
第一部分 如何監測elasticsearch的效能?
本文翻譯自網站https://www.datadoghq.com/blog/monitor-elasticsearch-performance-metrics/
一、什麼是Elasticsearch?
Elasticsearch是一個開源的分散式文件儲存和搜尋引擎,可以近實時的儲存和檢索資料結構。由Shay Banon 在2010年開發和編譯,嚴重依賴由Java編寫的全文搜尋引擎Apache Lucene。
Elasticsearch用JSON文件的結構來描述資料,並通過RESTfull API和PHP、Python、Ruby等語言的web 客戶端來進行全文搜尋。Elasticsearch可以很簡單的進行橫向擴充套件–通過增加更多的節點來分配負載。目前,很多公司,包括Wikipedia, eBay, GitHub, and Datadog,均使用Elasticsearch來進行大量的動態資料分析。
Elasticsearch的元素
在我們開始研究效能指標之前,讓我們先解釋一下Elasticsearch的工作原理。在Elasticsearch中,一個叢集由1個或者多個節點組成,如下圖所示:
每個節點是一個獨立執行的Elasticsearch例項,由elasticsearch.yml配置檔案決定節點屬於哪個叢集(cluster.name)、節點是什麼型別的節點(master主節點或者data資料節點,或者即是master節點也是data節點)。在這個配置檔案中的任何屬性也可以通過命令列引數指定。上圖所示的叢集由1個專用的主節點和5個數據節點。
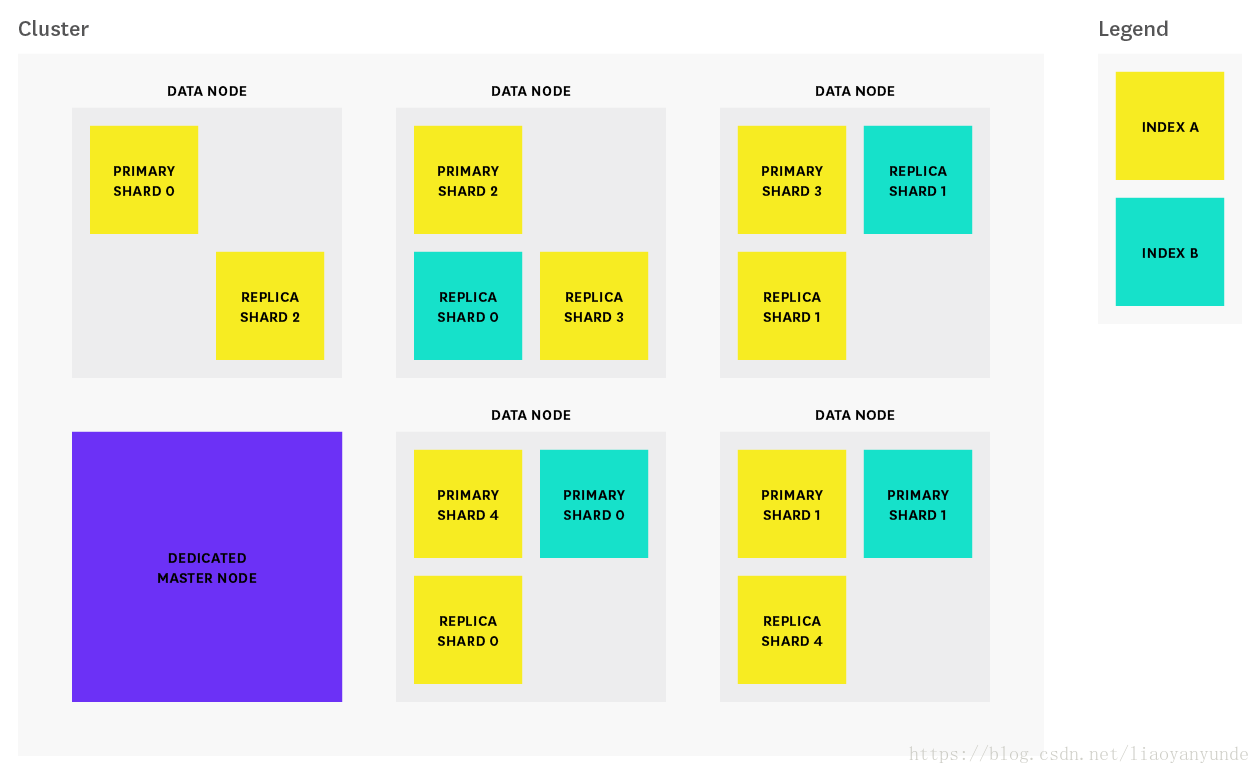
在Elasticsearch中最常見的三種節點如下:
Master-eligible nodes 候選主節點
除非有其他的指定,預設每個節點均是候選主節點。每個叢集自動從所有的候選主節點中選舉出一個主節點。在當前主節點掛了(如斷電、硬體故障、記憶體溢位錯誤等)之後,叢集會從候選主節點中選舉出一個新的主節點。主節點負責協調叢集任務,如跨節點分配分片、建立和刪除索引。任何候選主節點同時也可以充當資料節點。儘管如此,在大部分叢集中,為了提高叢集的可靠性,使用者可能會啟動一個不儲存資料的專用主節點(通過在配置檔案中新增配置項node.data: false)。在高可用的環境中,將主節點角色從資料節點中分離開可以幫助保證叢集中總是有足夠的資源分配給只能由主節點處理的任務。
Data nodes 資料節點
預設的,每個節點都是資料節點,資料節點以分片的形式儲存資料(關於分片的更多資訊見下一章節),執行與索引、搜尋和聚合資料相關的操作。在大部分叢集中,可以選擇通過在配置檔案中新增配置項node.master: false來建立一個專用的資料節點,沒有與叢集相關的管理任務的額外工作負載,可以保證這些節點具有足夠的資源來處理資料相關的請求。
Client nodes 客戶端節點
如果設定node.master 和 node.data為false,就可以啟動為一個客戶端節點。客戶端節點設計用於充當負載均衡器,幫助路由索引和搜尋請求。客戶端節點幫助分擔檢索壓力,這樣資料節點和候選主節點就可以專注於它們的核心任務中。根據使用場景,客戶端節點可能不是必須的,因為資料節點也可以自己處理請求路由。儘管如此,當搜尋/索引的負載很嚴重的時候在叢集中增加客戶端節點來幫助路由請求是非常有意義的
Elasticsearch是如何組織資料的?
在Elasticsearch中,相關的資料經常放在同一個索引(index)中,索引可以被看作是配置的邏輯包裝器。每個索引包含一組JSON格式的相關文件。Elasticsearch全文索引的祕訣是Lucene的倒排索引。當一個文件被索引,Elasticsearch自動為每個欄位建立倒排索引,倒排索引將關鍵字對映到包含這些關鍵字的文件中。
每個索引儲存在1個或者多個主分片,0個或者多個副本分片上。每個分片都是Lucene的一個完整例項,就像一個迷你搜索引擎。
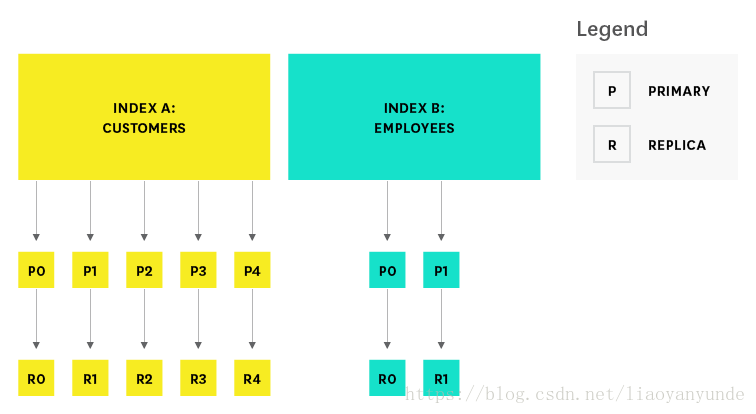
當我們建立一個索引的時候,我們可以指定主分片數和副本數。每個索引的主分片數預設是5,副本數預設是1.索引建立完成之後,主分片數不能更改,所以在建立索引的時候要謹慎選擇主分片數。副本數在索引建立之後可以根據需要進行更改。為保護資料不丟失,主節點會保證每個副本分片不會和主分片分配在同一個節點上。
二、 Elasticsearch關鍵效能監測指標
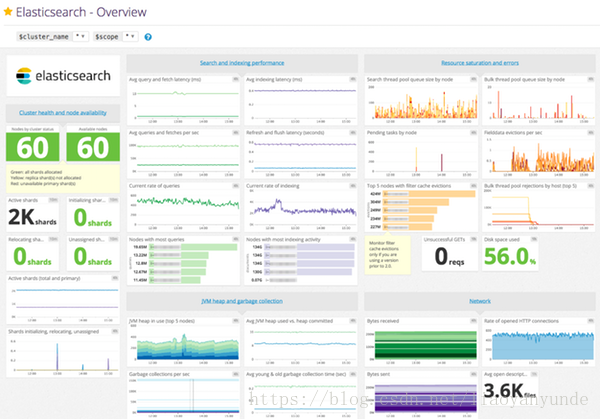
Elasticsearch提供了大量可以幫助你發現故障跡象的指標,當你遇到節點不可用、記憶體溢位錯誤、長時間GC的問題時,可以採取相應措施。需要監測的幾個關鍵點如下:
- 搜尋(查詢資料)/索引(插入更新資料)效能
- 記憶體和gc
- 伺服器和網路指標
- 叢集健康狀態和節點可用性
- 資源飽和情況和錯誤
所有這些指標均可以通過Elasticsearch的API、單一用途的監測工具如Elastic’s Marvel或者通用監控服務Datadog來獲取。更多的關於怎麼收集這些指標的方法,詳見第二部分
2.1 搜尋效能指標Search performance metrics
搜尋請求是Elasticsearch中兩個主要請求之一,另一個是索引請求。這兩個請求分別有點類似於傳統資料庫系統的讀請求和寫請求。Elasticsearch提供的指標與搜尋過程的兩個主要階段相對應(query和fetch)。如下圖展示了搜尋請求從開始到結束的過程。
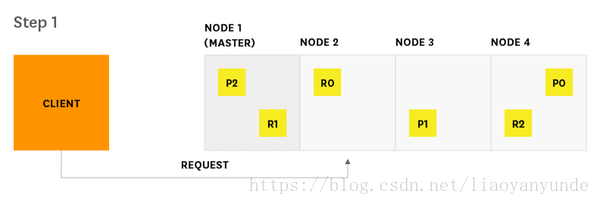
1、客戶端傳送一個搜尋請求到節點2
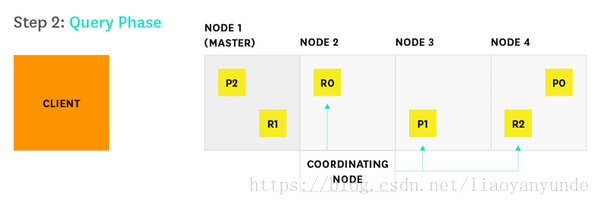
2、節點2(協調節點)將查詢傳送到索引中的每個分片的副本(副本或主分片)上。
例如,索引a分片數為3,副本數為1,相當於3個分片分別有1個副本,其中一個主分片,一個是副本,那麼一共有3+3=6個分片,請求只會發給每個分片的主分片或者副本中的一個,就是發出的是3個請求,而不是6個請求。
如上圖所示,對於分片0來說,存有兩份資料P0和R0,如果請求發給了R0,就不會再發送給P0。
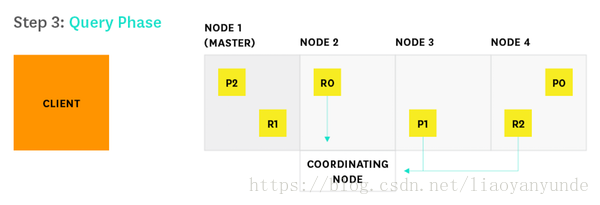
3、每個分片在本地執行查詢並將結果交付給節點2。節點2將它們排序並編譯成全域性優先佇列。
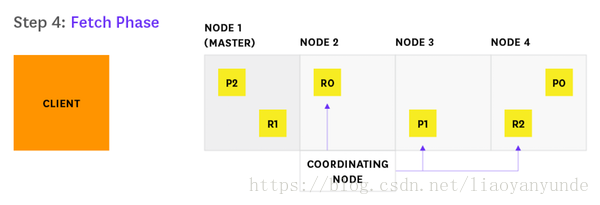
4、節點2發現需要獲取哪些文件,並向相關分片傳送多GET請求。
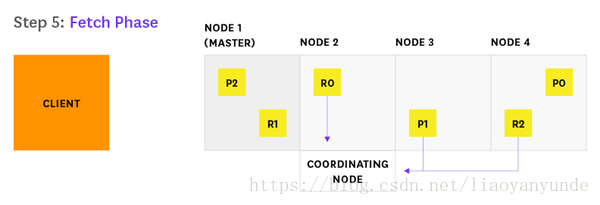
5、每個分片下載文件並將其返回給節點2
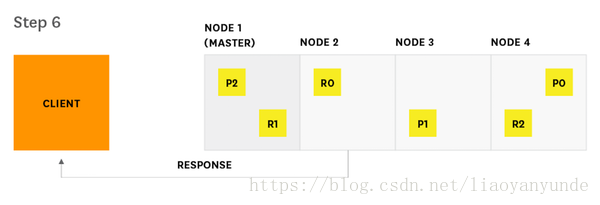
6、節點2向客戶端交付搜尋結果。
如果你是用Elasticsearch主要是用於搜尋,或者搜尋是對你的公司很關鍵的面向客戶特色,你應該監視查詢延遲,並在超過閾值時採取行動。監測有關查詢(query)和獲取(fetch)的相關指標非常重要,這些指標可以幫助確定搜尋在一段時間內的執行情況。例如,你可能希望跟蹤查詢請求的峰值和長期增長請客,以便可以調整配置以優化效能和可靠性。
| 指標描述 | 名稱 | 指標型別 |
|---|---|---|
| Total number of queries | indices.search.query_total | Work: Throughput |
| Total time spent on queries | indices.search.query_time_in_millis | Work: Performance |
| Number of queries currently in progress 當前正在進行的查詢數量 | indices.search.query_current | Work: Throughput |
| Total number of fetches | indices.search.fetch_total | Work: Throughput |
| Total time spent on fetches | indices.search.fetch_time_in_millis | Work: Performance |
| Number of fetches currently in progress | indices.search.fetch_current | Work: Throughput |
搜尋要觀察的效能指標
查詢負載:
監視“當前正在進行的查詢數量”可以讓您大致瞭解叢集在任何特定時刻正在處理多少請求。考慮在出現不尋常的尖峰或尖峰可能指向潛在的問題時發出警報。你可能還希望監視搜尋執行緒池佇列的大小,我們將在本文後面詳細解釋這一點。
查詢延遲:
儘管Elasticsearch沒有明確地提供這個指標,但是監視工具可以幫助你使用可用的指標,通過定期取樣查詢總數和總執行時間來計算平均查詢延遲。如果延遲超過閾值,則設定警報,如果觸發警報,則查詢潛在的資源瓶頸,或調查是否需要優化查詢。
獲取延遲:
搜尋過程的第二部分,即獲取階段,通常比查詢階段花費的時間要少得多。如果你注意到這個指標持續增加,這可能表明磁碟速度緩慢、文件內容豐富(在搜尋結果中突出顯示相關文字等)或請求太多文件。
2.2 索引的效能指標
索引請求類似於傳統資料庫系統中的寫請求,如果你的Elasticsearch工作負載很大,那麼重要的是要監視和分析你如何有效地使用新資訊更新索引。在討論指標之前,我們先來看看Elasticsearch更新索引的過程。當向索引中新增新資訊或更新或刪除現有資訊時,通過兩個過程更新索引中的每個分片:refresh和fresh。
索引refresh
新索引的文件不能立即用於搜尋。首先,它們被寫入記憶體緩衝區,等待下一次索引refresh,預設情況下每秒refresh一次。refresh程序從記憶體緩衝區的內容中建立一個新的記憶體段(使新索引的文件可搜尋),然後清空緩衝區,如下所示:
索引refresh的過程
索引的分片由多個段組成。段是Lucene的核心資料結構,一個段本質上是索引的變更集。這些段在每次refresh時建立,然後在後臺隨著時間的推移合併在一起,以確保資源的有效使用(每個段使用檔案控制代碼、記憶體和CPU)。
段是將關鍵字對映到包含這些關鍵字的文件的迷你倒排索引。每次搜尋索引時,每個分片的主版本或副本版本都必須依次搜尋該分片中的每個段。
段是不可變的,所以更新文件意味著:
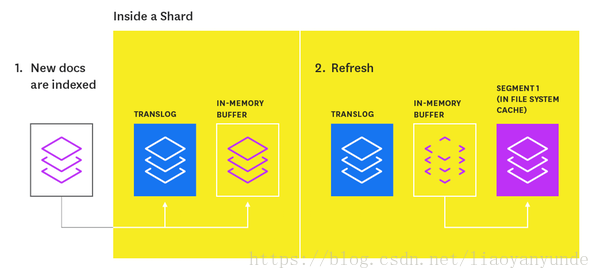
- 在重新整理過程中將資訊寫入新段
- 將舊資訊標記為已刪除
當過時的段與另一個段合併時,舊的資訊最終會被刪除。
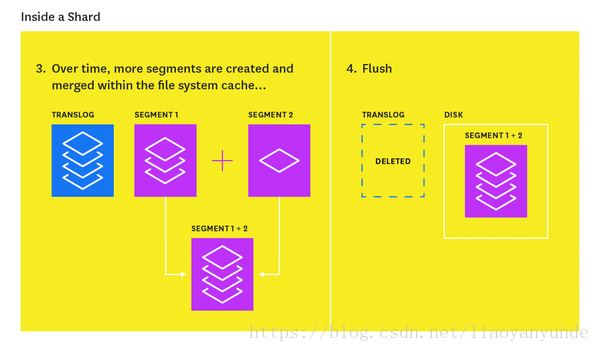
索引flush
在新索引的文件被新增到記憶體緩衝區中的同時,它們也被新增到分片的translog中:一個持久的、預寫的操作事務日誌。每30分鐘,或者當translog達到最大大小(預設值為512MB)時,就會觸發flush。在flush期間,記憶體緩衝區中的所有文件都被重新整理(儲存在新段上),所有在記憶體緩衝區中的段都被提交到磁碟,translog被清除。
translog有助於防止節點失敗時的資料丟失。它的設計目的是幫助分片恢復可能在重新整理之間丟失的操作。日誌每5秒鐘提交一次到磁碟,或者在每次成功的索引、刪除、更新或批量請求(無論哪個先出現)時提交。
flush過程如下圖所示:
索引flush的過程
Elasticsearch提供了許多指標,你可以使用這些指標來評估索引效能並優化更新索引的方式。
| 指標描述 | 名稱 | 指標型別 |
|---|---|---|
| Total number of documents indexed | indices.indexing.index_total | Work: Throughput |
| Total time spent indexing documents | indices.indexing.index_time_in_millis | Work: Performance |
| Number of documents currently being indexed | indices.indexing.index_current | Work: Throughput |
| Total number of index refreshes | indices.refresh.total | Work: Throughput |
| Total time spent refreshing indices | indices.refresh.total_time_in_millis | Work: Performance |
| Total number of index flushes to disk | indices.flush.total | Work: Throughput |
| Total time spent on flushing indices to disk | indices.flush.total_time_in_millis | Work: Performance |
索引要監視的效能指標
索引延遲
Elasticsearch並不直接提供這個特定的指標,但是監視工具可以幫助我們從可用的index_total和index_time_in_millis指標計算平均索引延遲。如果你注意到延遲的增加,那麼你可能一次索引了太多的文件(Elasticsearch的文件建議從5到15 mb的批量索引大小開始,然後慢慢增加)。
如果你計劃對許多文件進行索引,並且不需要立即獲得新的資訊來進行搜尋,那麼可以通過減少重新整理頻率來優化索引效能而不是搜尋效能,直到完成索引為止。索引設定API允許您臨時禁用重新整理間隔:
curl -XPUT <nameofhost>:9200/<name_of_index>/_settings -d '{ "index" : { "refresh_interval" : "-1" } }'
索引完成後,可以恢復到“1”的預設值。本系列的第4部分將更詳細地介紹這個和其他索引效能技巧。
Flush延遲
因為在重新整理成功完成之前,資料不會持久化到磁碟中,所以如果效能開始下降,跟蹤重新整理延遲並採取行動是很有用的。如果你看到這個指標穩步增長,它可能表明磁碟速度慢的問題;這個問題可能會升級,最終會阻止您向索引中新增新資訊。您可以嘗試在索引的重新整理設定中降低index.translog.flush_threshold_size。這個設定決定觸發flush之前的translog大小。但是,如果你是寫操作密集的Elasticsearch使用者,你應該使用iostat或Datadog代理之類的工具來長期監視磁碟IO指標,並在需要時考慮升級磁碟。
2.3 記憶體使用和GC垃圾回收
執行Elasticsearch時,記憶體是我們最想密切監測的主要資源之一。Elasticsearch和Lucene以兩種方式利用節點上所有可用的RAM:JVM堆和檔案系統快取。Elasticsearch在Java虛擬機器(JVM)中執行,這意味著JVM垃圾收集的持續時間和頻率將是另一個需要監視的重要領域。
JVM堆:一個金髮女孩的故事
Elasticsearch強調JVM堆大小“剛剛好”的重要性,不希望將它設定得太大或太小。一般來說,Elasticsearch的經驗法則是分配給JVM堆記憶體要不能大於可用RAM的50%,並且永遠不會超過32gb。
為Elasticsearch分配的堆記憶體越少,Lucene就可以使用越多的RAM,它嚴重依賴於檔案系統快取來快速服務請求。但是,你也不希望將堆大小設定得太小,因為你可能會遇到記憶體不足的錯誤或吞吐量降低的問題,因為應用程式會面臨頻繁的垃圾回收(GC)造成的持續的短時間停頓。請參考Elasticsearch的一位核心工程師編寫的指南,以找到確定正確堆大小的提示。
Elasticsearch的預設安裝設定的JVM堆大小為1g,對於大多數用例來說太小了。可以export想要的堆大小作為環境變數,並重新啟動Elasticsearch:
$ export ES_HEAP_SIZE=10g
另一個選項是在每次啟動Elasticsearch時在命令列中設定JVM堆大小(大小相等,以防止堆大小調整):
$ ES_HEAP_SIZE="10g" ./bin/elasticsearch
在兩個示例中,我們都將堆大小設定為10gb。要驗證更新成功,執行:
$ curl -XGET http://<nameofhost>:9200/_cat/nodes?h=heap.max
輸出應該顯示正確更新的最大堆值。
GC
Elasticsearch依賴於垃圾回收程序來釋放堆記憶體。如果您想了解更多關於JVM垃圾收集的知識,請參閱本指南。
因為垃圾回收使用資源(為了釋放資源!),所以你應該關注它的頻率和持續時間,看看是否需要調整堆大小。設定堆太大會導致垃圾收集時間過長;這些過多的停頓是危險的,因為它們可能導致叢集錯誤地將節點註冊為已從網格中刪除的節點,就是認為節點已經掛了。
| 指標描述 | 名稱 | 指標型別 |
|---|---|---|
| Total count of young-generation garbage collections | jvm.gc.collectors.young.collection_count (jvm.gc.collectors.ParNew.collection_count prior to vers. 0.90.10) | Other |
| Total time spent on young-generation garbage collections | jvm.gc.collectors.young.collection_time_in_millis (jvm.gc.collectors.ParNew.collection_time_in_millis prior to vers. 0.90.10) | Other |
| Total count of old-generation garbage collections | jvm.gc.collectors.old.collection_count (jvm.gc.collectors.ConcurrentMarkSweep.collection_count prior to vers. 0.90.10) | Other |
| Total time spent on old-generation garbage collections | jvm.gc.collectors.old.collection_time_in_millis (jvm.gc.collectors.ConcurrentMarkSweep.collection_time_in_millis prior to vers. 0.90.10) | Other |
| Percent of JVM heap currently in use | jvm.mem.heap_used_percent | Resource: Utilization |
| Amount of JVM heap committed | jvm.mem.heap_committed_in_bytes | Resource: Utilization |
要觀察的JVM指標

使用中的JVM堆:
當JVM堆使用率達到75%時,Elasticsearch將啟動垃圾回收。如上所示,監視哪個節點顯示了較高的堆使用率,並設定一個警報,以查明任何節點是否一直地使用了超過85%的堆記憶體,這可能是有用的;這表明垃圾回收的速度趕不上垃圾建立的速度。要解決這個問題,您可以增加堆大小(只要它仍然低於上面所述的推薦準則),或者通過新增更多節點來擴充套件叢集。
使用的JVM堆與提交的JVM堆:
與提交的記憶體(保證可用的記憶體)相比,瞭解JVM堆當前使用了多少記憶體是很有幫助的。在使用中的堆記憶體數量通常會呈現鋸齒狀,當垃圾累積時,這種情況會上升,當垃圾回收時,這種情況會下降。如果曲線隨著時間的推移開始向上傾斜,這意味著垃圾回收的速度趕不上物件建立的速度,這會導致垃圾收集時間變慢,最終導致OutOfMemoryErrors。
垃圾收集的持續時間和頻率:
新生代和年老代的垃圾回收器都會經歷“停止所有”的階段,因為JVM會暫停程式的執行,以收集死物件。在此期間,節點無法完成任何任務。因為主節點每隔30秒檢查其他節點的狀態,如果任何節點的垃圾收集時間超過30秒,主節點就會認為節點掛了。
記憶體使用
如上所述,Elasticsearch很好地利用了任何沒有分配給JVM堆的RAM。與Kafka一樣,Elasticsearch的設計依賴於作業系統的檔案系統快取來快速可靠地服務請求。
許多變數決定Elasticsearch是否能從檔案系統快取中成功讀取。如果段檔案是最近通過Elasticsearch寫入磁碟的,那麼它已經在快取中了。但是,如果節點已被關閉並重啟,那麼第一次查詢段時,很可能必須從磁碟讀取資訊。這是確保叢集保持穩定和節點不會崩潰的重要原因之一。
通常,監控節點上的記憶體使用情況非常重要,並儘可能多地提供給Elasticsearch,這樣它就可以利用檔案系統快取的速度,而不會耗盡空間。
2.4 主機級網路和系統指標
| Name | Metric type |
|---|---|
| Available disk space | Resource: Utilization |
| I/O utilization | Resource: Utilization |
| CPU usage | Resource: Utilization |
| Network bytes sent/received | Resource: Utilization |
| Open file descriptors | Resource: Utilization |
當Elasticsearch通過API提供許多特定於應用程式的指標時,您還應該從每個節點收集和監視幾個主機級指標。
要警告的主機指標
磁碟空間:
如果Elasticsearch叢集的寫操作很頻繁,那麼這個指標就特別重要。你不希望耗盡磁碟空間,如此將會無法插入或更新任何內容,而且節點將失敗。如果一個節點上可用的磁碟少於20%,您可能希望使用Curator之類的工具刪除該節點上佔用太多寶貴磁碟空間的某些索引。
如果不能刪除索引,另一種選擇是新增更多節點,並讓主節點自動在新節點之間重新分配分片(儘管您應該注意到這為繁忙的主節點建立了額外的工作)。另外,要記住,帶有分析欄位(需要文字分析的欄位——標記、刪除標點符號等)的文件要比包含非分析欄位(精確值)的文件佔用更多的磁碟空間。
要監視的主機指標
I/O利用率:
隨著段的建立、查詢和合並,Elasticsearch對磁碟進行大量的讀寫操作。對於具有不斷經歷大量I/O活動的節點的寫密集型叢集,Elasticsearch建議使用ssd來提高效能。
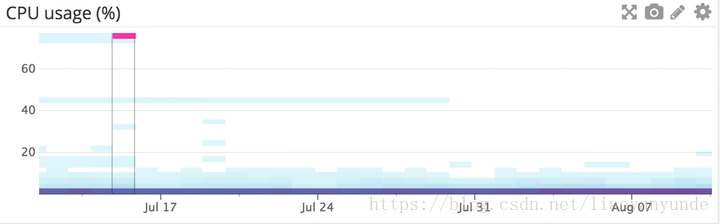
節點上的CPU利用率:
對於每個節點型別,在熱圖中視覺化CPU使用情況(如上面所示)是很有幫助的。例如,您可以建立三個不同的圖來表示叢集中的每一組節點(例如資料節點、master- qualified節點和客戶機節點),以檢視一種型別的節點是否在與另一種節點相比的活動中過載。如果您看到CPU使用量增加,這通常是由繁重的搜尋或索引工作負載引起的。設定一個通知,以確定節點的CPU使用率是否一直在增加,並新增更多的節點以重新分配負載。
網路位元組傳送/接收:
節點間的通訊是平衡叢集的關鍵組成部分。你需要監視網路,以確保它是健康的,並且能夠滿足叢集的需求(例如,在節點之間複製或重新平衡分片)。Elasticsearch提供了關於叢集通訊的傳輸度量,但是你還可以檢視傳送和接收的位元組數,以檢視你的網路正在接收多少流量。
開啟的檔案描述符:
檔案描述符用於節點到節點通訊、客戶端連線和檔案操作。如果這個數字達到了系統的最大容量,那麼新的連線和檔案操作在舊的連線關閉之前是不可能的。如果超過80%的可用檔案描述符在使用中,您可能需要增加系統的最大檔案描述符計數。大多數Linux系統每個程序只允許1024個檔案描述符。當在生產環境中使用Elasticsearch時,您應該將OS檔案描述符計數重置為更大的數,比如64000。
HTTP連線
| 指標描述 | 名稱 | 指標型別 |
|---|---|---|
| Number of HTTP connections currently open | http.current_open | Resource: Utilization |
| Total number of HTTP connections opened over time | http.total_opened | Resource: Utilization |
除了Java之外,任何語言傳送的請求都可以通過HTTP使用RESTful API與Elasticsearch通訊。如果開啟的HTTP連線的總數不斷增加,這可能表明HTTP客戶端沒有正確地建立持久連線。重新建立連線會增加額外的毫秒甚至秒的請求響應時間。確保正確地配置了客戶端以避免對效能產生負面影響,或者使用官方的Elasticsearch客戶端,它已經正確地配置了HTTP連線。
2.5 叢集健康和節點可用性
| 指標描述 | 名稱 | 指標型別 |
|---|---|---|
| Cluster status (green, yellow, red) | cluster.health.status | Other |
| Number of nodes | cluster.health.number_of_nodes | Resource: Availability |
| Number of initializing shards | cluster.health.initializing_shards | Resource: Availability |
| Number of unassigned shards | cluster.health.unassigned_shards | Resource: Availability |
叢集狀態:
如果叢集狀態為黃色,則至少有一個副本分片未分配或丟失。搜尋結果仍然完整,但如果更多的分片消失,可能會丟失資料。
初始化和未分配分片:
第一次建立索引或重啟節點時,其分片將在轉換到“已啟動”或“未分配”狀態之前短暫地處於“初始化”狀態,因為主節點試圖將分片分配給叢集中的節點。如果分片停留在初始化或未分配的狀態太長,這可能是叢集不穩定的警告訊號。
2.6 資源飽和和錯誤
Elasticsearch節點使用執行緒池來管理執行緒如何消耗記憶體和CPU。由於執行緒池設定是根據處理器數量自動配置的,因此調整它們通常沒有意義。但是,最好關注執行緒池佇列和拒絕,看看節點是否跟不上;如果是這樣,可能需要新增更多節點來處理所有併發請求。欄位資料和過濾快取的使用是另一個需要監視的領域,因為退出可能指向低效的查詢或記憶體壓力的跡象。
執行緒池佇列和拒絕
每個節點維護許多型別的執行緒池;你想要監視的精確值將取決於你對Elasticsearch的特定使用。通常,要監視的最重要的操作是搜尋、索引、合併和批量,這與請求型別(搜尋、索引、合併和批量操作)對應。
每個執行緒池的佇列的大小表示節點當前處於可用狀態時等待服務的請求數量。佇列允許節點跟蹤並最終服務於這些請求,而不是丟棄它們。一旦達到執行緒池的最大佇列大小(根據執行緒池的型別而變化),就會出現執行緒池拒絕。
| 指標描述 | 名稱 | 指標型別 |
|---|---|---|
| Number of queued threads in a thread pool | thread_pool.bulk.queue thread_pool.index.queue thread_pool.search.queue thread_pool.merge.queue | Resource: Saturation |
| Number of rejected threads a thread pool | thread_pool.bulk.rejected thread_pool.index.rejected thread_pool.search.rejected thread_pool.merge.rejected | Resource: Error |
需要監控的指標
執行緒池佇列:
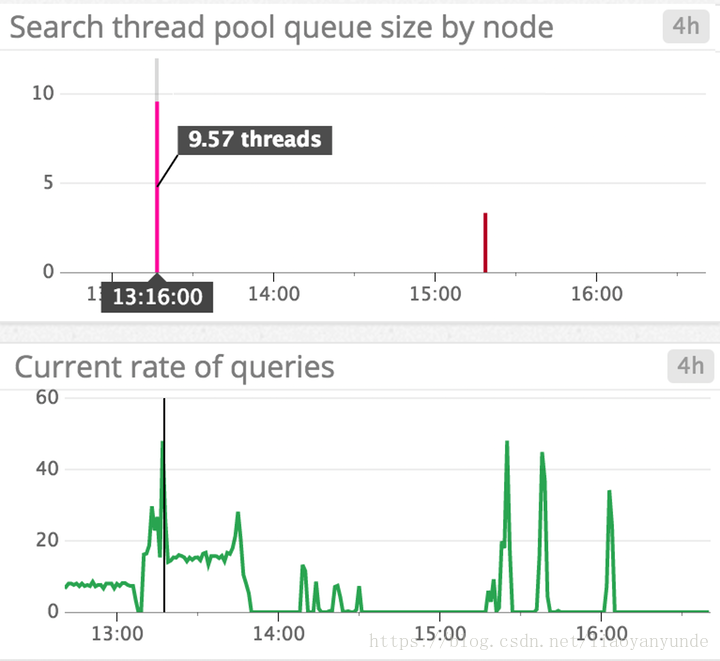
大型佇列並不理想,因為它們會耗盡資源,而且如果節點宕機,還會增加丟失請求的風險。如果您看到排隊的執行緒和被拒絕的執行緒的數量在穩步增加,您可能希望嘗試減慢請求速度(如果可能的話)、增加節點上的處理器數量或增加叢集中的節點數量。如下面的截圖所示,查詢載入峰值與搜尋執行緒池佇列大小的峰值相關,因為節點試圖跟上查詢請求的速度。
批量拒絕和批量佇列:
批量操作是一次傳送多個請求的更有效方式。通常,如果您想執行許多操作(建立索引,或新增、更新或刪除文件),您應該嘗試將請求作為批量操作傳送,而不是作為多個單獨的請求。
批量拒絕通常與試圖在一個批量請求中索引太多文件有關。根據Elasticsearch的文件,批量拒絕並不一定需要擔心。但是,你應該嘗試執行線性或指數回退策略,以有效地處理批量拒絕。
快取使用指標
每個查詢請求被髮送到索引中的每個分片,然後這些分片命中每個分片的每個段。Elasticsearch以每段為基礎快取查詢,以加快響應時間。另一方面,如果快取佔用了太多的堆,它們可能會減慢速度而不是加快速度!
在Elasticsearch中,文件中的每個欄位可以以兩種形式之一儲存:精確值或全文。精確值,例如時間戳或一年,是按照索引的方式儲存的,因為您不希望收到查詢1/1/16的查詢,比如“2016年1月1日”。如果一個欄位儲存為全文,這意味著它將被分析—基本上,它將被分解成片語,並且,根據分析器的型別,標點和停止詞,如“是”或“the”可能被刪除。分析器將欄位轉換為規範化格式,使其能夠匹配更廣泛的查詢。
例如,假設有一個索引,其中包含一個名為location的型別;型別location的每個文件都包含一個欄位city,它被儲存為一個分析字串。你將索引兩個文件:一個在city欄位是“St. Louis” 另一個是 “St. Paul”.。每個字串都將被小寫化並轉換為片語,且不使用標點符號。這些術語儲存在一個倒排索引中,它看起來像這樣:
| Term | Doc1 | Doc2 |
|---|---|---|
| st | x | x |
| louis | x | |
| paul | x |
分析的好處是你可以搜尋“st”。結果會顯示,這兩份檔案都包含這個詞。如果將city欄位儲存為精確值,則必須搜尋精確的詞“St. Louis”或者 “St. Paul”,以檢視生成的文件。
Elasticsearch使用兩種主要型別的快取更快地為搜尋請求提供服務:欄位資料(Fielddata )和過濾器(filter)。
Fielddata快取
Fielddata快取是在對欄位進行排序或聚合時使用的,這個過程基本上需要反轉倒排索引,以按照文件順序建立每個欄位的每個欄位值的陣列。例如,如果我們想從上面的例子中找到任何包含“st”的文件中唯一的術語列表,我們將:
1、掃描倒排索引以檢視哪些文件包含該詞(在本例中是Doc1和Doc2)
2、對於步驟1中找到的每個文件,遍歷索引中的每個詞,從該文件收集片語,建立如下結構:
| Doc | Terms |
|---|---|
| Doc1 | st, louis |
| Doc1 | st, paul |
3、現在倒排索引已經“非倒排”,編譯來自每個文件(st、louis和paul)的惟一片語。這樣編譯fielddata會消耗大量堆記憶體,尤其是使用大量文件和關鍵詞時更是如此。所有欄位值都載入到記憶體中。
對於1.3之前的版本,欄位資料快取大小是無限制的。從1.3版開始,Elasticsearch添加了一個欄位資料斷路器,如果查詢試圖載入需要超過60%堆的欄位資料,就會觸發該斷路器。
過濾器快取
過濾器快取也使用JVM堆。在2.0之前的版本中,Elasticsearch會自動快取篩選過的查詢,其最大值為堆的10%,並清除最近最少使用的資料。從2.0版本開始,Elasticsearch就根據頻率和段大小自動開始優化它的過濾快取(快取只發生在索引中文件總數少於10,000個或少於3%的段上)。因此,篩選快取指標只對使用的是2.0版本之前的Elasticsearch使用者可用。
例如,過濾器查詢只能返回年份欄位中的值在2000-2005範圍內的文件。在第一次執行過濾器查詢時,Elasticsearch將建立與過濾器匹配的文件的位集(如果文件匹配,為1,如果不匹配,為0)。具有相同過濾器的查詢的後續執行將重用此資訊。每當新增或更新新文件時,位集也會被更新。如果你使用的是2.0之前版本的Elasticsearch,那麼你應該關注過濾器快取以及回收指標(下面將對此進行詳細介紹)。
| 指標描述 | 名稱 | 指標型別 |
|---|---|---|
| Size of the fielddata cache (bytes) | indices.fielddata.memory_size_in_bytes | Resource: Utilization |
| Number of evictions from the fielddata cache | indices.fielddata.evictions | Resource: Saturation |
| Size of the filter cache (bytes) (only pre-version 2.x) | indices.filter_cache.memory_size_in_bytes | Resource: Utilization |
| Number of evictions from the filter cache (only pre-version 2.x) | indices.filter_cache.evictions | Resource: Saturation |
要監視的快取指標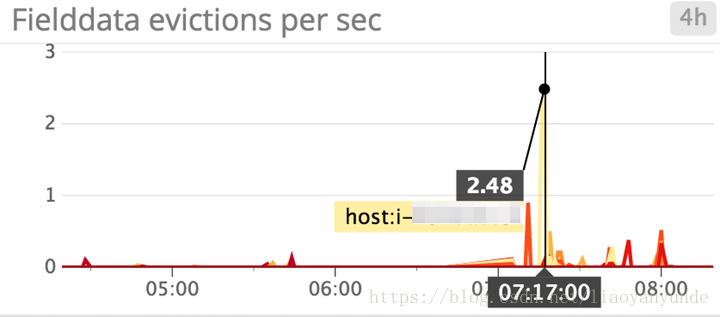
欄位資料快取收回:
理想情況下,您希望限制欄位資料收回的數量,因為它們是I/O密集型的。如果您看到了大量的收回,而此時又無法增加記憶體,Elasticsearch建議暫時將欄位資料快取限制在堆的20%;可以在config/elasticsearch.yml檔案中這樣。當fielddata達到堆的20%時,它將收回最近最少使用的fielddata,從而允許您將新的fielddata載入到快取中。
Elasticsearch還建議儘可能使用doc值,因為它們與欄位資料的用途相同。但是,因為它們儲存在磁碟上,所以它們不依賴於JVM堆。雖然doc值不能用作分析的字串欄位,但是在對其他型別的欄位進行聚合或排序時,它們確實節省了欄位資料的使用。在2.0或更高版本中,doc值在文件索引時自動構建,這減少了許多使用者的欄位資料/堆使用。但是,如果您使用的是1.0和2.0之間的版本,那麼你也可以從這個特性中獲益——只要記住啟用它們即可。
過濾器快取收回:
如前所述,只有使用2.0之前的Elasticsearch的版本時,過濾器快取收回指標才可用。每個段維護自己的過濾器快取。由於大規模的收回行動比小規模的更昂貴,因此沒有明確的方法來評估每次收回的嚴重程度。但是,如果您看到收回發生得更頻繁,這可能表明膩並沒有將過濾器用好——你可能只是頻繁地建立新過濾器並將舊過濾器收回,甚至違背了使用快取的目的。你可能需要考慮調整你的查詢(如使用bool查詢,而不是使用and or not 過濾器)
掛起任務
| 指標描述 | 名稱 | 指標型別 |
|---|---|---|
| Number of pending tasks | pending_task_total | Resource: Saturation |
| Number of urgent pending tasks | pending_tasks_priority_urgent | Resource: Saturation |
| Number of high-priority pending tasks | pending_tasks_priority_high | Resource: Saturation |
掛起的任務只能由主節點處理。這些任務包括建立索引和向節點分配分片。掛起的任務以優先順序順序處理——先來的,優先順序最高。當更改的數量發生得比主程式處理它們的速度快時,它們就開始累積。如果這個指標持續增加,你就需要關注它。掛起任務的數量很好地顯示了叢集執行的平穩性。如果主節點非常繁忙,掛起的任務數量沒有減少,則可能導致不穩定的叢集。
不成功的GET請求
| 指標描述 | 名稱 | 指標型別 |
|---|---|---|
| Total number of GET requests where the document was missing | indices.get.missing_total | Work: Error |
| Total time spent on GET requests where the document was missing | indices.get.missing_time_in_millis | Work: Error |
GET請求比普通的搜尋請求更直接——它根據文件的ID檢索文件。對於這種型別的請求,您通常不會有什麼問題,但是在出現未成功的GET請求時,最好注意一下。
結論
在這篇文章中,我們介紹了對Elasticseach進行監控的一些重要方面:
- 搜尋(查詢資料)/索引(插入更新資料)效能
- 記憶體和gc
- 伺服器和網路指標
- 叢集健康狀態和節點可用性
- 資源飽和情況和錯誤
當您監視Elasticsearch指標和節點級系統指標時,你就會發現哪些區域對您的特定場景最有意義。閱讀本系列文章的第2部分,瞭解如何開始收集和視覺化對您最重要的Elasticsearch指標。