
(轉)SQLServer_十步優化SQL Server中的數據訪問 二
原文地址:http://tech.it168.com/a2009/1125/814/000000814758_all.shtml
第五步:識別低效TSQL,采用最佳實踐重構和應用TSQL
由於每個程序員的能力和習慣都不一樣,他們編寫的TSQL可能風格各異,部分代碼可能不是最佳實現,對於水平一般的程序員可能首先想到的是編寫TSQL實現需求,至於性能問題日後再說,因此在開發和測試時可能發現不了問題。
也有一些人知道最佳實踐,但在編寫代碼時由於種種原因沒有采用最佳實踐,等到用戶發飆的那天才乖乖地重新埋頭思考最佳實踐。
我覺得還是有必要介紹一下具有都有哪些最佳實踐。
1、在查詢中不要使用“select *”
(1)檢索不必要的列會帶來額外的系統開銷,有句話叫做“該省的則省”;
(2)數據庫不能利用“覆蓋索引”的優點,因此查詢緩慢。
2、在select清單中避免不必要的列,在連接條件中避免不必要的表
(1)在select查詢中如有不必要的列,會帶來額外的系統開銷,特別是LOB類型的列;
(2)在連接條件中包含不必要的表會強制數據庫引擎檢索和匹配不需要的數據,增加了查詢執行時間。
3、不要在子查詢中使用count()求和執行存在性檢查
(1)不要使用
SELECT column_list FROM table WHERE 0 < (SELECT count(*) FROM table2 WHERE ..)使用
代替;
(2)當你使用count()時,SQL Server不知道你要做的是存在性檢查,它會計算所有匹配的值,要麽會執行全表掃描,要麽會掃描最小的非聚集索引;
(3)當你使用EXISTS時,SQL Server知道你要執行存在性檢查,當它發現第一個匹配的值時,就會返回TRUE,並停止查詢。類似的應用還有使用IN或ANY代替count()。
4、避免使用兩個不同類型的列進行表的連接
(1)當連接兩個不同類型的列時,其中一個列必須轉換成另一個列的類型,級別低的會被轉換成高級別的類型,轉換操作會消耗一定的系統資源;
(2)如果你使用兩個不同類型的列來連接表,其中一個列原本可以使用索引,但經過轉換後,優化器就不會使用它的索引了。例如:
SELECT column_list FROM small_table, large_table WHEREsmalltable.float_column = large_table.int_column
在這個例子中,SQL Server會將int列轉換為float類型,因為int比float類型的級別低,large_table.int_column上的索引就不會被使用,但smalltable.float_column上的索引可以正常使用。
5、避免死鎖
(1)在你的存儲過程和觸發器中訪問同一個表時總是以相同的順序;
(2)事務應經可能地縮短,在一個事務中應盡可能減少涉及到的數據量;
(3)永遠不要在事務中等待用戶輸入。
6、使用“基於規則的方法”而不是使用“程序化方法”編寫TSQL
(1)數據庫引擎專門為基於規則的SQL進行了優化,因此處理大型結果集時應盡量避免使用程序化的方法(使用遊標或UDF[User Defined Functions]處理返回的結果集) ;
(2)如何擺脫程序化的SQL呢?有以下方法:
- 使用內聯子查詢替換用戶定義函數;
- 使用相關聯的子查詢替換基於遊標的代碼;
- 如果確實需要程序化代碼,至少應該使用表變量代替遊標導航和處理結果集。
7、避免使用count(*)獲得表的記錄數
(1)為了獲得表中的記錄數,我們通常使用下面的SQL語句:
SELECT COUNT(*) FROM dbo.orders這條語句會執行全表掃描才能獲得行數。
(2)但下面的SQL語句不會執行全表掃描一樣可以獲得行數:
SELECT rows FROM sysindexesWHERE id = OBJECT_ID(‘dbo.Orders‘) AND indid < 2
8、避免使用動態SQL
除非迫不得已,應盡量避免使用動態SQL,因為:
(1)動態SQL難以調試和故障診斷;
(2)如果用戶向動態SQL提供了輸入,那麽可能存在SQL註入風險。
9、避免使用臨時表
(1)除非卻有需要,否則應盡量避免使用臨時表,相反,可以使用表變量代替;
(2)大多數時候(99%),表變量駐紮在內存中,因此速度比臨時表更快,臨時表駐紮在TempDb數據庫中,因此臨時表上的操作需要跨數據庫通信,速度自然慢。
10、使用全文搜索搜索文本數據,取代like搜索
全文搜索始終優於like搜索:
(1)全文搜索讓你可以實現like不能完成的復雜搜索,如搜索一個單詞或一個短語,搜索一個與另一個單詞或短語相近的單詞或短語,或者是搜索同義詞;
(2)實現全文搜索比實現like搜索更容易(特別是復雜的搜索);
11、使用union實現or操作
(1)在查詢中盡量不要使用or,使用union合並兩個不同的查詢結果集,這樣查詢性能會更好;
(2)如果不是必須要不同的結果集,使用union all效果會更好,因為它不會對結果集排序。
12、為大對象使用延遲加載策略
(1)在不同的表中存儲大對象(如VARCHAR(MAX),Image,Text等),然後在主表中存儲這些大對象的引用;
(2)在查詢中檢索所有主表數據,如果需要載入大對象,按需從大對象表中檢索大對象。
13、使用VARCHAR(MAX),VARBINARY(MAX) 和 NVARCHAR(MAX)
(1)在SQL Server 2000中,一行的大小不能超過800字節,這是受SQL Server內部頁面大小8KB的限制造成的,為了在單列中存儲更多的數據,你需要使用TEXT,NTEXT或IMAGE數據類型(BLOB);
(2)這些和存儲在相同表中的其它數據不一樣,這些頁面以B-Tree結構排列,這些數據不能作為存儲過程或函數中的變量,也不能用於字符串函數,如REPLACE,CHARINDEX或SUBSTRING,大多數時候你必須使用READTEXT,WRITETEXT和UPDATETEXT;
(3)為了解決這個問題,在SQL Server 2005中增加了VARCHAR(MAX),VARBINARY(MAX) 和 NVARCHAR(MAX),這些數據類型可以容納和BLOB相同數量的數據(2GB),和其它數據類型使用相同的數據頁;
(4)當MAX數據類型中的數據超過8KB時,使用溢出頁(在ROW_OVERFLOW分配單元中)指向源數據頁,源數據頁仍然在IN_ROW分配單元中。
14、在用戶定義函數中使用下列最佳實踐
不要在你的存儲過程,觸發器,函數和批處理中重復調用函數,例如,在許多時候,你需要獲得字符串變量的長度,無論如何都不要重復調用LEN函數,只調用一次即可,將結果存儲在一個變量中,以後就可以直接使用了。
15、在存儲過程中使用下列最佳實踐
(1)不要使用SP_xxx作為命名約定,它會導致額外的搜索,增加I/O(因為系統存儲過程的名字就是以SP_開頭的),同時這麽做還會增加與系統存儲過程名稱沖突的幾率;
(2)將Nocount設置為On避免額外的網絡開銷;
(3)當索引結構發生變化時,在EXECUTE語句中(第一次)使用WITH RECOMPILE子句,以便存儲過程可以利用最新創建的索引;
(4)使用默認的參數值更易於調試。
16、在觸發器中使用下列最佳實踐
(1)最好不要使用觸發器,觸發一個觸發器,執行一個觸發器事件本身就是一個耗費資源的過程;
(2)如果能夠使用約束實現的,盡量不要使用觸發器;
(3)不要為不同的觸發事件(Insert,Update和Delete)使用相同的觸發器;
(4)不要在觸發器中使用事務型代碼。
17、在視圖中使用下列最佳實踐
(1)為重新使用復雜的TSQL塊使用視圖,並開啟索引視圖;
(2)如果你不想讓用戶意外修改表結構,使用視圖時加上SCHEMABINDING選項;
(3)如果只從單個表中檢索數據,就不需要使用視圖了,如果在這種情況下使用視圖反倒會增加系統開銷,一般視圖會涉及多個表時才有用。
18、在事務中使用下列最佳實踐
(1)SQL Server 2005之前,在BEGIN TRANSACTION之後,每個子查詢修改語句時,必須檢查@@ERROR的值,如果值不等於0,那麽最後的語句可能會導致一個錯誤,如果發生任何錯誤,事務必須回滾。從SQL Server 2005開始,Try..Catch..代碼塊可以處理TSQL中的事務,因此在事務型代碼中最好加上Try…Catch…;
(2)避免使用嵌套事務,使用@@TRANCOUNT變量檢查事務是否需要啟動(為了避免嵌套事務);
(3)盡可能晚啟動事務,提交和回滾事務要盡可能快,以減少資源鎖定時間。
要完全列舉最佳實踐不是本文的初衷,當你了解了這些技巧後就應該拿來使用,否則了解了也沒有價值。此外,你還需要評審和監視數據訪問代碼是否遵循下列標準和最佳實踐。
如何分析和識別你的TSQL中改進的範圍?
理想情況下,大家都想預防疾病,而不是等病發了去治療。但實際上這個願望根本無法實現,即使你的團隊成員全都是專家級人物,我也知道你有進行評審,但代碼仍然一團糟,因此需要知道如何治療疾病一樣重要。
首先需要知道如何診斷性能問題,診斷就得分析TSQL,找出瓶頸,然後重構,要找出瓶頸就得先學會分析執行計劃。
理解查詢執行計劃
當你將SQL語句發給SQL Server引擎後,SQL Server首先要確定最合理的執行方法,查詢優化器會使用很多信息,如數據分布統計,索引結構,元數據和其它信息,分析多種可能的執行計劃,最後選擇一個最佳的執行計劃。
可以使用SQL Server Management Studio預覽和分析執行計劃,寫好SQL語句後,點擊SQL Server Management Studio上的評估執行計劃按鈕查看執行計劃,如圖1所示。
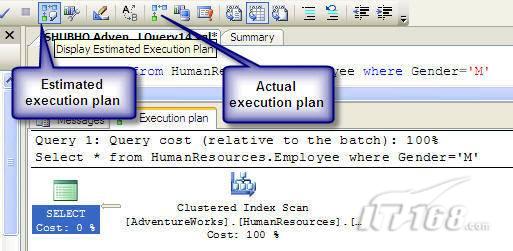
圖 1 在Management Studio中評估執行計劃
在執行計劃圖中的每個圖標代表計劃中的一個行為(操作),應從右到左閱讀執行計劃,每個行為都一個相對於總體執行成本(100%)的成本百分比。
在上面的執行計劃圖中,右邊的那個圖標表示在HumanResources表上的一個“聚集索引掃描”操作(閱讀表中所有主鍵索引值),需要100%的總體查詢執行成本,圖中左邊那個圖標表示一個select操作,它只需要0%的總體查詢執行成本。
下面是一些比較重要的圖標及其對應的操作:
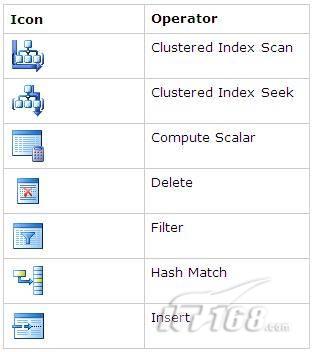
圖 2 常見的重要圖標及對應的操作
註意執行計劃中的查詢成本,如果說成本等於100%,那很可能在批處理中就只有這個查詢,如果在一個查詢窗口中有多個查詢同時執行,那它們肯定有各自的成本百分比(小於100%)。
如果想知道執行計劃中每個操作詳細情況,將鼠標指針移到對應的圖標上即可,你會看到類似於下面的這樣一個窗口。
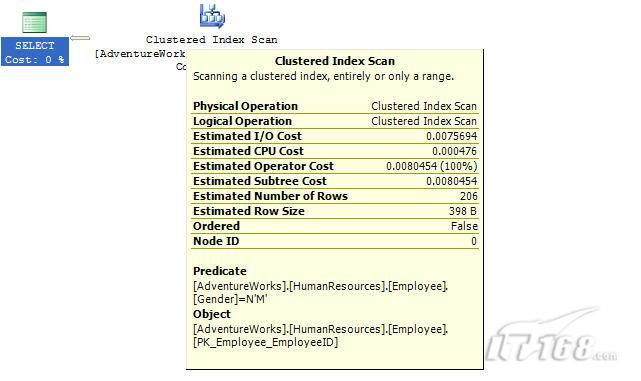
圖 3 查看執行計劃中行為(操作)的詳細信息
這個窗口提供了詳細的評估信息,上圖顯示了聚集索引掃描的詳細信息,它要查找AdventureWorks數據庫HumanResources方案下Employee表中 Gender = ‘M’的行,它也顯示了評估的I/O,CPU成本。
查看執行計劃時,我們應該獲得什麽信息
當你的查詢很慢時,你就應該看看預估的執行計劃(當然也可以查看真實的執行計劃),找出耗時最多的操作,註意觀察以下成本通常較高的操作:
1、表掃描(Table Scan)
當表沒有聚集索引時就會發生,這時只要創建聚集索引或重整索引一般都可以解決問題。
2、聚集索引掃描(Clustered Index Scan)
有時可以認為等同於表掃描,當某列上的非聚集索引無效時會發生,這時只要創建一個非聚集索引就ok了。
3、哈希連接(Hash Join)
當連接兩個表的列沒有被索引時會發生,只需在這些列上創建索引即可。
4、嵌套循環(Nested Loops)
當非聚集索引不包括select查詢清單的列時會發生,只需要創建覆蓋索引問題即可解決。
5、RID查找(RID Lookup)
當你有一個非聚集索引,但相同的表上卻沒有聚集索引時會發生,此時數據庫引擎會使用行ID查找真實的行,這時一個代價高的操作,這時只要在該表上創建聚集索引即可。
TSQL重構真實的故事
只有解決了實際的問題後,知識才轉變為價值。當我們檢查應用程序性能時,發現一個存儲過程比我們預期的執行得慢得多,在生產數據庫中檢索一個月的銷售數據居然要50秒,下面就是這個存儲過程的執行語句:
exec uspGetSalesInfoForDateRange ‘1/1/2009’, 31/12/2009,’Cap’
Tom受命來優化這個存儲過程,下面是這個存儲過程的代碼:
ALTER PROCEDURE uspGetSalesInfoForDateRange@startYear DateTime,
@endYear DateTime,
@keyword nvarchar(50)
AS
BEGIN
SET NOCOUNT ON;
SELECT
Name,
ProductNumber,
ProductRates.CurrentProductRate Rate,
ProductRates.CurrentDiscount Discount,
OrderQty Qty,
dbo.ufnGetLineTotal(SalesOrderDetailID) Total,
OrderDate,
DetailedDescription
FROM
Products INNER JOIN OrderDetails
ON Products.ProductID = OrderDetails.ProductID
INNER JOIN Orders
ON Orders.SalesOrderID = OrderDetails.SalesOrderID
INNER JOIN ProductRates
ON
Products.ProductID = ProductRates.ProductID
WHERE
OrderDate between @startYear and @endYear
AND
(
ProductName LIKE ‘‘ + @keyword + ‘ %‘ OR
ProductName LIKE ‘% ‘ + @keyword + ‘ ‘ + ‘%‘ OR
ProductName LIKE ‘% ‘ + @keyword + ‘%‘ OR
Keyword LIKE ‘‘ + @keyword + ‘ %‘ OR
Keyword LIKE ‘% ‘ + @keyword + ‘ ‘ + ‘%‘ OR
Keyword LIKE ‘% ‘ + @keyword + ‘%‘
)
ORDER BY
ProductName
END
GO
分析索引
首先,Tom想到了審查這個存儲過程使用到的表的索引,很快他發現下面兩列的索引無故丟失了:
OrderDetails.ProductID
OrderDetails.SalesOrderID
他在這兩個列上創建了非聚集索引,然後再執行存儲過程:
exec uspGetSalesInfoForDateRange ‘1/1/2009’, 31/12/2009 with recompile
性能有所改變,但仍然低於預期(這次花了35秒),註意這裏的with recompile子句告訴SQL Server引擎重新編譯存儲過程,重新生成執行計劃,以利用新創建的索引。
分析查詢執行計劃
Tom接下來查看了SQL Server Management Studio中的執行計劃,通過分析,他找到了某些重要的線索:
1、發生了一次表掃描,即使該表已經正確設置了索引,而表掃描占據了總體查詢執行時間的30%;
2、發生了一個嵌套循環連接。
Tom想知道是否有索引碎片,因為所有索引配置都是正確的,通過TSQL他知道了有兩個索引都產生了碎片,很快他重組了這兩個索引,於是表掃描消失了,現在執行存儲過程的時間減少到25秒了。
為了消除嵌套循環連接,他又在表上創建了覆蓋索引,時間進一步減少到23秒。
實施最佳實踐
Tom發現有個UDF有問題,代碼如下:
ALTER FUNCTION [dbo].[ufnGetLineTotal](
@SalesOrderDetailID int
)
RETURNS money
AS
BEGIN
DECLARE @CurrentProductRate money
DECLARE @CurrentDiscount money
DECLARE @Qty int
SELECT
@CurrentProductRate = ProductRates.CurrentProductRate,
@CurrentDiscount = ProductRates.CurrentDiscount,
@Qty = OrderQty
FROM
ProductRates INNER JOIN OrderDetails ON
OrderDetails.ProductID = ProductRates.ProductID
WHERE
OrderDetails.SalesOrderDetailID = @SalesOrderDetailID
RETURN (@CurrentProductRate-@CurrentDiscount)*@Qty
END
在計算訂單總金額時看起來代碼很程序化,Tom決定在UDF的SQL中使用內聯SQL。
dbo.ufnGetLineTotal(SalesOrderDetailID) Total -- 舊代碼
(CurrentProductRate-CurrentDiscount)*OrderQty Total -- 新代碼
執行時間一下子減少到14秒了。
在select查詢清單中放棄不必要的Text列
為了進一步提升性能,Tom決定檢查一下select查詢清單中使用的列,很快他發現有一個Products.DetailedDescription列是Text類型,通過對應用程序代碼的走查,Tom發現其實這一列的數據並不會立即用到,於是他將這一列從select查詢清單中取消掉,時間一下子從14秒減少到6秒,於是Tom決定使用一個存儲過程應用延遲加載策略加載這個Text列。
最後Tom還是不死心,認為6秒也無法接受,於是他再次仔細檢查了SQL代碼,他發現了一個like子句,經過反復研究他認為這個like搜索完全可以用全文搜索替換,最後他用全文搜索替換了like搜索,時間一下子降低到1秒,至此Tom認為調優應該暫時結束了。
小結
看起來我們介紹了好多種優化數據訪問的技巧,但大家要知道優化數據訪問是一個無止境的過程,同樣大家要相信一個信念,無論你的系統多麽龐大,多麽復雜,只要靈活運用我們所介紹的這些技巧,你一樣可以馴服它們。下一篇將介紹高級索引和反範式化。
經過索引優化,重構TSQL後你的數據庫還存在性能問題嗎?完全有可能,這時必須得找另外的方法才行。SQL Server在索引方面還提供了某些高級特性,可能你還從未使用過,利用高級索引會顯著地改善系統性能,本文將從高級索引技術談起,另外還將介紹反範式化技術。
(轉)SQLServer_十步優化SQL Server中的數據訪問 二