
scrapy-cluster叢集的架構
scrapy-cluster叢集的架構:
- python 2.7
- scrapy 1.0.5
- kafka 2.10-0.10.1.1
- redis 3.0.6
scrapy叢集的目的:
- 他們允許任何web頁面的任意集合提交給scrapy叢集,包括動態需求。
- 大量的Scrapy例項在單個機器或多個機器上進行爬取。
- 協調和優化他們的抓取工作所需的網站。
- 儲存抓取的資料。
- 並行執行多個抓取作業。
- 深度資訊抓取工作,網站排名,預測等。
- 你可以任意 add/remove/scale你的爬蟲而不會造成資料丟失或停機等待。
- 利用Apache kafka作為叢集的資料匯流排與叢集的(提交工作,資訊輸入,停止工作,檢視結果)。
- 能夠調整管理獨立的爬蟲在多臺機器上,但必須用相同的IP
scrapy-cluster 原理流程圖
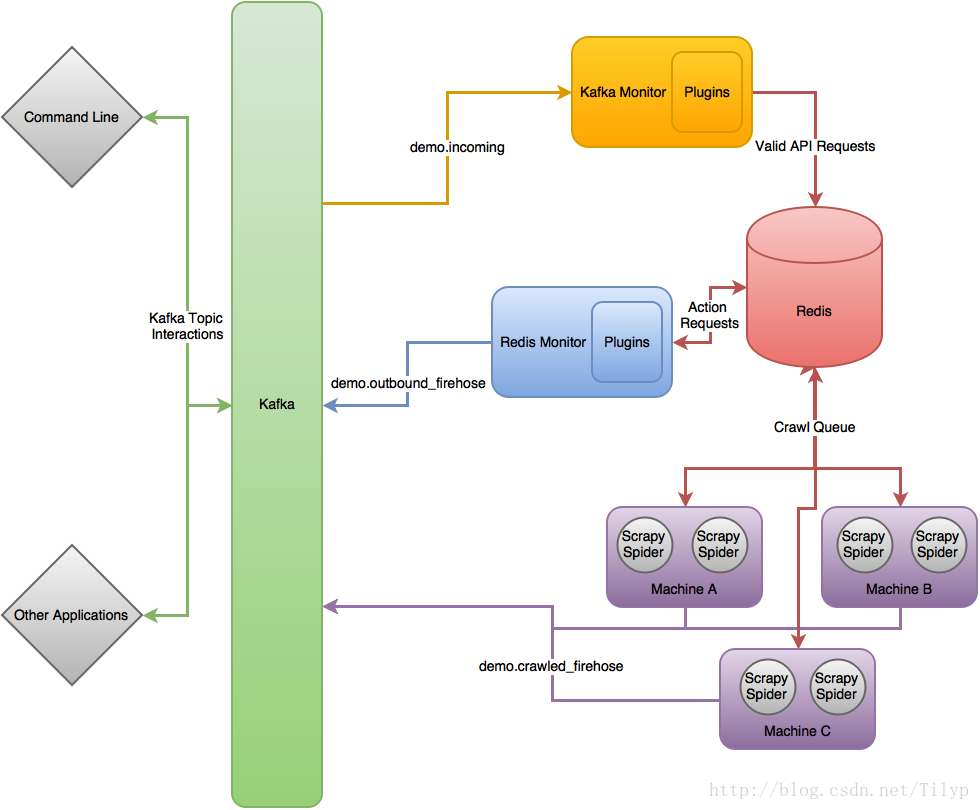
在最高的層次上,Scrapy叢集作用於單個輸入卡夫卡的話題,和兩個獨立輸出卡夫卡的話題。所有請求傳入叢集的kafka話題都是通過demo.incoming, 並根據傳入請求將生成行為請求話題 demo.outbound_firehose或網頁爬取請求話題demo.crawled_firehose。 這裡包括的三個元件是可擴充套件的,kafka元件和
開始搭建叢集
- 首先得確保你的每臺機器上執行著kafka,zookeeper,redis,python2.7
- 在每臺機器上安裝scrapy-cluster,下載地址點選這裡,
- 解壓並進入檔案根據requirements.txt檔案下載依賴需求
$ pip install -r requirements.txt
- 1

- 1
- 離線執行單元測試,以確保一切似乎正常。
$ ./run_offline_tests.sh
如果失敗,請檢查你的依賴是否安裝成功。 - 在三個元件中新建localsettings.py檔案並設定kafka,redis,zookeeper的相關配置以確保通訊(這裡的localsettings.py是覆蓋settings.py的,方便我們修改配置,以防引起不必要的衝突和麻煩(注:以下
scdev是kafka,redis,zookeeper的主機),KAFKA_HOSTS的設定為叢集有多少個IP:PORT就寫多少,以逗號(,)隔開,如KAFKA_HOSTS = 'ip1:port,ip2:port,ip3:port'。
在 kafka-monitor的localsettings.py檔案中寫入
REDIS_HOST = 'scdev'
KAFKA_HOSTS = 'scdev:9092'
在redis-monitor的localsettings.py檔案中寫入
REDIS_HOST = 'scdev'
KAFKA_HOSTS = 'scdev:9092'
在crawlers/crawling/的localsettings.py檔案中寫入
REDIS_HOST = 'scdev'
KAFKA_HOSTS = 'scdev:9092'
ZOOKEEPER_HOSTS = 'scdev:2181'
然後執行他們各自的測試檔案
$ python tests/tests_online.py -v
- 1
- 1
如果整合測試失敗,請確保你的埠是開啟的在kafka叢集,redis主機和zookeeper主機。確保機器爬蟲的設定可以訪問所需的主機上,且可以成功地訪問網際網路。如果測試成功,那麼恭喜你,你可以學習如何使用他了。當然這裡是直接部署,如果單臺機器沒有測試通過,建議你先看看官方文件的測試用例。
叢集的使用
首先,啟動你的每一臺機器上的三大元件
1,Kafka Monitor
$ python kafka_monitor.py run
- 1
- 1
2, 啟動你要執行的spider,如link_spider.py
$ scrapy runspider crawling/spiders/link_spider.py
- 1
- 1
3,啟動kafkadump.py 來監聽redis 元件返回的結果
$ python kafkadump.py dump -t demo.crawled_firehose
- 1
- 1
用多少臺機器你啟動多少臺,這裡可以新增&在後臺啟動,當然我還是建議你在剛開始時開啟更多的視窗來觀察他們如何工作。
其次,就是啟動整個叢集
1,Kafka Monitor
$ python kafka_monitor.py run
- 1
- 1
2,Redis Monitor
$ python redis_monitor.py
- 1
- 1
3,再次啟動你要執行的spider
$ scrapy runspider crawling/spiders/link_spider.py
- 1
- 1
4,啟動dump 監聽redis元件返回的結果
$ python kafkadump.py dump -t demo.crawled_firehose
- 1
- 1
5,啟動dump 檢視你的機器爬取的結果
$ python kafkadump.py dump -t demo.outbound_firehose
- 1
- 1
在選擇的每臺機器上,每一個過程中應保持執行並和其餘叢集處於操作狀態。
再次,進行資料爬取
1,在接下來我們需要給叢集傳送一個爬取請求,這是通過相同的kafka元件Python指令碼來實現的,但是需要運用不同的命令來辨別結果。
$ python kafka_monitor.py feed '{"url": "http://istresearch.com", "appid":"testapp", "crawlid":"abc123"}'
- 1
- 1
在下列命令列中您將看到傳送請求成功:
$ 2015-12-22 15:45:37,457 [kafka-monitor] INFO: Feeding JSON into demo.incoming
{
"url": "http://istresearch.com",
"crawlid": "abc123",
"appid": "testapp"
}
2015-12-22 15:45:37,459 [kafka-monitor] INFO: Successfully fed item to Kafka
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果連線不到kafka,你將在日誌中看到一條錯誤訊息,
2,在請求成功之後,以下一系列的事件將按照順序發生:
- kafka元件將收到請求,並把它存放到redis中
- spider會定期檢測新的請求,並像正常的scrapy spider一樣從佇列中獲取請求且執行它
- 接著爬取到的資料將被掛起在 Scrapy item pipeline 中,由kafka Pipeline物件將其推送到kafka
- kafka dump 將讀取結果輸出的話題,並列印它收到的原始爬取物件
3,redis 元件有助於我們學習在爬取中如何處理和操作redis,因此我們會選擇一個更大的網站我們可以看到它是如何工作的(這需要一個完整的部署)
Crawl Request:
$ python kafka_monitor.py feed '{"url": "http://dmoz.org", "appid":"testapp", "crawlid":"abc1234", "maxdepth":1}'
- 1
- 1
現在傳送一個info行為請求爬取去看發生了什麼
$ python kafka_monitor.py feed '{"action":"info", "appid":"testapp", "uuid":"someuuid", "crawlid":"abc1234", "spiderid":"link"}'
- 1
- 1
以下情況會發生在這個動作請求之後
- kafka 元件將收到操作請求,並把它存放到redis
- redis 元件將執行
info請求和記錄的當前掛起的請求的spiderid,appid,crawlid。 - redis 元件將結果返回給kafka
- kafka dump 將收到類似下面的結果:
$ {u'server_time': 1450817666, u'crawlid': u'abc1234', u'total_pending': 25, u'total_domains': 2, u'spiderid': u'link', u'appid': u'testapp', u'domains': {u'twitter.com': {u'low_priority': -9, u'high_priority': -9, u'total': 1}, u'dmoz.org': {u'low_priority': -9, u'high_priority': -9, u'total': 24}}, u'uuid': u'someuuid'}
- 1
- 1
在這種情況下我們有25 url在佇列中等待,所以你的顯示可能會略有不同
4,如果爬取步驟1仍在執行,現在讓它發出stop動作請求停止
Action Request:
$ python kafka_monitor.py feed '{"action":"stop", "appid":"testapp", "uuid":"someuuid", "crawlid":"abc1234", "spiderid":"link"}'
- 1
- 1
以下情況會發生這個動作請求之後
- kafka 元件將收到請求並存放在redis中
- redis 元件將執行
stop請求,並清除當前請求的spiderid,appid,crawlid。 - redis 元件將
crawlid加入黑名單,所以沒有更多的掛起的請求可以從蜘蛛或者應用程式生成 - redis 元件將清洗總結果傳送回kafka
- kafka dump 將收到類似下面的結果:
$ {u'total_purged': 90, u'server_time': 1450817758, u'crawlid': u'abc1234', u'spiderid': u'link', u'appid': u'testapp', u'action': u'stop'}
- 1
- 1
在這種情況下,我們有90個url從佇列中刪除。這些掛起的請求現在完全從系統中刪除,蜘蛛會回到被閒置。
希望你現在有一個工作Scrapy叢集,允許您提交工作佇列,接收資訊抓取,並停止爬行,如果它變得失控。請繼續更深入地閱讀每個元件的文件。
元件的作用
kafka
kafka元件作為入口點進入爬蟲架構。它驗證API請求之後,可以確保任何時候的資料是正確的格式。kafka 元件的設計源於需要定義一個格式被允許建立爬蟲抓取從任何應用程式架構。如果應用程式可以讀取和寫入到卡夫卡叢集就可以寫資訊到一個特定的kafka 主題建立爬行。
很快那些相同的應用程式想要對他們的爬蟲進行資訊檢索的能力,停止他們,或者得到他們的叢集資訊。我們決定建立一個動態請求的介面可以支援所有的需求,但利用相同的基礎程式碼。這個基礎程式碼現在被稱為kafka 元件,利用各種外掛來擴充套件或改變kafka 元件的功能。
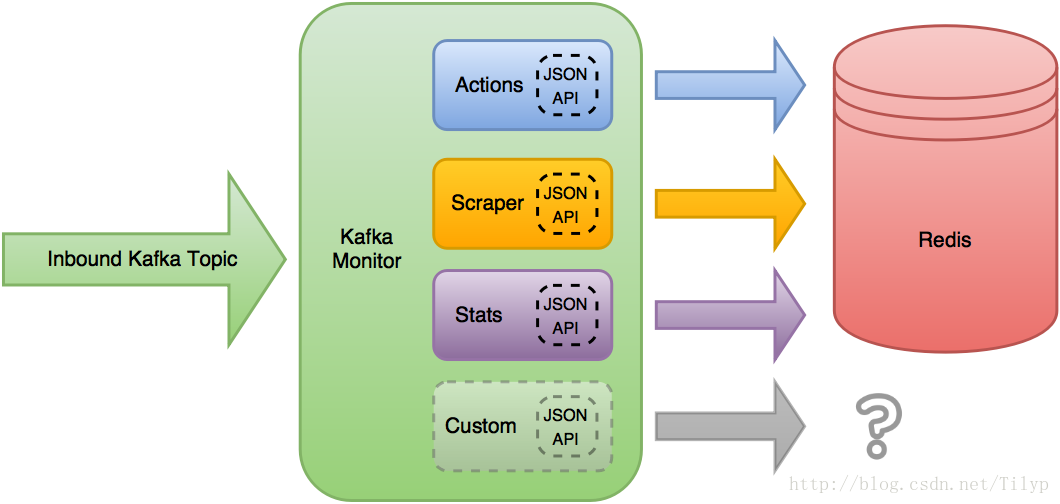
kafka 元件讀取需要入站kafka 的話題,並應用當前載入的JSON api外掛來接收訊息。第一個外掛有一個有效的JSON Schema接收JSON物件被允許做自己的處理和操縱的物件,
Scrapy叢集的用例中,預設外掛將他們的請求寫入redis 的key中,但是功能並沒有就此止步。kafka 元件的設定可以改變哪些外掛載入,或新增新外掛擴充套件功能。這些模組允許kafka 元件核心佔用空間小但允許擴充套件或執行不同的外掛了。
從我們自己的內部除錯,確保其他應用程式正常工作,一個叫 kafka dump 的實用應用程式也是為了能夠建立和監控kafka 通過訊息互動。這是一個小型轉儲工具沒有外部依賴,允許使用者通過kafka 話題去了解叢集。
kafka_monitor.py
有兩種執行模式run和feed:
Run:
這是連續執行模式。將接受傳入kafka 的訊息從一個話題中,驗證訊息為JSON對所有可能的JSON API,然後允許有效的API外掛來處理物件(執行模式是主要的流程你應該執行) 。
$ python kafka_monitor.py run
- 1
- 1
Feed:
以JSON物件提交你想要的kafka的話題。這需要提交一個有效的JSON物件並將它插入所需的kafka的話題,然後被上面的run命令執行。
$ python kafka_monitor.py feed '{"url": "http://istresearch.com", "appid":"testapp", "crawlid":"ABC123"}'
- 1
- 1
feed非常緩慢在生產中不應使用。相反,你應該根據自己的需求編寫可以不斷執行的應用程式給kafka 所需的API請求。
kafkadump.py
基本kafka主題工具用於檢查訊息流在你的卡夫卡叢集。
Dump:
$ python kafkadump.py dump -t demo.crawled_firehose
- 1
- 1
這個實用程式預設消耗結束後獲取所需的kafka 的話題,並且對離線測試很有用通過當前的訊息流。
List:
列出所有叢集內的話題
$ python kafkadump.py list
- 1
- 1
kafka 元件的API 就不多說了,自己到官網去看,API地址 。這裡講一下kafka 的幾個話題
- 入站話題:
demo.incoming,此話題提交正確格式化的叢集請求。 - 出站結果卡夫卡的話題:
1,demo.crawled_firehouse,為系統輸出結果的流水話題。任何單一的網頁抓取的Scrapy叢集保證走出這個管子。
2,demo.outbound_firehose,輸出所有特殊的爬蟲啟動,停止,到期,統計要求的流水話題。此主題將具有從群集請求所有非爬行資料的能力。
3,demo.crawled_<appid>,為獲取特殊應用的爬取結果而建立的特殊主題,任何應用程式都可以用appid建立監聽話題來監聽自己特定的爬取結果,這些主題是爬行的流水話題資料的一個子集並且只包含appid提交的結果。
4,demo.outbound_<appid>,一個特別的話題為了讀取特殊應用程式的行動請求資料
後兩種方式是禁用的,因為他們在kafka中產生了重複資料,如果想要啟用它,只需要覆蓋redis 元件的配置檔案。
scrapy-cluster叢集的架構:
- python 2.7
- scrapy 1.0.5
- kafka 2.10-0.10.1.1
- redis 3.0.6
scrapy叢集的目的:
- 他們允許任何web頁面的任意集合提交給scrapy叢集,包括動態需求。
- 大量的Scrapy例項在單個機器或多個機器上進行爬取。
- 協調和優化他們的抓取工作所需的網站。
- 儲存抓取的資料。
- 並行執行多個抓取作業。
- 深度資訊抓取工作,網站排名,預測等。
- 你可以任意 add/remove/scale你的爬蟲而不會造成資料丟失或停機等待。
- 利用Apache kafka作為叢集的資料匯流排與叢集的(提交工作,資訊輸入,停止工作,檢視結果)。
- 能夠調整管理獨立的爬蟲在多臺機器上,但必須用相同的IP
scrapy-cluster 原理流程圖
在最高的層次上,Scrapy叢集作用於單個輸入卡夫卡的話題,和兩個獨立輸出卡夫卡的話題。所有請求傳入叢集的kafka話題都是通過demo.incoming, 並根據傳入請求將生成行為請求話題 demo.outbound_firehose或網頁爬取請求話題demo.crawled_firehose。 這裡包括的三個元件是可擴充套件的,kafka元件和Redis元件都使用“外掛”以提高自己的能力,Scrapy可以運用“Middlewares”,“Pipelines”,“Spiders”去定製自己的爬取需求,這三個元件在一起允許縮放和分散式執行在許多機器上。
開始搭建叢集
- 首先得確保你的每臺機器上執行著kafka,zookeeper,redis,python2.7
- 在每臺機器上安裝scrapy-cluster,下載地址點選這裡,
- 解壓並進入檔案根據requirements.txt檔案下載依賴需求
$ pip install -r requirements.txt
- 1
- 1
- 離線執行單元測試,以確保一切似乎正常。
$ ./run_offline_tests.sh
如果失敗,請檢查你的依賴是否安裝成功。 - 在三個元件中新建localsettings.py檔案並設定kafka,redis,zookeeper的相關配置以確保通訊(這裡的localsettings.py是覆蓋settings.py的,方便我們修改配置,以防引起不必要的衝突和麻煩(注:以下
scdev是kafka,redis,zookeeper的主機),KAFKA_HOSTS的設定為叢集有多少個IP:PORT就寫多少,以逗號(,)隔開,如KAFKA_HOSTS = 'ip1:port,ip2:port,ip3:port'。
在 kafka-monitor的localsettings.py檔案中寫入
REDIS_HOST = 'scdev'
KAFKA_HOSTS = 'scdev:9092'
在redis-monitor的localsettings.py檔案中寫入
REDIS_HOST = 'scdev'
KAFKA_HOSTS = 'scdev:9092'
在crawlers/crawling/的localsettings.py檔案中寫入
REDIS_HOST = 'scdev'
KAFKA_HOSTS = 'scdev:9092'
ZOOKEEPER_HOSTS = 'scdev:2181'
然後執行他們各自的測試檔案
$ python tests/tests_online.py -v
- 1
- 1
如果整合測試失敗,請確保你的埠是開啟的在kafka叢集,redis主機和zookeeper主機。確保機器爬蟲的設定可以訪問所需的主機上,且可以成功地訪問網際網路。如果測試成功,那麼恭喜你,你可以學習如何使用他了。當然這裡是直接部署,如果單臺機器沒有測試通過,建議你先看看官方文件的測試用例。
叢集的使用
首先,啟動你的每一臺機器上的三大元件
1,Kafka Monitor
$ python kafka_monitor.py run
- 1
- 1
2, 啟動你要執行的spider,如link_spider.py
$ scrapy runspider crawling/spiders/link_spider.py
- 1
- 1
3,啟動kafkadump.py 來監聽redis 元件返回的結果
$ python kafkadump.py dump -t demo.crawled_firehose
- 1
- 1
用多少臺機器你啟動多少臺,這裡可以新增&在後臺啟動,當然我還是建議你在剛開始時開啟更多的視窗來觀察他們如何工作。
其次,就是啟動整個叢集
1,Kafka Monitor
$ python kafka_monitor.py run
- 1
- 1
2,Redis Monitor
$ python redis_monitor.py
- 1
- 1
3,再次啟動你要執行的spider
$ scrapy runspider crawling/spiders/link_spider.py
- 1
- 1
4,啟動dump 監聽redis元件返回的結果
$ python kafkadump.py dump -t demo.crawled_firehose
- 1
- 1
5,啟動dump 檢視你的機器爬取的結果
$ python kafkadump.py dump -t demo.outbound_firehose
- 1
- 1
在選擇的每臺機器上,每一個過程中應保持執行並和其餘叢集處於操作狀態。
再次,進行資料爬取
1,在接下來我們需要給叢集傳送一個爬取請求,這是通過相同的kafka元件Python指令碼來實現的,但是需要運用不同的命令來辨別結果。
$ python kafka_monitor.py feed '{"url": "http://istresearch.com", "appid":"testapp", "crawlid":"abc123"}'
- 1
- 1
在下列命令列中您將看到傳送請求成功:
$ 2015-12-22 15:45:37,457 [kafka-monitor] INFO: Feeding JSON into demo.incoming
{
"url": "http://istresearch.com",
"crawlid": "abc123",
"appid": "testapp"
}
2015-12-22 15:45:37,459 [kafka-monitor] INFO: Successfully fed item to Kafka
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果連線不到kafka,你將在日誌中看到一條錯誤訊息,
2,在請求成功之後,以下一系列的事件將按照順序發生:
- kafka元件將收到請求,並把它存放到redis中
- spider會定期檢測新的請求,並像正常的scrapy spider一樣從佇列中獲取請求且執行它
- 接著爬取到的資料將被掛起在 Scrapy item pipeline 中,由kafka Pipeline物件將其推送到kafka
- kafka dump 將讀取結果輸出的話題,並列印它收到的原始爬取物件
3,redis 元件有助於我們學習在爬取中如何處理和操作redis,因此我們會選擇一個更大的網站我們可以看到它是如何工作的(這需要一個完整的部署)
Crawl Request:
$ python kafka_monitor.py feed '{"url": "http://dmoz.org", "appid":"testapp", "crawlid":"abc1234", "maxdepth":1}'
- 1
- 1
現在傳送一個info行為請求爬取去看發生了什麼
$ python kafka_monitor.py feed '{"action":"info", "appid":"testapp", "uuid":"someuuid", "crawlid":"abc1234", "spiderid":"link"}'
- 1
- 1
以下情況會發生在這個動作請求之後
- kafka 元件將收到操作請求,並把它存放到redis
- redis 元件將執行
info請求和記錄的當前掛起的請求的spiderid,appid,crawlid。 - redis 元件將結果返回給kafka
- kafka dump 將收到類似下面的結果:
$ {u'server_time': 1450817666, u'crawlid': u'abc1234', u'total_pending': 25, u'total_domains': 2, u'spiderid': u'link', u'appid': u'testapp', u'domains': {u'twitter.com': {u'low_priority': -9, u'high_priority': -9, u'total': 1}, u'dmoz.org': {u'low_priority': -9, u'high_priority': -9, u'total': 24}}, u'uuid': u'someuuid'}
- 1
- 1
在這種情況下我們有25 url在佇列中等待,所以你的顯示可能會略有不同
4,如果爬取步驟1仍在執行,現在讓它發出stop動作請求停止
Action Request:
$ python kafka_monitor.py feed '{"action":"stop", "appid":"testapp", "uuid":"someuuid", "crawlid":"abc1234", "spiderid":"link"}'
- 1
- 1
以下情況會發生這個動作請求之後
- kafka 元件將收到請求並存放在redis中
- redis 元件將執行
stop請求,並清除當前請求的spiderid,appid,crawlid。 - redis 元件將
crawlid加入黑名單,所以沒有更多的掛起的請求可以從蜘蛛或者應用程式生成 - redis 元件將清洗總結果傳送回kafka
- kafka dump 將收到類似下面的結果:
$ {u'total_purged': 90, u'server_time': 1450817758, u'crawlid': u'abc1234', u'spiderid': u'link', u'appid': u'testapp', u'action': u'stop'}
- 1
- 1
在這種情況下,我們有90個url從佇列中刪除。這些掛起的請求現在完全從系統中刪除,蜘蛛會回到被閒置。
希望你現在有一個工作Scrapy叢集,允許您提交工作佇列,接收資訊抓取,並停止爬行,如果它變得失控。請繼續更深入地閱讀每個元件的文件。
元件的作用
kafka
kafka元件作為入口點進入爬蟲架構。它驗證API請求之後,可以確保任何時候的資料是正確的格式。kafka 元件的設計源於需要定義一個格式被允許建立爬蟲抓取從任何應用程式架構。如果應用程式可以讀取和寫入到卡夫卡叢集就可以寫資訊到一個特定的kafka 主題建立爬行。
很快那些相同的應用程式想要對他們的爬蟲進行資訊檢索的能力,停止他們,或者得到他們的叢集資訊。我們決定建立一個動態請求的介面可以支援所有的