
一、hadoop單節點安裝測試
一、hadoop簡介
相信你或多或少都聽過hadoop這個名字,hadoop是一個開源的、分散式軟體平臺。它主要解決了分散式儲存(hdfs)和分散式計算(mapReduce)兩個大資料的痛點問題,在hadoop平臺上你可以輕易地使用和擴充套件數千臺的計算機而不用關心底層的實現問題。而現在的hadoop更是形成了一個生態體系,如圖:
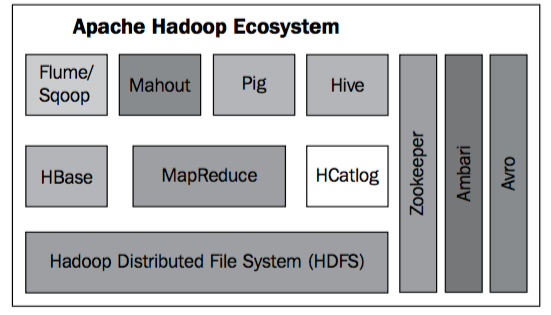
上圖大體展示了hadoop的生態體系,但並不完整。總而言之,隨著hadoop越來越成熟,也會有更多地成員加入hadoop生態體系中。
hadoop官方網站:http://hadoop.apache.org/
二、安裝hadoop
hadoop安裝分為三種形式:
1、單節點:也就是僅在一臺機器上安裝一個hadoop節點;
2、偽分散式:在一臺機器上安裝多個hadoop節點,模擬分散式環境;
3、完全分散式:在多型機器上分別安裝節點;
而本文將以單節點安裝作為學習演示使用
完全分散式可以參考:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
準備環境
Linux系統:hadoop可以在Linux和windows平臺上安裝,但是windows平臺沒有經過生成測試,所以建議使用Linux平臺,而本文采用的是centos作為測試平臺。你可以在自己的電腦安裝虛擬機器來操作,安裝vmware和centos參考文件:
https://www.cnblogs.com/lay2017/p/9786213.html
https://www.cnblogs.com/lay2017/p/9786479.html
hadoop是由Java開發的,所以你需要提供JDK環境的支援:
Linux中JDK安裝參考文件:
https://www.cnblogs.com/lay2017/p/7442217.html
注意:如果你安裝hadoop2.7+版本的話需要JDK1.7+的支援,如果是2.6-版本需要JDK1.6的支援。
下載安裝hadoop
前往hadoop下載頁面找到二進位制包的下載地址
http://www.apache.org/dyn/closer.cgi/hadoop/common/
我們先在centos下建立一個hadoop目錄,然後進入該目錄:
mkdir /usr/local/hadoop
cd /usr/local/hadoop
使用wget命令下載hadoop到當前目錄下(本文下載的是2.9.0穩定版:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.9.0/hadoop-2.9.0.tar.gz)

使用tar命令解壓縮

你會得到

接下來,你需要配置JAVA_HOME,首先進入到etc/hadoop目錄下
cd /usr/local/hadoop/hadoop-2.9.0/etc/hadoop
編輯hadoop-env.sh檔案

配置你的JAVA_HOME

三、測試
為了驗證當前的hadoop是否可用的,我們使用share目錄下mapReduce的示例jar來測試一下
我們先回到hadoop的根目錄
cd /usr/local/hadoop/hadoop-2.9.0
在執行示例jar之前先建立一個目錄用於輸入檔案資料
mkdir input
我們將etc/hadoop下的一些文字檔案拷貝過來當作測試用一下
cp etc/hadoop/*.xml input
接下來我們就可以執行share目錄下的示例程式了(執行結果是統計所有輸入檔案中字元h出現的次數)
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar grep input output 'h'
我們將結果輸出看一下
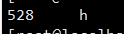
cat output/*
你會看到,統計次數為528次
以上就是hadoop單節點的安裝,參考官方文件實現:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html