring-data-jpa,然後我們在介紹他的高階用法。
a.資料庫建表:user,主鍵自增
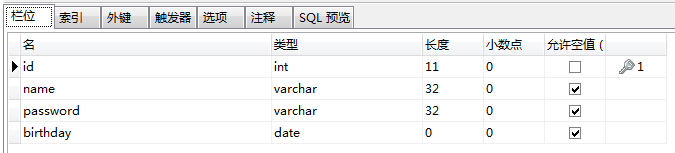
b.對應實體:User
@Entity @Table(name = "user") public class User { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer id; private String name; private String password; private String birthday; // getter,setter }
c.簡歷UserRepository介面
public interface UserRepository extends JpaRepository<User, Integer>{}
通過上面3步,所有的工作就做完了,User的基礎CRUD都能做了,簡約而不簡單。
d.我們的測試類UserRepositoryTest
public class UserRepositoryTest { @Autowired private UserRepository userRepository; @Test public void baseTest() throws Exception { User user = new User(); user.setName("Jay"); user.setPassword("123456"); user.setBirthday("2008-08-08"); userRepository.save(user); // userRepository.delete(user); // userRepository.findOne(1); } }
測試通過。
說到這裡,和spring已經完成。接下來第三點,基本使用。
4.前面把基礎的東西說清楚了,接下來就是spring-data-jpa的正餐了,真正威力的地方。
4.1 我們的系統中一般都會有使用者登入這個介面,在不使用spring-data-jpa的時候我們怎麼做,首先在service層定義一個登入方法。如:
User login(String name, String password);
然後在serviceImpl中寫該方法的實現,大致這樣:
@Override public User login(String name, String password) { return userDao.login(name, password); }
接下來,UserDao大概是這麼個樣子:
User getUserByNameAndPassword(String name, String password);
然後在UserDaoImpl中大概是這麼個樣子:
public User getUserByNameAndPassword(String name, String password) { Query query = em.createQuery("select * from User t where t.name = ?1 and t.password = ?2"); query.setParameter(1, name); query.setParameter(2, password); return (User) query.getSingleResult(); }
ok,這個程式碼執行良好,那麼這樣子大概有十來行程式碼,我們感覺這個功能實現了,很不錯。然而這樣子真正簡捷麼?如果這樣子就滿足了,那麼spring-data-jpa就沒有必要存在了,前面提到spring-data-jpa能夠幫助你完成業務邏輯程式碼的處理,那他是怎麼處理的呢?這裡我們根本不需要UserDaoImpl這個類,只需要在UserRepository介面中定義一個方法
User findByNameAndPassword(String name, String password);
然後在service中呼叫這個方法就完事了,所有的邏輯只需要這麼一行程式碼,一個沒有實現的介面方法。通過debug資訊,我們看到輸出的sql語句是
select * from user where name = ? and password = ?
跟上面的傳統方式一模一樣的結果。這簡單到令人髮指的程度,那麼這一能力是如何實現的呢?原理是:spring-data-jpa會根據方法的名字來自動生成sql語句,我們只需要按照方法定義的規則即可,上面的方法findByNameAndPassword,spring-data-jpa規定,方法都以findBy開頭,sql的where部分就是NameAndPassword,被spring-data-jpa翻譯之後就程式設計了下面這種形態:
where name = ? and password = ?
在舉個例,如果是其他的操作符呢,比如like,前端模糊查詢很多都是以like的方式來查詢。比如根據名字查詢使用者,sql就是
select * from user where name like = ?
這裡spring-data-jpa規定,在屬性後面接關鍵字,比如根據名字查詢使用者就成了
User findByNameLike(String name);
被翻譯之後的sql就是
select * from user where name like = ?
這也是簡單到令人髮指,spring-data-jpa所有的語法規定如下圖: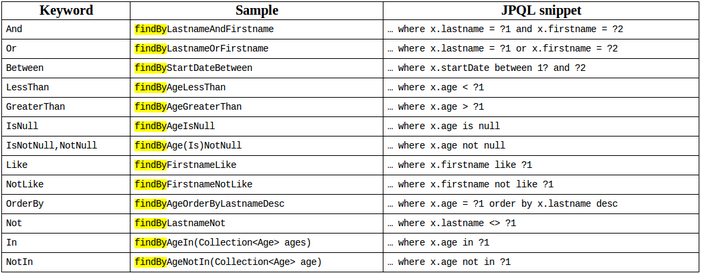
通過上面,基本CRUD和基本的業務邏輯操作都得到了解決,我們要做的工作少到僅僅需要在UserRepository介面中定義幾個方法,其他所有的工作都由spring-data-jpa來完成。
接下來:就是比較複雜的操作了,比如動態查詢,分頁,下面詳細介紹spring-data-jpa的第二大殺手鐗,強大的動態查詢能力。
在上面的介紹中,對於我們傳統的企業級應用的基本操作已經能夠基本上全部實現,企業級應用一般都會有一個模糊查詢的功能,並且是多條的查詢,在有查詢條件的時候我們需要在where後面接上一個 xxx = yyy 或者 xxx like '% + yyy + %'類似這樣的sql。那麼我們傳統的JDBC的做法是使用很多的if語句根據傳過來的查詢條件來拼sql,mybatis的做法也類似,由於mybatis有強大的動態xml檔案的標籤,在處理這種問題的時候顯得非常的好,但是二者的原理都一致,那spring-data-jpa的原理也同樣很類似,這個道理也就說明了解決多表關聯動態查詢根兒上也就是這麼回事。
那麼spring-data-jpa的做法是怎麼的呢?有兩種方式。可以選擇其中一種,也可以結合使用,在一般的查詢中使用其中一種就夠了,就是第二種,但是有一類查詢比較棘手,比如報表相關的,報表查詢由於涉及的表很多,這些表不一定就是兩兩之間有關係,比如字典表,就很獨立,在這種情況之下,使用拼接sql的方式要容易一些。下面分別介紹這兩種方式。
a.使用JPQL,和Hibernate的HQL很類似。
前面說道了在UserRepository介面的同一個包下面建立一個普通類UserRepositoryImpl來表示該類的實現類,同時前面也介紹了完全不需要這個類的存在,但是如果使用JPQL的方式就必須要有這個類。如下:
public class StudentRepositoryImpl { @PersistenceContext private EntityManager em; @SuppressWarnings("unchecked") public Page<Student> search(User user) { String dataSql = "select t from User t where 1 = 1"; String countSql = "select count(t) from User t where 1 = 1"; if(null != user && !StringUtils.isEmpty(user.getName())) { dataSql += " and t.name = ?1"; countSql += " and t.name = ?1"; } Query dataQuery = em.createQuery(dataSql); Query countQuery = em.createQuery(countSql); if(null != user && !StringUtils.isEmpty(user.getName())) { dataQuery.setParameter(1, user.getName()); countQuery.setParameter(1, user.getName()); }long totalSize = (long) countQuery.getSingleResult(); Page<User> page = new Page(); page.setTotalSize(totalSize); List<User> data = dataQuery.getResultList(); page.setData(data); return page; } }
通過上面的方法,我們查詢並且封裝了一個User物件的分頁資訊。程式碼能夠良好的執行。這種做法也是我們傳統的經典做法。那麼spring-data-jpa還有另外一種更好的方式,那就是所謂的型別檢查的方式,上面我們的sql是字串,沒有進行型別檢查,而下面的方式就使用了型別檢查的方式。這個道理在mybatis中也有體現,mybatis可以使用字串sql的方式,也可以使用介面的方式,而mybatis的官方推薦使用介面方式,因為有型別檢查,會更安全。
b.使用JPA的動態介面,下面的介面我把註釋刪了,為了節省篇幅,註釋也沒什麼用,看方法名字大概都能猜到是什麼意思。
public interface JpaSpecificationExecutor<T> { T findOne(Specification<T> spec); List<T> findAll(Specification<T> spec); Page<T> findAll(Specification<T> spec, Pageable pageable); List<T> findAll(Specification<T> spec, Sort sort); long count(Specification<T> spec); }
上面說了,使用這種方式我們壓根兒就不需要UserRepositoryImpl這個類,說到這裡,彷彿我們就發現了spring-data-jpa為什麼把Repository和RepositoryImpl檔案放在同一個包下面,因為我們的應用很可能根本就一個Impl檔案都不存在,那麼在那個包下面就只有一堆介面,即使把Repository和RepositoryImpl都放在同一個包下面,也不會造成這個包下面有正常情況下2倍那麼多的檔案,根本原因:只有介面而沒有實現類。
上面我們的UserRepository類繼承了JpaRepository和JpaSpecificationExecutor類,而我們的UserRepository這個物件都會注入到UserService裡面,於是如果使用這種方式,我們的邏輯直接就寫在service裡面了,下面的程式碼:一個學生Student類,一個班級Clazz類,Student裡面有一個物件Clazz,在資料庫中是clazz_id,這是典型的多對一的關係。我們在配置好entity裡面的關係之後。就可以在StudentServiceImpl類中做Student的模糊查詢,典型的前端grid的模糊查詢。程式碼是這樣子的:
@Service public class StudentServiceImpl extends BaseServiceImpl<Student> implements StudentService { @Autowired private StudentRepository studentRepository; @Override public Student login(Student student) { return studentRepository.findByNameAndPassword(student.getName(), student.getPassword()); } @Override public Page<Student> search(final Student student, PageInfo page) { return studentRepository.findAll(new Specification<Student>() { @Override public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { Predicate stuNameLike = null; if(null != student && !StringUtils.isEmpty(student.getName())) {
// 這裡也可以root.get("name").as(String.class)這種方式來強轉泛型型別 stuNameLike = cb.like(root.<String> get("name"), "%" + student.getName() + "%"); } Predicate clazzNameLike = null; if(null != student && null != student.getClazz() && !StringUtils.isEmpty(student.getClazz().getName())) { clazzNameLike = cb.like(root.<String> get("clazz").<String> get("name"), "%" + student.getClazz().getName() + "%"); } if(null != stuNameLike) query.where(stuNameLike); if(null != clazzNameLike) query.where(clazzNameLike); return null; } }, new PageRequest(page.getPage() - 1, page.getLimit(), new Sort(Direction.DESC, page.getSortName()))); } }
先解釋下這裡的意思,然後我們在結合框架的原始碼來深入分析。
這裡我們是2個表關聯查詢,查詢條件包括Student表和Clazz表,類似的2個以上的表方式差不多,但是正如上面所說,這種做法適合所有的表都是兩兩能夠關聯上的,涉及的表太多,或者是有一些字典表,那就使用sql拼接的方式,簡單一些。
先簡單解釋一下程式碼的含義,然後結合框架原始碼來詳細分析。兩個Predicate物件,Predicate按照中文意思是判斷,斷言的意思,那麼放在我們的sql中就是where後面的東西,比如
name like '% + jay + %';
下面的PageRequest代表分頁資訊,PageRequest裡面的Sort物件是排序資訊。上面的程式碼事實上是在動態的組合最終的sql語句,這裡使用了一個策略模式,或者callback,就是
studentRepository.findAll(一個介面)
studentRepository介面方法呼叫的引數是一個介面,而介面的實現類呼叫這個方法的時候,在內部,引數物件的實現類呼叫自己的toPredicate這個方法的實現內容,可以體會一下這裡的思路,就是傳一個介面,然後介面的實現自己來定義,這個思路在nettyJavaScript中體現的特別明顯,特別是JavaScript的框架中大量的這種方式,JS框架很多的做法都是上來先閉包,和瀏覽器的名稱空間分開,然後入口方法就是一個回撥,比如ExtJS:
Ext.onReady(function() { // xxx });
引數是一個function,其實在框架內部就呼叫了這個引數,於是這個這個方法執行了。這種模式還有一個JDK的排序集合上面也有體現,我們的netty框架也採用這種方式來實現非同步IO的能力。
接下來結合框架原始碼來詳細介紹這種機制,以及這種機制提供給我們的好處。
這裡首先從JPA的動態查詢開始說起,在JPA提供的API中,動態查詢大概有這麼一些方法,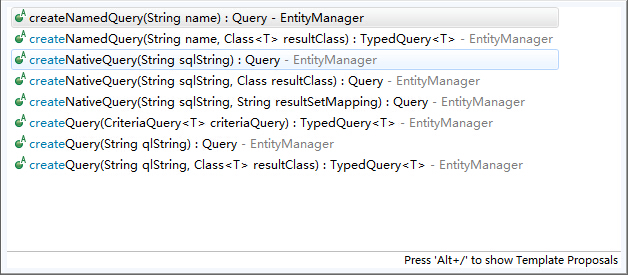
從名字大概可以看出這些方法的意義,跟Hibernate或者一些其他的工具也都差不多,這裡我們介紹引數為CriteriaQuery型別的這個方法,如果我們熟悉多種ORM框架的話,不難發現都有一個Criteria類似的東西,中文意思是“條件”的意思,這就是各個框架構建動態查詢的主體,Hibernate甚至有兩種,線上和離線兩種Criteria,mybatis也能從Example中建立Criteria,並且新增查詢條件。
那麼第一步就需要構建出這個引數CriteriaQuery型別的引數,這裡使用建造者模式,
CriteriaBuilder builder = em.getCriteriaBuilder(); CriteriaQuery<Student> query = builder.createQuery(Student.class);
接下來:
Root<Student> root = query.from(Student.class);
在這裡,我們看方法名from,意思是獲取Student的Root,其實也就是個Student的包裝物件,就代表這條sql語句裡面的主體。接下來:
相關推薦
Spring Boot 2.x 整合Spring Data JPA 教程(上卷)
當你看到了我這篇博文,那麼我想你應該已經知道 Spring Data JPA 在如今的網際網路開發中使用非常頻繁。
所以今天這篇博文主要探討學習Spring Boot 2.x 中如何整合Spring Data JPA.
在寫程式碼之前,請讓我們帶著這三個問題去學習。
《Hibernate快速開始 – 4 – 使用JAVA持久層 API (JPA)教程》
章節目標
使用JPA EntityManagerFactory
使用註解提供對映資訊
使用 JPA 介面
本教程可在 entitymanger/ 路徑下下載
4.1. persistence.xml
之前的章節使用了hibernate原生的配置檔案hibernate.cfg.xml。然而
JPA入門到精通教程 109個視頻
jpa入門https://ke.qq.com/course/199224#tuin=337f5ff2隨著Spring Boot微服務框架的逐漸流行,使用註解的方式寫代碼會越來越多,源碼時代順應企業需求,即時更新了原Hibernate內容,使用JPA代替,後續還會逐漸推出Spring Data JPA、Spri
JPA 菜鳥教程 15 繼承-一個表-SINGLE_TABLE
column turn rate pre school fill 技術 一個表 tor 原地址:http://blog.csdn.net/JE_GE/article/details/53678422
繼承映射策略
一個類繼承結構一個表的策略,最終只生成一個表,這是繼承映射的
jpa使用教程
本篇進行Spring-data-jpa的介紹,幾乎涵蓋該框架的所有方面,在日常的開發當中,基本上能滿足所有需求。這裡不講解JPA和Spring-data-jpa單獨使用,所有的內容都是在和Spring整合的環境中實現。如果需要了解該框架的入門,百度一下,很多入門的介紹。在這篇文章的接下來一篇,會有一
mybatis-jpa外掛使用教程
寫到最前面
隨著越來越多的專案使用myabtis,國內也有幾個my
Spring Boot簡明教程之資料訪問(二):JPA(超詳細)
Spring Boot簡明教程之資料訪問(二):JPA(超詳細)
文章目錄
Spring Boot簡明教程之資料訪問(二):JPA(超詳細)
建立專案
Spring Data簡介
JPA簡介
Spring Data 與JP
Spring Boot 基礎系列教程 | 第十二篇:使用Spring-data-jpa簡化資料訪問層(推薦)
推薦 Spring Boot/Cloud 視訊:
Spring Boot中使用Spring-data-jpa讓資料訪問更簡單、更優雅
在上一篇Spring中使用JdbcTemplate訪問資料庫 中介紹了一種基本的資料訪問方式,結合構建RESTful API和
iBatis、JPA、Lucene教程
iBATIS教程
iBATIS是什麼
iBATIS配置環境
iBATIS建立操作
iBATIS讀取操作
iBATIS更新操作
iBATIS刪除操作
MyEclipse開發教程:使用REST Web Services管理JPA實體(三)
MyEclipse 線上訂購年終抄底促銷!火爆開搶>>
MyEclipse最新版下載
使用REST Web Services來管理JPA實體。在逆向工程資料庫表後生成REST Web服務,下面的示例建立用於管理部落格條目的簡單Web服務。你將學會:
利用資料庫逆向工程開
MyEclipse開發教程:使用REST Web Services管理JPA實體(二)
MyEclipse 線上訂購年終抄底促銷!火爆開搶>>
MyEclipse最新版下載
使用REST Web Services來管理JPA實體。在逆向工程資料庫表後生成REST Web服務,下面的示例建立用於管理部落格條目的簡單Web服務。你將學會:
利用資料庫逆向工程開
MyEclipse開發教程:使用REST Web Services管理JPA實體(一)
MyEclipse 線上訂購年終抄底促銷!火爆開搶>>
MyEclipse最新版下載
使用REST Web Services來管理JPA實體。在逆向工程資料庫表後生成REST Web服務,下面的示例建立用於管理部落格條目的簡單Web服務。你將學會:
利用資料庫逆向工程開
MyEclipse使用教程:使用REST Web Services管理JPA實體
MyEclipse 線上訂購專享特惠!火爆開搶>>
MyEclipse最新版下載
使用REST Web Services來管理JPA實體。在逆向工程資料庫表後生成REST Web服務,下面的示例建立用於管理部落格條目的簡單Web服務。你將學會:
利用資料庫逆向工程開發REST Web服
Spring Boot入門教程(四十四): Sharding-JDBC+JPA|MyBatis+Druid分庫分表實現
一:資料庫分片方案
客戶端代理: 分片邏輯在應用端,封裝在jar包中,通過修改或者封裝JDBC層來實現。 噹噹網的 Sharding-JDBC 、阿里的TDDL是兩種比較常用的實現。
中介軟體代理: 在應用和資料中間加了一個代理層。分片邏輯統一維護在中介軟體
JPA 菜鳥教程 3 單向多對一
GitHub
JPA中的@ManyToOne
主要屬性
- name(必需): 設定“many”方所包含的“one”方所對應的持久化類的屬性名
- column(可選): 設定one方的主鍵,即持久化類的屬性對應的表的外來鍵
- class
基於Spring MVC+Spring JPA技術實戰開發大型商業ERP專案視訊教程
分享一套開發大型商業ERP專案的教程,是基於Spring MVC+Spring JPA技術上的,本課程將會以專案功能為驅動,以功能為載體依次從淺入深的講解目前Java Web開發中使用的最新技術。 課程中除了資料增刪改查這種傳統功能外,還涉及到許可權
JPA 菜鳥教程 19 jpa uuid主鍵生成策略
GitHub
ddl語句
CREATE TABLE `t_user` (
`id` varchar(32) NOT NULL,
`name` varchar(255) DEFAU
Karaf教程第9部分基於註解的blueprint和JPA
本部分演示如何用模型持久層和基於CDI註解的UI建立一個小的應用。
1 blueprint-maven-plugin
編寫blueprint xml檔案是很繁瑣的,太大的blueprint xml檔案很難與程式碼修改保持同步,尤其是程式碼重構。所以很多人喜歡使用註解來進行
JPA 菜鳥教程 6 單向多對多
GitHub
JPA中的@ManyToMany
@ManyToMany註釋表示模型類是多對多關係的一端。
@JoinTable 描述了多對多關係的資料表關係。
name 屬性指定中間表名稱
joinColumns 定義中間表與Teach
JPA 菜鳥教程 2 單表操作
GitHub
JPA
Sun官方提出的Java持久化規範。它為Java開發人員提供了一種物件/關係對映工具來管理Java應用中的關係資料。他的出現主要是為了簡化現有的持久化開發工作和整合ORM技術,結束現在Hibernate、TopLink等OR