
關於分散式儲存,這是你應該知道的(圖文詳解)(關於儲存的一些好文轉載--1)
轉自:http://stor.51cto.com/art/201711/556946.htm
關於分散式儲存,這是你應該知道的(圖文詳解)
前言
分散式儲存存在的風險,其實就是因為“共享”、“大資料量”、“高效能”和X86伺服器+廉價的磁碟為載體之間的矛盾所產生的,不是有些讀者說的“資料架構”的問題。其實任何儲存都存在這個問題,只是分散式儲存更嚴重。
本文其實是從主機的網路、磁碟的吞吐角度分析存在的風險,所以和用那個廠家的儲存無關。
還有人說你是危言聳聽,如果按照你說的,這麼多人用了分散式儲存有這樣的地雷豈不是要炸飛?軟體定義的東西其實有很多BUG,重要的是能發現問題,事先做好彌補或方案。
還有人說,分散式儲存用到現在也不超過2年,發生你說的問題還早。但是我們已經發現問題了,不能擱置不管。釣魚島問題擱置了,現在還不是造成麻煩了嗎?

拋磚引玉
儲存最重要的指標是什麼?
很多人包括儲存專家都會認為是儲存的效能指標,比如IOPS和吞吐量。但是我認為儲存最重要的是資料的安全性。
一個跑的飛快的儲存,突然資料丟失了,後果會怎麼樣?資料的丟失,對於任何系統來說,都是滅頂之災。
所以,不管什麼樣的儲存,資料的安全可靠都是第一位的。
原來傳統的儲存使用了專用硬體,從可靠性上有比較高的保證,所以大家首先會關注效能指標。但是用X86為基礎的SRVSAN的可靠性就不容樂觀。
為什麼說傳統儲存這個問題不是太突出呢?
除了專用裝置外,還有應用場景和資料量不同等原因。在傳統行業如電信、銀行原來的系統建設是煙囪模式。不但網路是獨立一套,儲存也是。
往往是資料庫服務和日誌記錄,用2臺伺服器和8個埠的小光交相連,小光交下只掛一個儲存。資料量也沒有這樣大,儲存的容量也在5T以下。這樣儲存的資料遷移是很容易和快速的,方法也很多。
由於是專用儲存,所以完全可以採用“非線上”的手段,資料量也不大,可以在夜深人靜的時候停機完成。
進入雲端計算時代,儲存是共享的,資料是應用可靠,提供者不可控,資料量海量增加……傳統的方法失靈了。(可見顧炯的雲世界的“資源池記憶體儲特點”的文章)
我們在2014年下半年,開始搭建以X86為載體的分散式塊儲存,經過嚴格的測試,在同年底投入商用,是業界首個商用的軟體定義的分散式儲存,當時各種媒體都爭相報道。
到現在為止已經商用了近2年,儲存執行穩定,表現優良。並從原來2P裸容量擴容到4.5P。
但是近段時間我卻越來越擔心,因為SRVSAN與生俱來的資料安全隱患,一直被人忽視了,而且主流廠家也沒有意識到這個問題。如果這個隱患在若干年以後爆發,會發生重大性系統故障。
其實我在寫這篇文章前2個月,我已經將這個擔憂和想法告訴了現有分散式塊儲存的產品線總經理,得到他的重視,已經在彌補了。很多軟體定義的東西,就怕想不到,突然發生了,想到了就會有相應的解決方案。
儲存這個東西,大部分讀者並不是太瞭解,從比較基礎知識開始寫,並引出問題和大家一起討論解決的辦法。盤算了一下大致分為七個部分,由於篇幅限制,在本篇將先介紹前三部分:
- 一、儲存型別
- 二、檔案系統
- 三、儲存介質
- 四、Raid和副本
- 五、SRVSAN的架構
- 六、SRVSAN的安全隱患
- 七、解決的方法
一、儲存型別
一般情況下,我們將儲存分成了4種類型,基於本機的DAS和網路的NAS儲存、SAN儲存、物件儲存。物件儲存是SAN儲存和NAS儲存結合後的產物,汲取了SAN儲存和NAS儲存的優點。
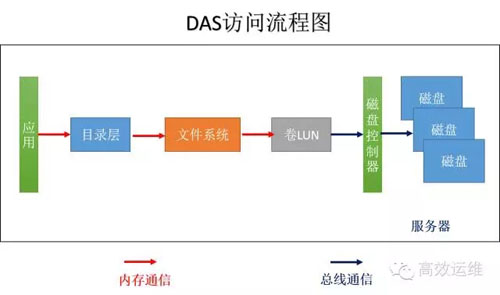
圖1
我們來了解一下應用是怎麼樣獲取它想要的存在儲存裡的某個檔案資訊,並用大家熟悉的Windows來舉例,如圖1。
1、應用會發出一個指令“讀取本目錄下的readme.txt 檔案的前1K資料”。
2、通過記憶體通訊到目錄層,將相對目錄轉換為實際目錄,“讀取C:\ test\readme.txt檔案前1K資料”
3、通過檔案系統,比如FAT32,通過查詢檔案分配表和目錄項,獲取檔案儲存的LBA地址位置、許可權等資訊。
檔案系統先查詢快取中有沒有資料,如果有直接返回資料;沒有,檔案系統通過記憶體通訊傳遞到下一環節命令“讀取起始位置LBA1000,長度1024的資訊”。
4、卷(LUN)管理層將LBA地址翻譯成為儲存的實體地址,並封裝協議,如SCSI協議,傳遞給下一環節。
5、磁碟控制器根據命令從磁碟中獲取相應的資訊。
如果磁碟扇區大小是4K,實際一次I/O讀取的資料是4K,磁頭讀取的4K資料到達伺服器上的內容後,有檔案系統擷取前1K的資料傳遞給應用,如果下次應用再發起同樣的請求,檔案系統就可以從伺服器的記憶體中直接讀取。
不管是DAS、NAS還是SAN,資料訪問的流程都是差不多的。DAS將計算、儲存能力一把抓,封裝在一個伺服器裡。大家日常用的電腦,就是一個DAS系統,如圖1。
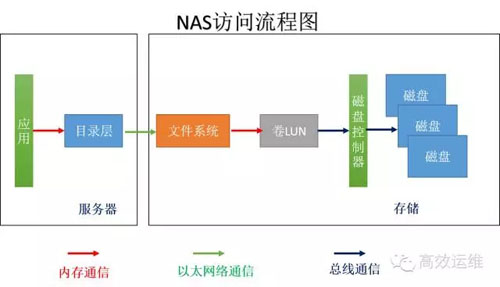
圖2
如果將計算和儲存分離了,儲存成為一個獨立的裝置,並且儲存有自己的檔案系統,可以自己管理資料,就是NAS,如圖2。
計算和儲存間一般採用乙太網絡連線,走的是CIFS或NFS協議。伺服器們可以共享一個檔案系統,也就是說,不管伺服器講的是上海話還是杭州話,通過網路到達NAS的檔案系統,都被翻譯成為普通話。
所以NAS儲存可以被不同的主機共享。伺服器只要提需求,不需要進行大量的計算,將很多工作交給了儲存完成,省下的CPU資源可以幹更多伺服器想幹的事情,即計算密集型適合使用NAS。
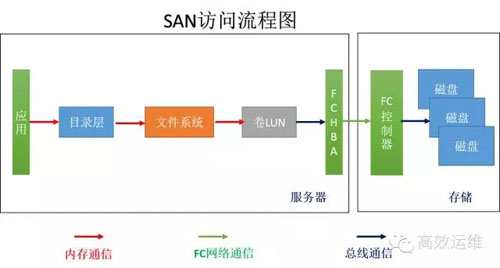
圖3
計算和儲存分離了,儲存成為一個獨立的裝置,儲存只是接受命令不再做複雜的計算,只幹讀取或者寫入檔案2件事情,叫SAN,如圖3。
因為不帶檔案系統,所以也叫“裸儲存”,有些應用就需要裸裝置,如資料庫。儲存只接受簡單明瞭的命令,其他複雜的事情,有伺服器端幹了。再配合FC網路,這種儲存資料讀取/寫入的速度很高。
但是每個伺服器都有自己的檔案系統進行管理,對於儲存來說是不挑食的只要來資料我就存,不需要知道來的是什麼,不管是英語還是法語,都忠實記錄下來的。
但是隻有懂英語的才能看懂英語的資料,懂法語的看懂法語的資料。所以,一般伺服器和SAN儲存區域是一夫一妻制的,SAN的共享性不好。當然,有些裝了叢集檔案系統的主機是可以共享同一個儲存區域的。
從上面分析,我們知道,決定儲存的快慢是由網路和命令的複雜程度決定的。
記憶體通訊速度>匯流排通訊>網路通訊
網路通訊中還有FC網路和乙太網絡。FC網路目前可以實現8Gb/s,但乙太網絡通過光纖介質已經普及10Gb/s,40Gb/s的網絡卡也在使用了。也就是說傳統乙太網絡已經不是儲存的瓶頸了。除了FCSAN,IPSAN也是SAN儲存的重要成員。
對儲存的操作,除了熟悉的讀/寫以外,其實還有建立、開啟、獲取屬性、設定屬性、查詢等等。
對於有大腦的SAN儲存來說,除了讀/寫以外的命令,都可以在本地記憶體中完成,速度極快。
而NAS儲存缺乏大腦,每次向儲存傳遞命令,都需要IP封裝並通過乙太網絡傳遞到NAS伺服器上,這個速度就遠遠低於記憶體通訊了。
- DAS特點是速度最快,但只能自己用;
- NAS的特點速度慢點但共享性好;
- SAN的特點是速度快,但共享性差。
總體上來講,物件儲存同兼具SAN高速直接訪問磁碟特點及NAS的分散式共享特點。
NAS儲存的基本單位是檔案,SAN儲存的基本單位是資料塊,而物件儲存的基本單位是物件,物件可以認為是檔案的資料+一組屬性資訊的組合,這些屬性資訊可以定義基於檔案的RAID引數、資料分佈和服務質量等。
採取的是“控制資訊”和“資料儲存”分離的模式,客戶端用物件ID+偏移量作為讀寫的依據,客戶端先從“控制資訊”獲取資料儲存的真實地址,再直接從“資料儲存”中訪問。
物件儲存大量使用在網際網路上,大家使用的網盤就是典型的物件儲存。物件儲存有很好的擴充套件性,可以線性擴容。並可以通過介面封裝,還可以提供NAS儲存服務和SAN儲存服務。
VMware的vSAN本質就是一個物件儲存。分散式物件儲存就是SRVSAN的一種,也存在安全隱患。因為這個隱患是X86伺服器帶來的。
二、檔案系統
計算機的檔案系統是管理檔案的“賬房先生”。
- 首先他要管理倉庫,要知道各種貨物都放在哪裡;
- 然後要控制貨物的進出,並要確保貨物的安全。
如果沒有這個“賬房先生”,讓每個“夥計”自由的出入倉庫,就會導致倉庫雜亂無章、貨物遺失。
就像那年輕紡城機房剛啟用的時候,大家的貨物都堆在機房裡,沒有人統一管理,裝置需要上架的時候,到一大堆貨物中自行尋找,安裝後的垃圾也沒有人打掃,最後連堆積的地方都找不到,有時自己的貨物找不到了,找到別人的就使用了……。
大家都怨聲載道,後來建立了一個倉庫,請來了倉庫管理員,用一本本子記錄了貨物的歸宿和儲存的位置,建立貨物的出入庫制度,問題都解決了,這就是檔案系統要做的事情。
檔案系統管理存取檔案的介面、檔案的儲存組織和分配、檔案屬性的管理(比如檔案的歸屬、許可權、建立事件等)。
每個作業系統都有自己的檔案系統。比如windows就有常用的FAT、FAT32、NTFS等,Linux用ext1-4的等。
儲存檔案的倉庫有很多中形式,現在主要用的是(機械)磁碟、SSD、光碟、磁帶等等。
拿到這些介質後,首先需要的是“格式化”,格式化就是建立檔案儲存組織架構和“賬本”的過程。比如將U盤用FAT32格式化,我們可以看到是這樣架構和賬本(如圖4):

圖4
主引導區:記錄了這個儲存裝置的總體資訊和基本資訊。比如扇區的大小,每簇的大小、磁頭數、磁碟扇區總數、FAT表份數、分割槽引導程式碼等等資訊。
分割槽表:,即此儲存的賬本,如果分割槽表丟失了,就意味著資料的丟失,所以一般就保留2份,即FAT1和FAT2。分割槽表主要記錄每簇使用情況,當這位置的簇是空的,就代表還沒有使用,有特殊標記的代表是壞簇,位置上有資料的,是指示檔案塊的下一個位置。
目錄區:目錄和記錄檔案所在的位置資訊。
資料區:記錄檔案具體資訊的區域。
通過以下的例子來幫助理解什麼是FAT檔案系統。
假設每簇8個扇區組成一個簇,大小是512*8=4K。根目錄下的readme.txt檔案大小是10K,如圖5:
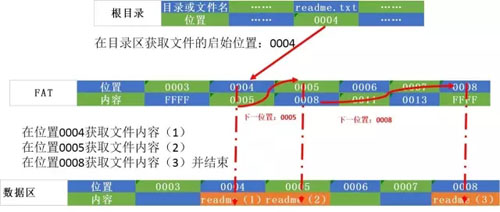
圖5
- 1、在目錄區找到根目錄下檔案readme.txt在FAT表中的位置是0004
- 2、在0004位置對應簇的8個扇區讀取相應檔案塊readme(1)儲存在記憶體,並獲取下一個資料塊的位置0005。
- 3、在0005位置對應簇的8個扇區讀取相應檔案塊readme(2)儲存在記憶體,並獲取下一個資料塊的位置0008。
- 4、在0005位置對應簇的4個扇區讀取相應檔案塊readme(3)儲存在記憶體,並獲得結束標誌。
- 5、將readme(1)、readme(2)、readme(3)組合成為readme檔案。
在這個例子中,我們看到在FAT檔案系統,是通過查詢FAT表和目錄項來確定檔案的儲存位置,檔案分佈是以簇為單位的資料塊,通過“鏈條”的方式來指示檔案資料儲存的文字。
當要讀取檔案時,必須從檔案頭開始讀取。這樣的方式,讀取的效率不高。
不同的Linux檔案系統大同小異,一般都採取ext檔案系統,如圖6.

圖6
啟動塊內是伺服器開機啟動使用的,即使這個分割槽不是啟動分割槽,也保留。
超級塊儲存了檔案系統的相關資訊,包括檔案系統的型別,inode的數目,資料塊的數目
Inodes塊是儲存檔案的inode資訊,每個檔案對應一個inode。包含檔案的元資訊,具體來說有以下內容:
檔案的位元組數
檔案擁有者的User ID
檔案的Group ID
檔案的讀、寫、執行許可權
檔案的時間戳,共有三個:ctime指inode上一次變動的時間,mtime指檔案內容上一次變動的時間,atime指檔案上一次開啟的時間。
連結數,即有多少檔名指向這個inode
檔案資料block的位置
當檢視某個目錄或檔案時,會先從inode table中查出檔案屬性及資料存放點,再從資料塊中讀取資料。
資料塊:存放目錄和檔案資料。
通過讀取\var\readme.txt檔案流程,來理解ext檔案系統,如圖7。
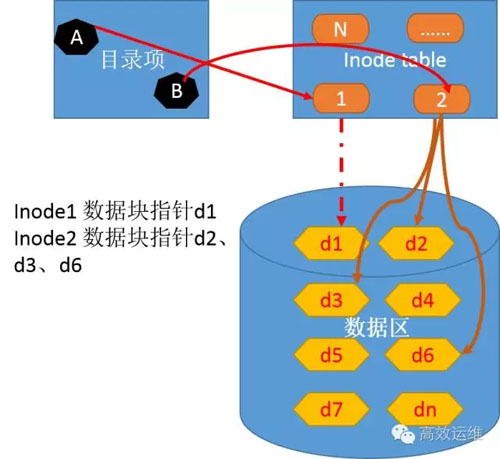
圖7
- 1、根目錄A所對應的inode節點是2,inode1對應的資料塊是d1。
- 2、在檢索d1內容發現,目錄var對應的inode=28,對應的資料塊是d5。
- 3、檢索d5內容發現readme.txt對應的是inode=70。
- 4、Inode70指向資料區d2、d3、d6塊。讀取這些資料塊,在記憶體中組合d2、d3、d6資料塊。
硬碟格式化的時候,作業系統自動將硬碟分成兩個區域。
- 一個是資料區,存放檔案資料;
- 另一個是inode區,存放inode所包含的資訊。
當inode資源消耗完了,儘管資料區域還有空餘空間,都不能再寫入新檔案。
總結:Windows的檔案系統往往是“序列”的,而linux的檔案系統是“並行”的。
再來看分散式的檔案系統。
如果提供持久化層的儲存空間不是一臺裝置,而是多臺,每臺之間通過網路連線,資料是打散儲存在多臺儲存裝置上。也就是說元資料記錄的不僅僅記錄在哪塊資料塊的編號,還要記錄是哪個資料節點的。
這樣,元資料需要儲存在每個資料節點上,而且必須實時同步。做到這一點其實很困難。如果把元資料伺服器獨立出來,做成“主從”架構,就不需要在每個資料節點維護元資料表,簡化了資料維護的難度,提高了效率。
Hadoop的檔案系統HDFS就是一個典型的分散式檔案系統。
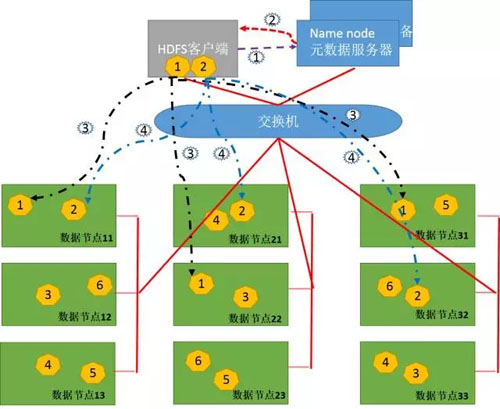
圖8
- 1、Client將FileA按64M分塊。分成兩塊,block1和Block2。
- 2、Client向nameNode傳送寫資料請求,如圖紫色虛線1。
- 3、NameNode節點,記錄block資訊。並返回可用的DataNode給客戶端,如圖紅色虛線2。
Block1: host11,host22,host31
Block2: host11,host21,host32
- 4、client向DataNode傳送block1;傳送過程是以流式寫入。
流式寫入過程:
1)將64M的block1按64k的package劃分;
2)然後將第一個package傳送給host11;
3)host11接收完後,將第一個package傳送給host22,同時client想host11傳送第二個package;
4)host22接收完第一個package後,傳送給host31,同時接收host11發來的第二個package。
5)以此類推,如圖黑色虛線3所示,直到將block1傳送完畢。
6)host11,host22,host31向NameNode和 Client傳送通知,說“訊息傳送完了”。
7)client收到發來的訊息後,向namenode傳送訊息,說我寫完了。這樣就真完成了。
8)傳送完block1後,再向host11,host21,host32傳送block2,如圖藍色虛線4所示。
……….
HDFS是分散式儲存的雛形,分散式儲存將在以後詳細介紹。
三、儲存介質
倉庫有很多種儲存的介質,現在最常用的是磁碟和SSD盤,還有光碟、磁帶等等。磁碟一直以價效比的優勢佔據了霸主的地位。
圓形的磁性碟片裝在一個方的密封盒子裡,執行起來吱吱的響,這就是我們常見的磁碟。磁片是真正存放資料的介質,每個磁片正面和背面上都“懸浮”著磁頭。
磁碟上分割為很多個同心圓,每個同心圓叫做磁軌,每個磁軌又被分割成為一個個小扇區,每個扇區可以儲存512B的資料。當磁頭在磁片上高速轉動和不停換道,來讀取或者寫入資料。
其實磁片負責高速轉動,而磁頭只負責在磁片上橫向移動。決定磁碟效能的主要是磁片的轉速、磁頭的換道、磁碟、每片磁片的容量和介面速度決定的。轉速越高、換道時間越短、單片容量越高,磁碟效能就越好。

圖9

圖10
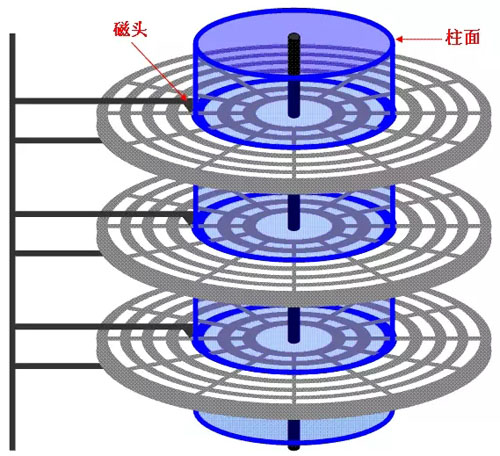
圖11
衡量磁碟效能主要參考 IOPS 和吞吐量兩個引數。
IOPS就是一秒鐘內磁碟進行了多少次的讀寫。
吞吐量就是讀出了多少資料。
其實這些指標應該有前提,即是大包(塊)還是小包(塊),是讀還是寫,是隨機的還是連續的。一般我們看到廠家給的磁碟IOPS效能一般是指小包、順序讀下的測試指標。這個指標一般就是最大值。
目前在X86伺服器上我們常使用的 SATA、SAS磁碟效能:

圖12
實際生產中估算,SATA 7200轉的磁碟,提供的IOPS為60次左右,吞吐量在70MB/s。
我們2014年首次使用的裸容量2P的SRVSAN儲存的資料持久化層採用57臺X86伺服器,內建12塊SATA7200 3TB硬碟。共684塊磁碟,大約只提供41040次IOPS和47.88GB/s。
這些指標顯然是不能滿足儲存需要的,需要想辦法“加速”。
機械磁碟其實也做了很多優化,比如扇區地址的編號不是連續的。
因為磁片轉的夠快(7200轉/分鐘即1秒鐘轉120轉,轉一圈是8.3毫秒,也就是在讀寫同一個磁軌最大時延是8.3秒),防止磁頭的讀寫取錯過了,所以扇區的地址並不是連續的,而是跳躍編號的,比如2:1的交叉因子(1、10、2、11、3、12…..)。
同時磁碟也有快取,具有佇列,並不是來一個I/O就讀寫一個,而是積累到一定I/O,根據磁頭的位置和演算法完成的。I/O並不是一定是“先到先處理”,而是遵守效率。
加速最好的辦法就是使用SSD盤。磁碟的控制部分是由機械部分+控制電路來構成,機械部分的速度限制,使磁碟的效能不可能有大的突破。而SSD採用了全電子控制可以獲得很好的效能。
SSD是以快閃記憶體作為儲存介質再配合適當的控制晶片組成的儲存裝置。目前用來生產固態硬碟的NAND Flash有三種:
- 單層式儲存(SLC,儲存1bit資料)
- 二層式儲存(MLC,儲存4bit資料)
- 三層式儲存(TLC,儲存8bit資料)
SLC成本最高、壽命最長、但訪問速度最快,TLC成本最低、壽命最短但訪問速度最慢。為了降低成本,用於伺服器的企業級SSD都用了MLC,TLC可以用來做U盤。

圖13
SSD普及起來還有一點的障礙,比如成本較高、寫入次數限制、損壞時的不可挽救性及當隨著寫入次數增加或接近寫滿時候速度會下降等缺點。
對應磁碟的最小IO單位扇區,page是SSD的最小單位。
比如每個page儲存512B的資料和218b的糾錯碼,128個page組成一個塊(64KB),2048個塊,組成一個區域,一個快閃記憶體晶片有2個區域組成。Page的尺寸越大,這個閃訊晶片的容量就越大。
但是SSD有一個壞習慣,就是在修改某1個page的資料,會波及到整塊。需要將這個page所在的整塊資料讀到快取中,然後再將這個塊初始化為1,再從快取中讀取資料寫入。
對於SSD來說,速度可能不是問題,但是寫的次數是有限制的,所以塊也不是越大越好。當然對於機械磁碟來說也存在類似問題,塊越大,讀寫的速度就越快,但浪費也越嚴重,因為寫不滿一塊也要佔一塊的位置。
不同型號不同廠家的SSD效能差異很大,下面是我們的分散式塊儲存作為快取使用的SSD引數:
採用PCIe 2.0介面,容量是1.2T,綜合讀寫IOPS(4k小包)是260000次,讀吞吐量1.55GB/s,寫吞吐量1GB/s。
在1臺SRVSAN的伺服器配置了一塊SSD作為快取和12塊7200轉 3T SATA盤,磁碟只提供1200次、1200M的吞出量。
遠遠小於快取SSD提供的能力,所以直接訪問快取可以提供很高的儲存效能,SRVSAN的關鍵是計算出熱點資料的演算法,提高熱點資料的命中率。
用高成本的SSD做為快取,用廉價的SATA磁碟作為容量層