
面試題 ------ 框架部分
阿新 • • 發佈:2018-11-05
1、什麼事框架?
框架(Framework)是一個框架————指約束性,也是一個架子————指器支撐性 IT 語境中的框架,特指為解決一個開放性問題而設計得具有一定約束性的支撐結構,在此結構上可以根據具體問題擴充套件、安插更多的組成部分,從而更迅速和方便地構建完整的解決問題的方案。 1、框架本身一般不完整到可以解決特定問題,但是可以幫助您快速解決特定問題: 沒有框架所有工作都從零開始做,有了框架,為我們提供了一定的功能,我們就可以在框架的基礎上開發,極大的解放了生產力。 2、框架天生就是為擴充套件而設計得 3、框架裡面可以為後續擴充套件的元件提供很多輔助性、支撐性的方便易用的實用工具(utilities),也就是說框架時常配套了一些幫助解決某類問題的庫(libraries)或工具(tools)。 在Java 中就是一系列的jar 包,其本質就是對jdk 功能的擴充套件。
2、MVC 模式
MVC 全稱是Model View Controller, 是模型(model)—— 檢視(view)—— 控制器(controller)的縮寫,一種軟體設計規範,用一種業務邏輯、資料、介面顯示分離的方法組織程式碼,將業務邏輯聚集到一個部件裡面,在改進和個性化定製介面及使用者互動同時,不需要重新編寫業務邏輯
最簡單的、最經典就是Jsp(view) + Servlet(controller) + JavaBean(model)

1、當控制器收到來自使用者的請求 2、控制器呼叫javaBean 完成業務 3、完成業務後,通過控制器跳轉頁面的方式給使用者反饋資訊 4、jsp 使用者做出響應 控制器是核心
3、什麼事MVC 框架?
是為了解決傳統MVC 模式(jsp + servlet + javabean)問題而出現的框架。 傳統MVC 模式問題: 1、所有得Servlet 和servlet 對映都要配置在web.xml 中,如果專案太大,web.xml就太龐大,並且不能實現模組化管理 2、Servlet 的主要功能就是接受引數、呼叫邏輯、跳轉頁面、比如像其他字元編碼、檔案上傳等功能也要解除安裝Servle 中,不能讓Servlet 主要功能而需要做處理一下特例。 3、接受引數比較麻煩(request.getParameter("name"),User user = new User(); user.setName(name);),不能通過model 接收,只能單個接收,接收完成後轉換封裝model。 4、跳轉頁面方式比較單一(forward,redirect),並且當我們頁面名稱發生改變時需要修改Servlet 原始碼 現在比較常用的MVC 框架有: Struts webwork Struts2 SpringMVC
4、簡單講一下struts2 的執行流程?

一個請求在Struts2 框架中的處理大概分為以下幾個步驟:
1、客戶端瀏覽器傳送請求
2、這個請求經過一系列的過濾器(Filter)(這些過濾器中有一個叫做ActionContextCleanUp的可選過濾器,這個過濾器對於Struts 和其他框架的整合很有幫助,例如:SiteMesh Plugin)
3、接著FilterDispatcher(StrutsPrepareAndExecuteFilter)被使用,FilterDispatcher(StrutsPrepareAndExecuteFilter)詢問ActionMapper 來決定這個請求是否需要呼叫某個Action;
4、如果ActionMapper 決定需要呼叫某個Action。FilterDispatcher(StrutsPrepareAndExecuteFilter)把請求的處理交給ActionProxy
5、ActionProxy 通過Configuration Manager 詢問框架的配置檔案,找到需要呼叫的Action 類;
6、ActionProxy 建立一個ActionInvocation 的例項
7、ActionInvocation 例項使用命名模式來呼叫,在呼叫Action 的過程前後,涉及到相關攔截器(Intercepter)的呼叫
8、一旦Action 執行完畢,ActuonInvocation 負責根據struts.xml 中的配置找到對應的返回結果,返回結果通常是(但不總是,也可能是另外的一個Action 鏈)一個需要被表示的JSP 或者 FreeMarker 的橫版,在表示的過程中可以使用Struts2 框架中繼承的標籤,在這個過程中需要涉及到ActionMapper。總結:
1、瀏覽器傳送請求,經過一系列的過濾器後,到達核心過濾器(StrutsPrepareAndExecuteFiler)
2、StrutsPrepareAndExecuteFiler 通過ActionMapper 判斷當前的請求是否需要某個Action 處理,如果不需要,則走原來的流程,如果需要則把請求交給ActionProxy 來處理
3、ActionProxy 通過Configuration Manager詢問框架的配置檔案(Struts.xml)。找到需要呼叫的Action 類
4、建立一個ActionInvocation 例項,來呼叫Action 的對應方法,獲取結果集的 name,在呼叫前後會執行相關攔截器。
5、通過結果集的Name 知道對應的結果集來對瀏覽器進行響應。
攔截、判斷、尋找、執行、響應5、Struts2 中的攔截器,你都用它幹什麼?
struts2 中的功能(引數處理、檔案上傳、字元編碼等)都是通過系統攔截器實現的。
如果業務需要,當然我們也可以自定義攔截器,進行可插拔配置,在執行Action的方法前後、加入相關邏輯完成業務。
使用場景:
1、使用者登陸判斷、在執行Action 的前面判斷是否已經登入,如果沒有登陸的跳轉到登陸頁面。
2、使用者許可權判斷、在執行Action 的前面判斷是否具有,如果沒有許可權給出提示資訊。
3、操作日誌。。。。6、簡單講一下SpringMVC 的執行流程?

1、使用者向伺服器傳送請求。請求被Spring 前端控制Servelt DispatcherServlet 捕獲 (捕獲);
2、DisparcherServlet 對請求URL 進行解析,得到請求資源標示符(URL)。然後根據該URL ,呼叫HandlerMapping 獲得該Handler 配置的所有相關的物件(包括Handler 物件以及Handler 物件對應的攔截器)。最後HandlerExecutionChain 物件的形式返回 (查詢handler);
3、DispatcherServlet 根據獲得的Handler,選擇一個合適的HandlerAdapter。提取Request 中的模型資料,填充Handler 入參,開始執行Handler(Controller),Handler執行完成後,向DispatcherServlet 返回一個ModelAndView 物件 (執行handler);
4、DispatcherServlet 根據返回的ModelAndView,選擇一個合適的ViewResolver(必須量已經註冊到Spring 容器中ViewResolver)(選擇viewResolver);
5、通過ViewResolver 結合Model 和 View,來渲染檢視DispatcherServlet 將渲染結果返回給客戶端 (渲染返回);
快速記憶:
核心控制器捕獲請求、查詢Handler、執行Handler、選擇合適的ViewResolver、通過ViewResolver渲染檢視並返回7、說一下struts2 和springMVC 有什麼不同?
目前企業中使用SpringMvc 的比例已經遠遠超過Struts2,那麼兩者到底有什麼區別,是很多初學者比較關注的問題,下面我們就來對SpringMVC 和Struts2 進行各方面的比較:
1、核心控制器(前端控制器、預處理控制器):對於使用過mvc 框架的人來說這個詞應該不會陌生,控制器的主要用途是處理所有得請求,然後對那些特殊請求(控制器)統一得進行處理(字元編碼、檔案上傳、引數接收、異常處理等等),SpringMVC 核心控制器是Servlet,而Struts2 是Filter。
2、控制器例項:SpringMVC 會比Struts快一些(理論上),SpringMVC 是基於方法設計,而Struts 是基於物件,每次發一次請求都會例項一個action, 每一個action 都會被注入屬性,而Spring更像Servlet一樣,只有一個例項,每次請求執行對應的方法即可(注意:用於是單例例項,所以應當避免全域性變數的修改,這樣會產生執行緒安全問題)
3、管理方式:大部分公司的核心架構中,就會使用到Spring 而SpringMVC 又是spring中的一個模組,所以spring 對於springMVC 的控制管理更加簡單方便,而且提供了全註解方式進行管理,各個功能的註解都比較全面,使用簡單,而struts2 需要採用XML 很多的配置引數來管理(雖然也可以採用註解,但是幾乎沒有公司那樣使用)
4、引數傳遞:Struts2 中自身提供很多種引數接受,其實都是通過(ValueStack)進行傳遞和賦值,而SpringMVC 是通過方法的引數進行接收
5、學習難度:Struts2 中自身提供多種技術點,比如攔截器、值棧及OGNL表示式,學習成本較高,springmvc 比較簡單,很較少的時間都能上手
6、intercepter 的實現機制:struts 有以自己的Interceptor 機制,springmvc 用的是獨立的AOP 方式,這樣導致struts 的配置檔案量還是比springmvc 大,雖然struts 的配置能繼承,所以我覺得論使用上來講,springmvc 使用更加簡潔,開發效率Springmvc 確實比struts2 高,springmvc 是方法級別的攔截,一個方法對應一個Request 上下文,而方法同時又跟一個url 對應,所以說從框架本身上springmvc 就容易實現restful
url, struts2 是級別的攔截,一個類對應一個request 上下文:實現restful url要費勁,因為strurs2 action 的一個方法可以對應一個url,而其類屬性卻被所有方法共享,這也就無法用註釋其他方式表示其所屬方法了,springmvc 的方法之間基本上獨立的,獨享request response 資料,請求資料通過引數資料獲取,處理結果通過ModelMap 交回給框架方法之間不共享變數,而struts2 就比較亂,雖然方法之間也是獨立的,但其所有Action 變數是共享,這不會影響程式執行,卻給我們編碼,讀程式時帶來麻煩。
7、springmvc 處理ajax 請求,直接通過返回資料,方法中使用註解@ResponseBody,SpringMVC 自動幫我們物件轉換為JSON 資料,而struts2 是通過外掛方式進行處理。
在SpringMVC 流行起來之前,Struts2 在MVC 框架中佔核心地位,隨著SpringMVC 的出現。SpringMVC 慢慢的取代Struts,但是很多企業都是原來搭建的框架,使用Struts2 比較8、說一下Spring 中的兩大核心?
Spring 是一個J2EE 應用程式框架,是輕量級的IOC 和AOP 的容器框架(相對重量級的框架EJB ),主要針對JavaBean 的生命週期進行管理的輕量級容器,可以單獨使用,也可以和Struts 框架,ibatis 框架等組合使用
1、IOC(Inversion of Control)或DI(Dependency Injection)
IOC 控制反轉
原來:我們得Service 需要呼叫DAO,Service 就需要建立DAO
Spring:Spring 發現你Service 依賴於dao,就給你注入。
核心原來:就是容器(map) + 反射(工廠也可以) + 配置檔案
2、AOP 面向切面程式設計
核心原來:使用動態代理的設計模式在執行方法前後或出現異常後做相關邏輯。
我們主要使用AOP 來做:
2.1、事務處理:在執行方法前,開啟事務、執行完成後關閉事務、出現異常後回滾事務
2.2、許可權判斷:在執行方法前,判斷是否具有許可權
2.3、日誌:在執行前進行日誌處理
2.4、。。。。9、Spring 事務的傳播特性
1、PROPAGATION_REQUIRED:如果存在一個事務,則支援當前事務,如果沒有事務則開啟
2、PROPAGATION_SUPPORTS:如果存在一個事務,支援當前事務,如果沒有事務,則非事務的執行
3、PROPAGATION_MANDATORY:如果已經存在一個事務,支援當前事務,如果沒有一個活動的事務,則丟擲異常
4、PROPAGATION_REQUTIRES_NEW:總是開啟一個新的事務。如果一個事務已經存在,則將這個存在的事務掛起
5、PROPAGATION_NOT_SUPPORTED:總是非事務地執行,並掛起任何存在的事務。
6、PROPAGATION_NEVER:總是非事務地執行,如果存在一個活動事務,則丟擲異常
7、PROPAGATION_NESTED:如果一個活動的事務存在,則執行在一個巢狀的事務中,如果沒有活動事務,則按TransactionDefinition.PROPAGATION_REQUIRED 屬性執行10、Spring 事務的隔離級別
隔離級別
宣告式事務的第二個方面是隔離級別。隔離級別定義一個事務可能受其他併發事務活動活動影響的程度。另一種考慮一個事務的隔離級別的方式,是把它想象為那個事務對於事物處理資料的自私程度。
在一個典型的應用程式中,多個事務同時執行,經常會為了完成他們的工作而操作同一個資料。併發雖然是必需的,但是會導致一下問題:
1、髒讀(Dirty read)-- 髒讀發生在一個事務讀取了被另一個事務改寫但尚未提交的資料時。如果這些改變在稍後被回滾了,那麼第一個事務讀取的資料就會是無效的。
2、不可重複讀(Nonrepeatable read)-- 不可重複讀發生在一個事務執行相同的查詢兩次或兩次以上,但每次查詢結果都不相同時。這通常是由於另一個併發事務在兩次查詢之間更新了資料。
3、幻影讀(Phantom reads)-- 幻影讀和不可重複讀相似。當一個事務(T1)讀取幾行記錄後,另一個併發事務(T2)插入了一些記錄時,幻影讀就發生了。在後來的查詢中,第一個事務(T1)就會發現一些原來沒有的額外記錄。
在理想狀態下,事務之間將完全隔離,從而可以防止這些問題發生。然而,完全隔離會影響效能,因為隔離經常牽扯到鎖定在資料庫中的記錄(而且有時是鎖定完整的資料表)。侵佔性的鎖定會阻礙併發,要求事務相互等待來完成工作。
考慮到完全隔離會影響效能,而且並不是所有應用程式都要求完全隔離,所以有時可以在事務隔離方面靈活處理。因此,就會有好幾個隔離級別。| 隔離級別 | 含義 |
|---|---|
| ISOLATION_DEFAULT | 使用後端資料庫預設的隔離級別。 |
| ISOLATION_READ_UNCOMMITTED | 允許讀取尚未提交的更改。可能導致髒讀、幻影讀或不可重複讀。 |
| ISOLATION_READ_COMMITTED | 允許從已經提交的併發事務讀取。可防止髒讀,但幻影讀和不可重複讀仍可能會發生。 |
| ISOLATION_REPEATABLE_READ | 對相同欄位的多次讀取的結果是一致的,除非資料被當前事務本身改變。可防止髒讀和不可重複讀,但幻影讀仍可能發生。 |
| ISOLATION_SERIALIZABLE | 完全服從ACID的隔離級別,確保不發生髒讀、不可重複讀和幻影讀。這在所有隔離級別中也是最慢的,因為它通常是通過完全鎖定當前事務所涉及的資料表來完成的。 |
只讀
宣告式事務的第三個特性是它是否是一個只讀事務。如果一個事務只對後端資料庫執行讀操作,那麼該資料庫就可能利用那個事務的只讀特性,採取某些優化 措施。通過把一個事務宣告為只讀,可以給後端資料庫一個機會來應用那些它認為合適的優化措施。由於只讀的優化措施是在一個事務啟動時由後端資料庫實施的, 因此,只有對於那些具有可能啟動一個新事務的傳播行為(PROPAGATION_REQUIRES_NEW、PROPAGATION_REQUIRED、 ROPAGATION_NESTED)的方法來說,將事務宣告為只讀才有意義。
此外,如果使用Hibernate作為持久化機制,那麼把一個事務宣告為只讀,將使Hibernate的flush模式被設定為FLUSH_NEVER。這就告訴Hibernate避免和資料庫進行不必要的物件同步,從而把所有更新延遲到事務的結束。
事務超時
為了使一個應用程式很好地執行,它的事務不能執行太長時間。因此,宣告式事務的下一個特性就是它的超時。
假設事務的執行時間變得格外的長,由於事務可能涉及對後端資料庫的鎖定,所以長時間執行的事務會不必要地佔用資料庫資源。這時就可以宣告一個事務在特定秒數後自動回滾,不必等它自己結束。
由於超時時鐘在一個事務啟動的時候開始的,因此,只有對於那些具有可能啟動一個新事務的傳播行為(PROPAGATION_REQUIRES_NEW、PROPAGATION_REQUIRED、ROPAGATION_NESTED)的方法來說,宣告事務超時才有意義。
回滾規則
事務五邊形的對後一個邊是一組規則,它們定義哪些異常引起回滾,哪些不引起。在預設設定下,事務只在出現執行時異常(runtime exception)時回滾,而在出現受檢查異常(checked exception)時不回滾(這一行為和EJB中的回滾行為是一致的)。
不過,也可以宣告在出現特定受檢查異常時像執行時異常一樣回滾。同樣,也可以宣告一個事務在出現特定的異常時不回滾,即使那些異常是執行時一場。擴充套件閱讀
標題是隻有事務的隔離級別和傳播機制,卻順帶這把宣告式事務的五個特性都講述了一遍。:)
文章開頭說過檢視Spring中事務的原始碼來確認3.0版本及之後事務的傳播機制是否減少了,其實在TransactionDefinition這個介面中定義了事務的隔離級別、傳播機制、只讀以及超時相關的全部資訊。原始碼如下,感興趣的可以自己對照一下,看看英文註釋。/*
* Copyright 2002-2010 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.springframework.transaction;
import java.sql.Connection;
/**
* Interface that defines Spring-compliant transaction properties.
* Based on the propagation behavior definitions analogous to EJB CMT attributes.
*
* <p>Note that isolation level and timeout settings will not get applied unless
* an actual new transaction gets started. As only {@link #PROPAGATION_REQUIRED},
* {@link #PROPAGATION_REQUIRES_NEW} and {@link #PROPAGATION_NESTED} can cause
* that, it usually doesn't make sense to specify those settings in other cases.
* Furthermore, be aware that not all transaction managers will support those
* advanced features and thus might throw corresponding exceptions when given
* non-default values.
*
* <p>The {@link #isReadOnly() read-only flag} applies to any transaction context,
* whether backed by an actual resource transaction or operating non-transactionally
* at the resource level. In the latter case, the flag will only apply to managed
* resources within the application, such as a Hibernate <code>Session</code>.
*
* @author Juergen Hoeller
* @since 08.05.2003
* @see PlatformTransactionManager#getTransaction(TransactionDefinition)
* @see org.springframework.transaction.support.DefaultTransactionDefinition
* @see org.springframework.transaction.interceptor.TransactionAttribute
*/
public interface TransactionDefinition {
/**
* Support a current transaction; create a new one if none exists.
* Analogous to the EJB transaction attribute of the same name.
* <p>This is typically the default setting of a transaction definition,
* and typically defines a transaction synchronization scope.
*/
int PROPAGATION_REQUIRED = 0;
/**
* Support a current transaction; execute non-transactionally if none exists.
* Analogous to the EJB transaction attribute of the same name.
* <p><b>NOTE:</b> For transaction managers with transaction synchronization,
* <code>PROPAGATION_SUPPORTS</code> is slightly different from no transaction
* at all, as it defines a transaction scope that synchronization might apply to.
* As a consequence, the same resources (a JDBC <code>Connection</code>, a
* Hibernate <code>Session</code>, etc) will be shared for the entire specified
* scope. Note that the exact behavior depends on the actual synchronization
* configuration of the transaction manager!
* <p>In general, use <code>PROPAGATION_SUPPORTS</code> with care! In particular, do
* not rely on <code>PROPAGATION_REQUIRED</code> or <code>PROPAGATION_REQUIRES_NEW</code>
* <i>within</i> a <code>PROPAGATION_SUPPORTS</code> scope (which may lead to
* synchronization conflicts at runtime). If such nesting is unavoidable, make sure
* to configure your transaction manager appropriately (typically switching to
* "synchronization on actual transaction").
* @see org.springframework.transaction.support.AbstractPlatformTransactionManager#setTransactionSynchronization
* @see org.springframework.transaction.support.AbstractPlatformTransactionManager#SYNCHRONIZATION_ON_ACTUAL_TRANSACTION
*/
int PROPAGATION_SUPPORTS = 1;
/**
* Support a current transaction; throw an exception if no current transaction
* exists. Analogous to the EJB transaction attribute of the same name.
* <p>Note that transaction synchronization within a <code>PROPAGATION_MANDATORY</code>
* scope will always be driven by the surrounding transaction.
*/
int PROPAGATION_MANDATORY = 2;
/**
* Create a new transaction, suspending the current transaction if one exists.
* Analogous to the EJB transaction attribute of the same name.
* <p><b>NOTE:</b> Actual transaction suspension will not work out-of-the-box
* on all transaction managers. This in particular applies to
* {@link org.springframework.transaction.jta.JtaTransactionManager},
* which requires the <code>javax.transaction.TransactionManager</code>
* to be made available it to it (which is server-specific in standard J2EE).
* <p>A <code>PROPAGATION_REQUIRES_NEW</code> scope always defines its own
* transaction synchronizations. Existing synchronizations will be suspended
* and resumed appropriately.
* @see org.springframework.transaction.jta.JtaTransactionManager#setTransactionManager
*/
int PROPAGATION_REQUIRES_NEW = 3;
/**
* Do not support a current transaction; rather always execute non-transactionally.
* Analogous to the EJB transaction attribute of the same name.
* <p><b>NOTE:</b> Actual transaction suspension will not work out-of-the-box
* on all transaction managers. This in particular applies to
* {@link org.springframework.transaction.jta.JtaTransactionManager},
* which requires the <code>javax.transaction.TransactionManager</code>
* to be made available it to it (which is server-specific in standard J2EE).
* <p>Note that transaction synchronization is <i>not</i> available within a
* <code>PROPAGATION_NOT_SUPPORTED</code> scope. Existing synchronizations
* will be suspended and resumed appropriately.
* @see org.springframework.transaction.jta.JtaTransactionManager#setTransactionManager
*/
int PROPAGATION_NOT_SUPPORTED = 4;
/**
* Do not support a current transaction; throw an exception if a current transaction
* exists. Analogous to the EJB transaction attribute of the same name.
* <p>Note that transaction synchronization is <i>not</i> available within a
* <code>PROPAGATION_NEVER</code> scope.
*/
int PROPAGATION_NEVER = 5;
/**
* Execute within a nested transaction if a current transaction exists,
* behave like {@link #PROPAGATION_REQUIRED} else. There is no analogous
* feature in EJB.
* <p><b>NOTE:</b> Actual creation of a nested transaction will only work on
* specific transaction managers. Out of the box, this only applies to the JDBC
* {@link org.springframework.jdbc.datasource.DataSourceTransactionManager}
* when working on a JDBC 3.0 driver. Some JTA providers might support
* nested transactions as well.
* @see org.springframework.jdbc.datasource.DataSourceTransactionManager
*/
int PROPAGATION_NESTED = 6;
/**
* Use the default isolation level of the underlying datastore.
* All other levels correspond to the JDBC isolation levels.
* @see java.sql.Connection
*/
int ISOLATION_DEFAULT = -1;
/**
* Indicates that dirty reads, non-repeatable reads and phantom reads
* can occur.
* <p>This level allows a row changed by one transaction to be read by another
* transaction before any changes in that row have been committed (a "dirty read").
* If any of the changes are rolled back, the second transaction will have
* retrieved an invalid row.
* @see java.sql.Connection#TRANSACTION_READ_UNCOMMITTED
*/
int ISOLATION_READ_UNCOMMITTED = Connection.TRANSACTION_READ_UNCOMMITTED;
/**
* Indicates that dirty reads are prevented; non-repeatable reads and
* phantom reads can occur.
* <p>This level only prohibits a transaction from reading a row
* with uncommitted changes in it.
* @see java.sql.Connection#TRANSACTION_READ_COMMITTED
*/
int ISOLATION_READ_COMMITTED = Connection.TRANSACTION_READ_COMMITTED;
/**
* Indicates that dirty reads and non-repeatable reads are prevented;
* phantom reads can occur.
* <p>This level prohibits a transaction from reading a row with uncommitted changes
* in it, and it also prohibits the situation where one transaction reads a row,
* a second transaction alters the row, and the first transaction re-reads the row,
* getting different values the second time (a "non-repeatable read").
* @see java.sql.Connection#TRANSACTION_REPEATABLE_READ
*/
int ISOLATION_REPEATABLE_READ = Connection.TRANSACTION_REPEATABLE_READ;
/**
* Indicates that dirty reads, non-repeatable reads and phantom reads
* are prevented.
* <p>This level includes the prohibitions in {@link #ISOLATION_REPEATABLE_READ}
* and further prohibits the situation where one transaction reads all rows that
* satisfy a <code>WHERE</code> condition, a second transaction inserts a row
* that satisfies that <code>WHERE</code> condition, and the first transaction
* re-reads for the same condition, retrieving the additional "phantom" row
* in the second read.
* @see java.sql.Connection#TRANSACTION_SERIALIZABLE
*/
int ISOLATION_SERIALIZABLE = Connection.TRANSACTION_SERIALIZABLE;
/**
* Use the default timeout of the underlying transaction system,
* or none if timeouts are not supported.
*/
int TIMEOUT_DEFAULT = -1;
/**
* Return the propagation behavior.
* <p>Must return one of the <code>PROPAGATION_XXX</code> constants
* defined on {@link TransactionDefinition this interface}.
* @return the propagation behavior
* @see #PROPAGATION_REQUIRED
* @see org.springframework.transaction.support.TransactionSynchronizationManager#isActualTransactionActive()
*/
int getPropagationBehavior();
/**
* Return the isolation level.
* <p>Must return one of the <code>ISOLATION_XXX</code> constants
* defined on {@link TransactionDefinition this interface}.
* <p>Only makes sense in combination with {@link #PROPAGATION_REQUIRED}
* or {@link #PROPAGATION_REQUIRES_NEW}.
* <p>Note that a transaction manager that does not support custom isolation levels
* will throw an exception when given any other level than {@link #ISOLATION_DEFAULT}.
* @return the isolation level
*/
int getIsolationLevel();
/**
* Return the transaction timeout.
* <p>Must return a number of seconds, or {@link #TIMEOUT_DEFAULT}.
* <p>Only makes sense in combination with {@link #PROPAGATION_REQUIRED}
* or {@link #PROPAGATION_REQUIRES_NEW}.
* <p>Note that a transaction manager that does not support timeouts will throw
* an exception when given any other timeout than {@link #TIMEOUT_DEFAULT}.
* @return the transaction timeout
*/
int getTimeout();
/**
* Return whether to optimize as a read-only transaction.
* <p>The read-only flag applies to any transaction context, whether
* backed by an actual resource transaction
* ({@link #PROPAGATION_REQUIRED}/{@link #PROPAGATION_REQUIRES_NEW}) or
* operating non-transactionally at the resource level
* ({@link #PROPAGATION_SUPPORTS}). In the latter case, the flag will
* only apply to managed resources within the application, such as a
* Hibernate <code>Session</code>.
* <p>This just serves as a hint for the actual transaction subsystem;
* it will <i>not necessarily</i> cause failure of write access attempts.
* A transaction manager which cannot interpret the read-only hint will
* <i>not</i> throw an exception when asked for a read-only transaction.
* @return <code>true</code> if the transaction is to be optimized as read-only
* @see org.springframework.transaction.support.TransactionSynchronization#beforeCommit(boolean)
* @see org.springframework.transaction.support.TransactionSynchronizationManager#isCurrentTransactionReadOnly()
*/
boolean isReadOnly();
/**
* Return the name of this transaction. Can be <code>null</code>.
* <p>This will be used as the transaction name to be shown in a
* transaction monitor, if applicable (for example, WebLogic's).
* <p>In case of Spring's declarative transactions, the exposed name will be
* the <code>fully-qualified class name + "." + method name</code> (by default).
* @return the name of this transaction
* @see org.springframework.transaction.interceptor.TransactionAspectSupport
* @see org.springframework.transaction.support.TransactionSynchronizationManager#getCurrentTransactionName()
*/
String getName();
}11、什麼事ROM?
物件關係對映(Object Relational Mapping,簡稱ROM)模式是一種為了解決面向物件與關係型資料庫存在的互不匹配的現象的技術,簡單的說,ORM 是通過使用描述物件和資料庫之間對映的元資料,將程式中的物件自動持久化到關係資料庫中,那麼,到底如何實現持久化呢?一種簡單的方案是採用硬編碼方式(jdbc 操作sql 方式),為每一種可能的資料庫訪問操作提供單獨的方法。
這種方案存在以下不足:
1、持久化層缺乏彈性,一旦出現業務需求的變更,就必須修改持久化層的介面
2、持久化層同時與域模型與關係資料庫模型繫結,不管模型還是關係資料庫模型發生變化,都要修改持久化層的相關程式程式碼,增加了軟體的維護難度。
ORM 提供了實現持久化層的另一種模式,它採用對映元資料來描述物件關係得對映,使得ORM 中介軟體能在任何一個應用的業務邏輯層和資料庫層充當橋樑。java 典型的ORM 框架有:hibernate,ibatis,speedframework
ORM的方法論基於三個核心原則:
簡單:以最基本的形式建模資料
傳達性:資料庫結構被任何人都能理解的語言文件化
精確性:基於資料庫模型建立正確標準化了的結構
物件關係對映(Object、 Relational Mapping,簡稱 ROM)模式是一種為了解決面向物件與關係型資料庫存在的互不匹配的現象的技術,可以簡單的方案是採用硬編碼方式(jdbc 操作 sql方式),為每一種可能的資料庫訪問操作單獨的方式,這種方法存在很多缺陷。12、ibatis(mybatis) 與 hibernate 有什麼不同?
相同點:
都是java 中的orm 框架,遮蔽jdbc api的底層訪問細節,使用我們不用與jdbc api打交道,就可以完成對資料庫的持久化操作,jdbc api程式設計流程固定,還將sql 語句與java 程式碼混雜在一起,經常需要拼湊sql 語句,細節很繁瑣。
ibatis 的好處:遮蔽jdbc api的底層訪問細節,將sql 語句與java 程式碼進行分類;提供了將結果集自動封裝成為實體物件和物件的集合的功能,queryForList 返回物件集合,用queryForObject 返回單個物件;提供了自動將實體物件的屬性傳遞給sql 語句的引數。
Hibernate 的好處:Hibernate 是一個全自動的orm 對映工具,它可以自動生成sql 語句,並執行返回java 結果
不同點:
1、hibernate 要比ibatis 功能強大很多,因為Hibernate 自動生成sql 語句
2、ibatis 需要我們自己在 xml配置檔案中寫sql 語句,hibernate 我們無法控制該語句。我們就無法去寫特定的高效的sql,對於一些不太複雜的sql 查詢,hibernate 可以很好幫我們完成,但是,對於特別複雜的查詢,hibernate就很難適應了,這時候用ibatis 就不錯的選擇,因為ibatis 還是我們自己寫sql 語句
3、ibatis 要比hibernate 簡單的多,ibatis 是面向sql 的,不同考慮物件間一些複雜的對映關係13、Hibernate 對映物件的狀態?
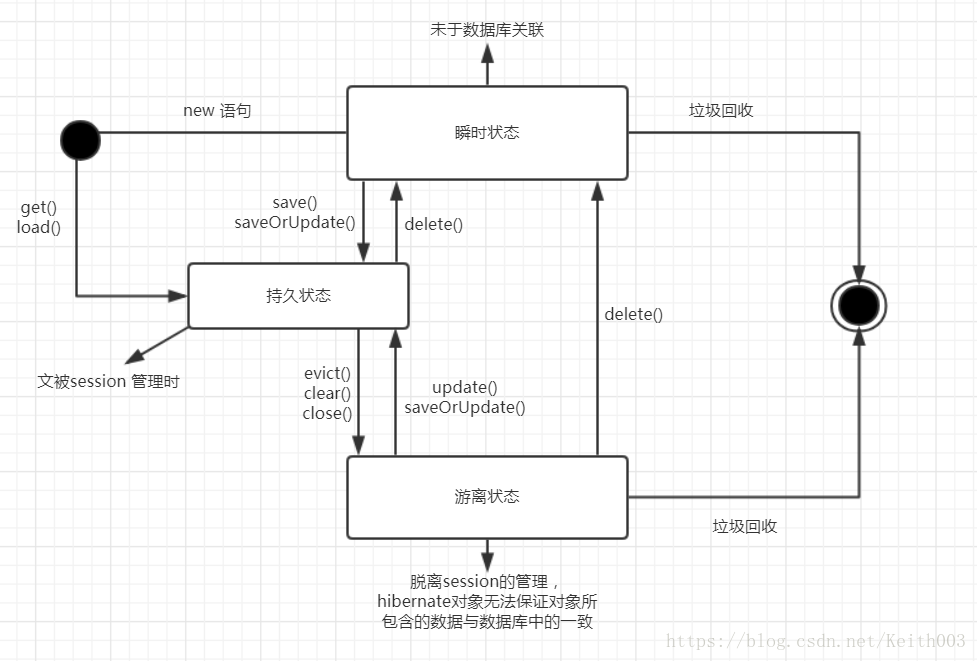
1、臨時狀態/瞬時狀態(transient):剛剛用new 語句建立,沒有被持久化,無id 不處於session 中(沒有使用session 的方法去操作臨時物件),該物件稱為臨時物件;
2、持久化狀態/託管狀態(persistent):已經被持久化,加入到session 的快取中,session 是沒有關閉狀態的物件為持久化物件;
3、遊離狀態/脫管狀態(detached):已經被持久化,但不處於session中,該狀態的物件為遊離狀態
4、刪除狀態(removed):物件有關聯的ID,並且在Session 管理下,但是已經被計劃(事務提交得時候,commit())刪除。如果沒有事務就不能刪除
14、簡單講一下webservice 使用的場景?
webservice 是一個SOA(面向服務的程式設計)的架構,它是不依賴於語言,不依賴於平臺,可以實現不同的語言間的互相呼叫,通過Internet 進行基於Http 協議的網路應用間的互動。
1、異構系統的整合
2、不同客戶端的整合 瀏覽器、手機端(android、ios、塞班)、微信端、PC端等來訪問
例子:天氣預報、單點登入
15、簡單介紹一下activiti?
Activiti 是一個業務流程管理器(BPM)和工作流系統,適用於開發人員和系統管理員、其核心是超快速、穩定的BIPMN2 流程引擎,它易於與Spring 整合使用。
主要在OA 中,吧線下流程放到線上,把現實生活中一些流程圖定義到系統中,然後通過輸入表單資料完成業務。
他可用在OA 系統的流程管理中:請假流程、報銷流程
注:內容來源於網路