
2.最鄰近規則分類KNN演算法
1.綜述

2.例子
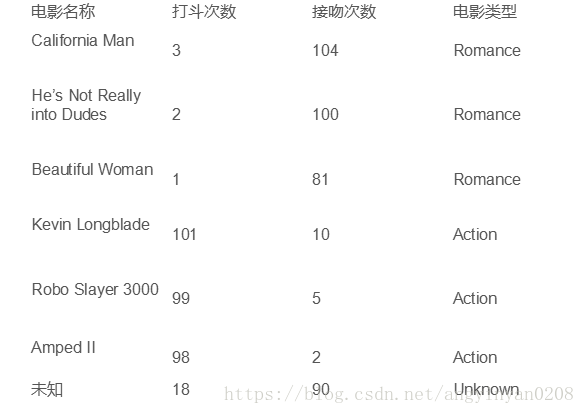
未知的電影屬於什麼類別呢?

3.演算法描述

3.3計算上述例子

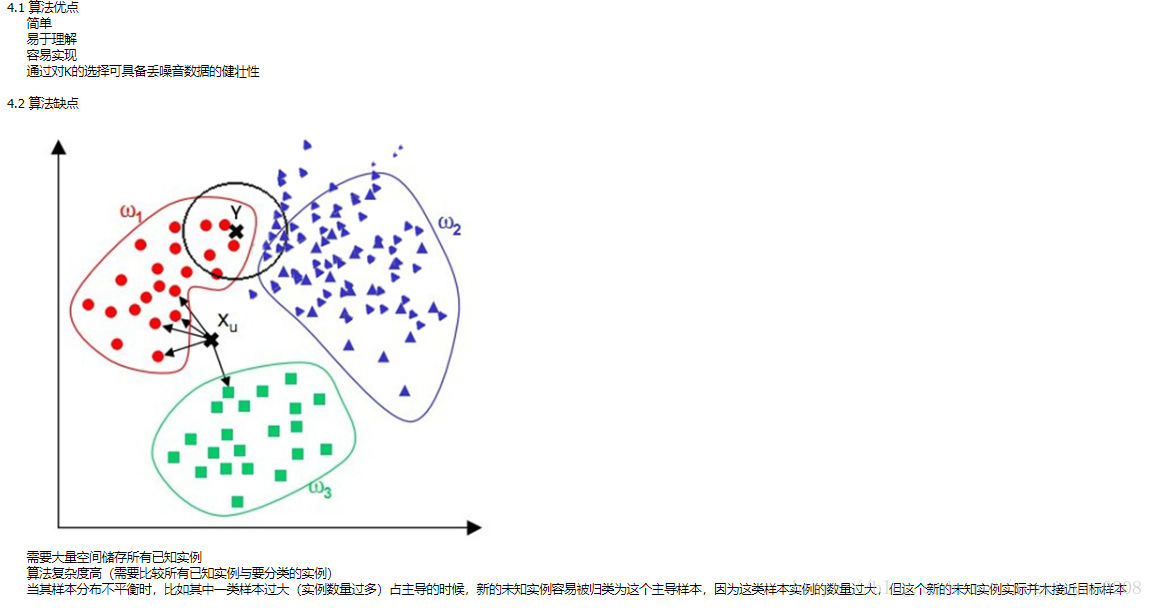
4.演算法的優缺點
5.考慮改進
考慮權重,根據距離加上權重。比如:權重為1/d(d為距離)
6.演算法的實現
相關推薦
2.最鄰近規則分類KNN演算法
1.綜述 2.例子 未知的電影屬於什麼類別呢? 3.演算法描述 3.3計算上述例子 假設K為3,則選取最近的三個點,其中這三個點都是Romance則把未知電影歸類為Romance. 4.演算法的優缺點 5.考慮改進 考慮權重,根據距離加上
機器學習分類篇-最鄰近規則分類KNN
最鄰近規則分類演算法(K-Nearest Neighbor),Cover和Hart在1968年提出了最初的鄰近演算法,也被稱為基於例項的學習或懶惰學習,與決策樹演算法相比,處理訓練集的時候並不建立任何模型,進行分類時才將測試樣例和所有已知例項進行比較進而分類。
機器學習之K-最近鄰規則分類(KNN)演算法
準備分為兩個部分,一個是理論,一個就是程式碼實現。程式碼也可以在我的GitHub上下載,後面有連結。 一、理論知識 相信我的筆記還是比較詳細的 二、程式碼實現KNN演算法 1. 首先要生成一些資料集,以供訓練和測試 我造的資料是關於通過身高
4.1 最鄰近規則分類(K-Nearest Neighbor)KNN演算法
1968年提出的分類演算法 輸入基於示例的學習(instance-based learning),懶惰學習(lazy learning) 例子: 演算法詳述步驟: 為了判斷未知例項類別,用所有已知類別的例項作為參照 選擇引數k 計算未知例項與所有已知例項的距離 選擇
機器學習演算法:kNN(K-Nearest Neighbor)最鄰近規則分類
KNN最鄰近規則,主要應用領域是對未知事物的識別,即判斷未知事物屬於哪一類,判斷思想是,基於歐幾里得定理,判斷未知事物的特徵和哪一類已知事物的的特徵最接近; K最近鄰(k-Nearest Neighbor,KNN)分類演算法,是一個理論上比較成熟的方法,也是最簡單的機器
【深度學習基礎-04】最鄰近規則分類(K Nearest Neighbor)KNN演算法
1 基本概念 Cover和Hart在1968年提出了最初的臨近演算法 分類演算法classfication 輸入基於例項的學習instance-based learning ,懶惰學習lazy learning 2 例子: &n
最鄰近規則分類(K-Nearest Neighbor)KNN算法
bubuko rev created 換行 差值 code 是否 clas 分隔 自寫代碼: 1 # Author Chenglong Qian 2 3 from numpy import * #科學計算模塊 4 import operat
kNN(K-Nearest Neighbor)最鄰近規則分類
K最近鄰分類演算法 方法的思路:如果一個樣本在特徵空間中的k個最相似(即特徵空間中最鄰近)的樣本中的大多數屬於這一類別,則該樣本也屬於這個類別。KNN演算法中,所選擇的鄰居都是已經正確分類的物件。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分類樣本所屬的類
2-2 Python實現最鄰近規則KNN分類應用
最鄰近規則KNN分類應用 資料集介紹 虹膜 150個例項 萼片長度,萼片寬度,花瓣長度,花瓣寬度 (sepal length, sepal width, petal length and petal width) 類
machine learning Knn演算法 最鄰近規則取樣(三)自己實現演算法
import csv import random import math import operator #匯入資料集,split將資料分為兩部分,訓練集和測試集 def loadDataset(filename,split,trainingSet=[],testSet=[]):
文字分類——KNN演算法
上一篇文章已經描述了樸素貝葉斯演算法newgroup的分類實現,這篇文章採用KNN演算法實現newgroup的分類。 文中程式碼參考:http://blog.csdn.net/yangliuy/article/details/7401142 1、KNN演算法描述 對於KNN
機器學習之KNN最鄰近分類演算法
KNN演算法簡介 KNN(K-Nearest Neighbor)最鄰近分類演算法是資料探勘分類(classification)技術中最簡單的演算法之一,其指導思想是”近朱者赤,近墨者黑“,即由你的鄰居來推斷出你的類別。 KNN最鄰近分類演算法的實現原理:為了判斷未知樣
機器學習筆記——最鄰近演算法(KNN)補充
最鄰近演算法補充(K-Nearest Neighbor,KNN) 1、訓練資料集?測試資料集? 我們在使用機器學習演算法訓練好模型以後,是否直接投入真實環境中使用呢?其實並不是這樣的,在訓練好模型後我們往往需要對我們所建立的模型做一個評估來判斷當前機器學習演算法的效能,當我們在
k最鄰近演算法——加權kNN
加權kNN 上篇文章中提到為每個點的距離增加一個權重,使得距離近的點可以得到更大的權重,在此描述如何加權。 反函式 該方法最簡單的形式是返回距離的倒數,比如距離d,權重1/d。有時候,完全一樣或非常接近的商品權重會很大甚至無窮大。基於這樣的原因,在距離求倒數時,在距
KNN(最鄰近值演算法) scala實現
最鄰近值演算法實現 工程目錄結構 程式碼 訓練模型 package com.knn.model /** * 訓練資料模型 * * @param aA 資料a * @param bA 資料b * @param type
KNN(K最鄰近)演算法
kNN演算法簡介: kNN(k Nearest Neighbors)演算法又叫k最臨近方法, 總體來說kNN演算法是相對比較容易理解的演算法之一,假設每一個類包含多個樣本資料,而且每個資料都有一個唯一的類標記表示這些樣本是屬於哪一個分類, kNN就是計算每個樣本資料到待分類資料的距離,取和待分類資料最近的
K一最鄰近演算法在文字自動分類中的應用
一種常用的基於內容的分類演算法-----k--最鄰近演算法(KNN),利用KNN演算法並且結合結合改進的詞特徵權值計算方法和文字相似度的計算方法完成了文字的自動分類.通過KNN方法分類之後的結果的查準率、查全率得以明顯提高. 傳統的分類方法
k最鄰近演算法-KNN,及python3 例項程式碼
剛讀了《machine learning in action》的KNN演算法。 K最近鄰演算法(kNN,k-NearestNeighbo),即計算到每個樣本的距離,選取前k個。從前k個選擇出大多數屬於的class來進行分類,以下特點: 1. 簡單,無需訓練 2. 樣本數量不
Note cs231n影象分類K最鄰近演算法
注:所有筆記內容均來自cs231n學習視訊,部分英文是因為中文翻譯太繞口 最簡單的分類器:Nearest Neighbor(最臨近演算法) 訓練階段:記住所有的訓練資料和標籤(什麼也不做) 預測階段:take new image and go to try to find the
最近鄰規則演算法(KNN)
最近鄰演算法(KNN)是一個基於例項學習的分類演算法。 如果一個例項在特徵空間中的K個最相似(即特徵空間中最近鄰)的例項中的大多數屬於某一個類別,則該例項也屬於這個類別。所選擇的鄰居都是已經正確分類的例項。 演算法步驟: 1、把所有分類好的(有標籤label)的資料(例項