
1.Kafka概念,架構
一、為什麼需要訊息系統
1.解耦
允許你獨立的擴充套件或修改兩邊的處理過程,只要確保它們遵守同樣的介面約束。
2.冗餘
訊息佇列把資料進行持久化直到它們已經被完全處理,通過這一方式規避了資料丟失風險。許多訊息佇列所採用的"插入-獲取-刪除"正規化中,在把一個訊息從佇列中刪除之前,需要你的處理系統明確的指出該訊息已經被處理完畢,從而確保你的資料被安全的儲存直到你使用完畢。
3.擴充套件性
因為訊息佇列解耦了你的處理過程,所以增大訊息入隊和處理的頻率是很容易的,只要另外增加處理過程即可。
4.靈活性 & 峰值處理能力
在訪問量劇增的情況下,應用仍然需要繼續發揮作用,但是這樣的突發流量並不常見。如果為以能處理這類峰值訪問為標準來投入資源隨時待命無疑是巨大的浪費。使用訊息佇列能夠使關鍵元件頂住突發的訪問壓力,而不會因為突發的超負荷的請求而完全崩潰。
5.可恢復性
系統的一部分元件失效時,不會影響到整個系統。訊息佇列降低了程序間的耦合度,所以即使一個處理訊息的程序掛掉,加入佇列中的訊息仍然可以在系統恢復後被處理。
6.順序保證
在大多使用場景下,資料處理的順序都很重要。大部分訊息佇列本來就是排序的,並且能保證資料會按照特定的順序來處理。(Kafka 保證一個 Partition 內的訊息的有序性)
7.緩衝
有助於控制和優化資料流經過系統的速度,解決生產訊息和消費訊息的處理速度不一致的情況。
8.非同步通訊
很多時候,使用者不想也不需要立即處理訊息。訊息佇列提供了非同步處理機制,允許使用者把一個訊息放入佇列,但並不立即處理它。想向佇列中放入多少訊息就放多少,然後在需要的時候再去處理它們。
二、kafka架構
1. 拓撲結構

2. 相關概念
1.producer
訊息生產者,釋出訊息到 kafka叢集的終端或服務。
2.broker
kafka叢集中包含的伺服器。
3.topic
每條釋出到kafka叢集的訊息屬於的類別,即 kafka是面向topic的。
4.partition
partition是物理上的概念,每個topic包含一個或多個partition。kafka分配的單位是partition。
5.consumer
從kafka叢集中消費訊息的終端或服務。
6.consumer group
high-level consumer API 中,每個consumer都屬於一個consumer group,每條訊息只能被consumer group中的一個 consumer消費,但可以被多個consumer group消費。
7.replica
partition的副本,保障partition的高可用。
8.leader
replica中的一個角色,producer和consumer只跟leader互動。
9.follower
replica中的一個角色,從leader中複製資料。
10.controller
kafka叢集中的其中一個伺服器,用來進行leader election以及各種failover。
11.zookeeper
kafka通過zookeeper來儲存叢集的meta資訊。
3. zookeeper節點

三、producer釋出訊息
1 寫入方式
producer採用push模式將訊息釋出到broker,每條訊息都被append到patition中,屬於順序寫磁碟(順序寫磁碟效率比隨機寫記憶體要高,保障kafka吞吐率)。
2 訊息路由
producer 傳送訊息到 broker 時,會根據分割槽演算法選擇將其儲存到哪一個 partition。其路由機制為:
1.指定了patition,則直接使用
2.未指定patition但指定key,通過對key的value進行hash選出一個patition
3.patition和key都未指定,使用輪詢選出一個patition
3 寫入流程

流程說明:
1. producer先從zookeeper的"/brokers/.../state"節點找到該partition的leader
2. producer將訊息傳送給該leader
3. leader將訊息寫入本地log
4. followers從leaderpull訊息,寫入本地log後leader傳送ACK
5. leader收到所有ISR中的replica的ACK後,增加HW(highwatermark,最後commit的offset)並向producer傳送ACK
四、broker儲存訊息
1 儲存方式
物理上把topic分成一個或多個patition(對應server.properties中的num.partitions=3配置),每個patition物理上對應一個資料夾(該資料夾儲存該patition的所有訊息和索引檔案)。
2 儲存策略
無論訊息是否被消費,kafka都會保留所有訊息。有兩種策略可以刪除舊資料:
1.基於時間:log.retention.hours=168
2.基於大小:log.retention.bytes=1073741824
注意:因為Kafka讀取特定訊息的時間複雜度為O(1),即與檔案大小無關,所以這裡刪除過期檔案與提高Kafka效能無關。
3 topic建立
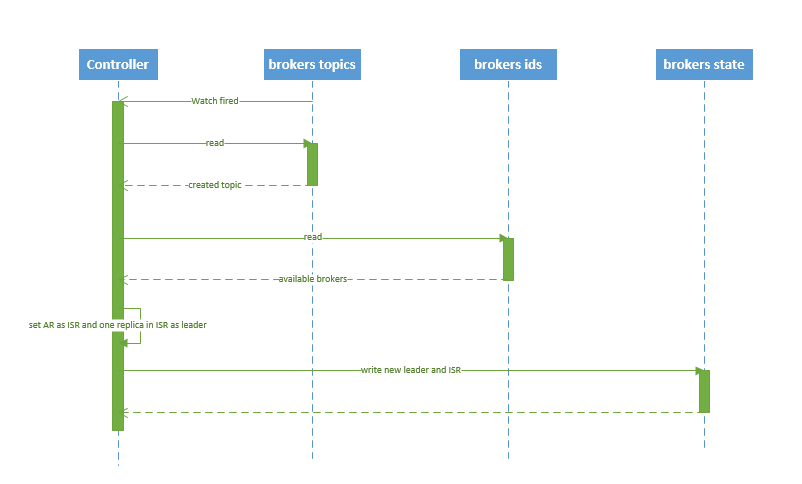
流程說明:
1. controller在ZooKeeper的/brokers/topics節點上註冊watcher。當topic被建立,則controller會通過watch得到該topic的partition/replica分配。
2. controller從/brokers/ids讀取當前所有可用的broker列表,對於set_p中的每一個partition:
2.1 從分配給該partition的所有replica(稱為AR)中任選一個可用的broker作為新的leader,並將AR設定為新的ISR。
2.2 將新的leader和ISR寫入/brokers/topics/[topic]/partitions/[partition]/state。
3. controller通過RPC向相關的broker傳送LeaderAndISRRequest。
4 topic刪除
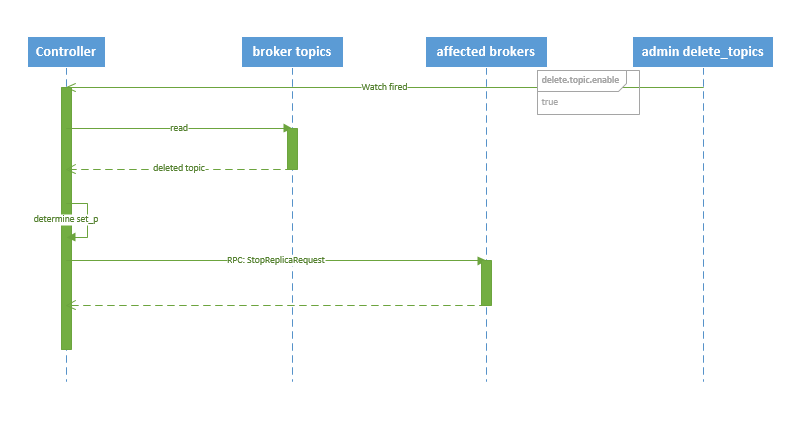
流程說明:
1. controller在zooKeeper的/brokers/topics節點上註冊watcher。當topic被刪除,則controller會通過watch得到該topic的partition/replica分配。
2. 若delete.topic.enable=false,結束;否則controller註冊在/admin/delete_topics上的watch被fire,controller通過回撥向對應的broker傳送StopReplicaRequest。
五、kafka HA
1 replication
同一個partition可能會有多個replica(對應server.properties配置中的default.replication.factor=N)。沒有replica的情況下,一旦broker宕機,其上所有patition的資料都不可被消費,同時producer也不能再將資料存於其上的patition。引入replication之後,同一個partition可能會有多個replica,而這時需要在這些replica之間選出一個leader,producer和consumer只與這個leader互動,其它replica作為follower從leader中複製資料。
Kafka分配Replica的演算法如下:
1. 將所有broker(假設共n個broker)和待分配的partition排序
2. 將第i個partition分配到第(imodn)個broker上
3. 將第i個partition的第j個replica分配到第((i+j)moden)個broker上
2 leader failover
當partition對應的leader宕機時,需要從follower中選舉出新leader。在選舉新leader時,一個基本的原則是,新的leader必須擁有舊leadercommit過的所有訊息。
kafka在zookeeper中(/brokers/.../state)動態維護了一個ISR(in-syncreplicas),由寫入流程可知ISR裡面的所有replica都跟上了leader,只有ISR裡面的成員才能選為leader。對於f+1個replica,一個partition可以在容忍f個replica失效的情況下保證訊息不丟失。
當所有replica都不工作時,有兩種可行的方案:
1. 等待ISR中的任一個replica活過來,並選它作為leader。可保障資料不丟失,但時間可能相對較長。
2. 選擇第一個活過來的replica(不一定是ISR成員)作為leader。無法保障資料不丟失,但相對不可用時間較短。
3 broker failover
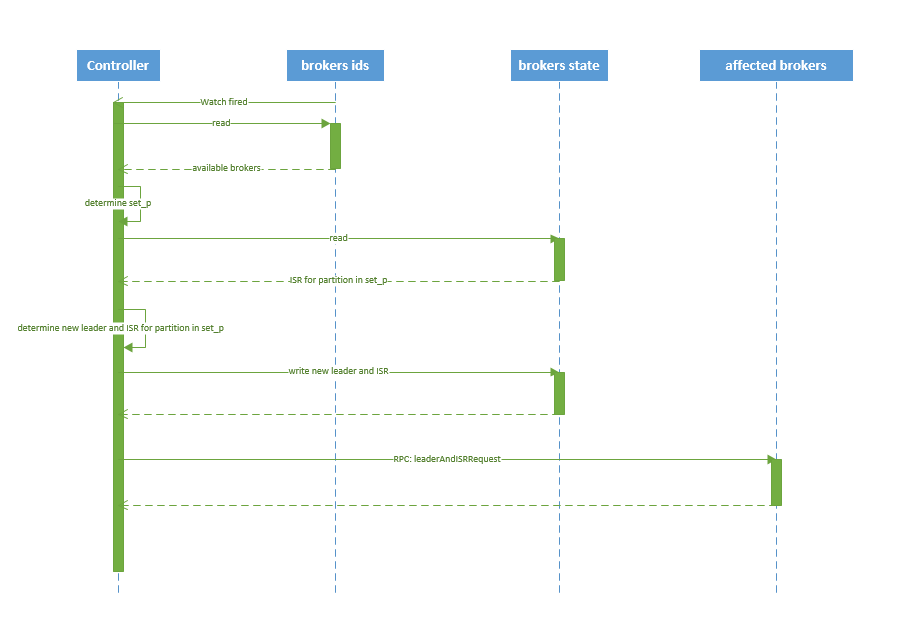
流程說明:
1.controller在zookeeper的/brokers/ids/[brokerId]節點註冊Watcher,當broker宕機時zookeeper會firewatch
2.controller從/brokers/ids節點讀取可用broker
3.controller決定set_p,該集合包含宕機broker上的所有partition
4.對set_p中的每一個partition
4.1從/brokers/topics/[topic]/partitions/[partition]/state節點讀取ISR
4.2決定新leader
4.3將新leader、ISR、controller_epoch和leader_epoch等資訊寫入state節點
5.通過RPC向相關broker傳送leaderAndISRRequest命令
4 controller failover
當controller宕機時會觸發controllerfailover。每個broker都會在zookeeper的"/controller"節點註冊watcher,當controller宕機時zookeeper中的臨時節點消失,所有存活的broker收到fire的通知,每個broker都嘗試建立新的controller path,只有一個競選成功並當選為controller。
當新的controller當選時,會觸發KafkaController.onControllerFailover方法,在該方法中完成如下操作:
1.讀取並增加ControllerEpoch。
2.在reassignedPartitionsPatch(/admin/reassign_partitions)上註冊watcher。
3.在preferredReplicaElectionPath(/admin/preferred_replica_election)上註冊watcher。
4.通過partitionStateMachine在brokerTopicsPatch(/brokers/topics)上註冊watcher。
5.若delete.topic.enable=true(預設值是false),則partitionStateMachine在DeleteTopicPatch(/admin/delete_topics)上註冊watcher。
6.通過replicaStateMachine在BrokerIdsPatch(/brokers/ids)上註冊Watch。
7.初始化ControllerContext物件,設定當前所有topic,“活”著的broker列表,所有partition的leader及ISR等。
8.啟動replicaStateMachine和partitionStateMachine。
9.將brokerState狀態設定為RunningAsController。
10.將每個partition的Leadership資訊傳送給所有“活”著的broker。
11.若auto.leader.rebalance.enable=true(預設值是true),則啟動partition-rebalance執行緒。
12.若delete.topic.enable=true且DeleteTopicPatch(/admin/delete_topics)中有值,則刪除相應的Topic。
六、consumer消費訊息
1 consumerAPI
kafka提供了兩套consumerAPI:The high-level Consumer API、The Simple Consumer API。其中high-level consumer API提供了一個從kafka消費資料的高層抽象,而SimpleConsumerAPI則需要開發人員更多地關注細節。
1.1 The high-level consumer API
high-level consumer API提供了consumer group的語義,一個訊息只能被group內的一個consumer所消費,且consumer消費訊息時不關注offset,最後一個offset由zookeeper儲存。
使用high-level consumer API可以是多執行緒的應用,應當注意:
1. 如果消費執行緒大於 patition 數量,則有些執行緒將收不到訊息 2. 如果 patition 數量大於執行緒數,則有些執行緒多收到多個 patition 的訊息 3. 如果一個執行緒消費多個 patition,則無法保證你收到的訊息的順序,而一個 patition 內的訊息是有序的
1.2 The SimpleConsumer API
如果你想要對patition有更多的控制權,那就應該使用Simple Consumer API,比如:
1.多次讀取一個訊息
2.只消費一個patition中的部分訊息
3.使用事務來保證一個訊息僅被消費一次
但是使用此API時,partition、offset、broker、leader等對你不再透明,需要自己去管理。你需要做大量的額外工作:
1.必須在應用程式中跟蹤offset,從而確定下一條應該消費哪條訊息
2.應用程式需要通過程式獲知每個Partition的leader是誰
3.需要處理leader的變更
使用Simple Consumer API的一般流程如下:
1.查詢到一個“活著”的broker,並且找出每個partition的leader
2.找出每個partition的follower
3.定義好請求,該請求應該能描述應用程式需要哪些資料
4.fetch資料
5.識別leader的變化,並對之作出必要的響應
2 consumer group
kafka的分配單位是patition。每個consumer都屬於一個group,一個partition只能被同一個group內的一個consumer所消費(也就保障了一個訊息只能被group內的一個consuemr所消費),但是多個group可以同時消費這個partition。
kafka的設計目標之一就是同時實現離線處理和實時處理,根據這一特性,可以使用spark/Storm這些實時處理系統對訊息線上處理,同時使用Hadoop批處理系統進行離線處理,還可以將資料備份到另一個數據中心,只需要保證這三者屬於不同的consumer group。如圖:

3 消費方式
consumer採用pull模式從broker中讀取資料。
push模式很難適應消費速率不同的消費者,因為訊息傳送速率是由broker決定的。它的目標是儘可能以最快速度傳遞訊息,但是這樣很容易造成consumer來不及處理訊息,典型的表現就是拒絕服務以及網路擁塞。而pull模式則可以根據consumer的消費能力以適當的速率消費訊息。