
為什麼要學資料庫原理?
只會寫程式碼的是碼農;學好資料庫,基本能混口飯吃;在此基礎上再學好作業系統和計算機網路,就能當一個不錯的程式設計師。如果能再把離散數學、數位電路、體系結構、資料結構/演算法、編譯原理學通透,再加上豐富的實踐經驗與領域特定知識,就能算是一個優秀的工程師了。
計算機其實就是儲存/IO/CPU三大件; 而計算說穿了就是兩個東西:資料與演算法(狀態與轉移函式)。常見的軟體應用,除了各種模擬模擬、模型訓練、視訊遊戲這些屬於計算密集型應用外,絕大多數都屬於資料密集型應用。從最抽象的意義上講,這些應用乾的事兒就是把資料拿進來,存進資料庫,需要的時候再拿出來。
抽象是應對複雜度的最強武器。作業系統提供了對儲存的基本抽象:記憶體定址空間與磁碟邏輯塊號。檔案系統在此基礎上提供了檔名到地址空間的KV儲存抽象。而資料庫則在其基礎上提供了對應用通用儲存需求的高階抽象。
網際網路應用大多屬於資料密集型應用,對於真實世界的資料密集型應用而言,除非你準備從基礎元件的輪子造起,不然根本沒那麼多機會去擺弄花哨的資料結構和演算法。甚至寫程式碼的本事可能也沒那麼重要:可能只會有那麼一兩個Ad Hoc演算法需要在應用層實現,大部分需求都有現成的輪子可以使用,主要的創造性工作往往在資料模型與資料流設計上。實際生產中,資料表就是資料結構,索引與查詢就是演算法。而應用程式碼往往扮演的是膠水的角色,處理IO與業務邏輯,其他大部分工作都是在資料系統之間搬運資料。
在最寬泛的意義上,有狀態的地方就有資料庫。它無所不在,網站的背後、應用的內部,單機軟體,區塊鏈裡,甚至在離資料庫最遠的Web瀏覽器中,也逐漸出現了其雛形:各類狀態管理框架與本地儲存。“資料庫”可以簡單地只是記憶體中的雜湊表/磁碟上的日誌,也可以複雜到由多種資料系統整合而來。關係型資料庫只是資料系統的冰山一角(或者說冰山之巔),實際上存在著各種各樣的資料系統元件:
- 資料庫:儲存資料,以便自己或其他應用程式之後能再次找到(PostgreSQL,MySQL,Oracle)
- 快取:記住開銷昂貴操作的結果,加快讀取速度(Redis,Memcached)
- 搜尋索引:允許使用者按關鍵字搜尋資料,或以各種方式對資料進行過濾(ElasticSearch)
- 流處理:向其他程序傳送訊息,進行非同步處理(Kafka,Flink,Storm)
- 批處理:定期處理累積的大批量資料(Hadoop)
架構師最重要的能力之一,就是了解這些元件的效能特點與應用場景,能夠靈活地權衡取捨、整合拼接這些資料系統。絕大多數工程師都不會去從零開始編寫儲存引擎,因為在開發應用時,資料庫已經是足夠完美的工具了。關係型資料庫則是目前所有資料系統中使用最廣泛的元件,可以說是程式設計師吃飯的主要傢伙,重要性不言而喻。
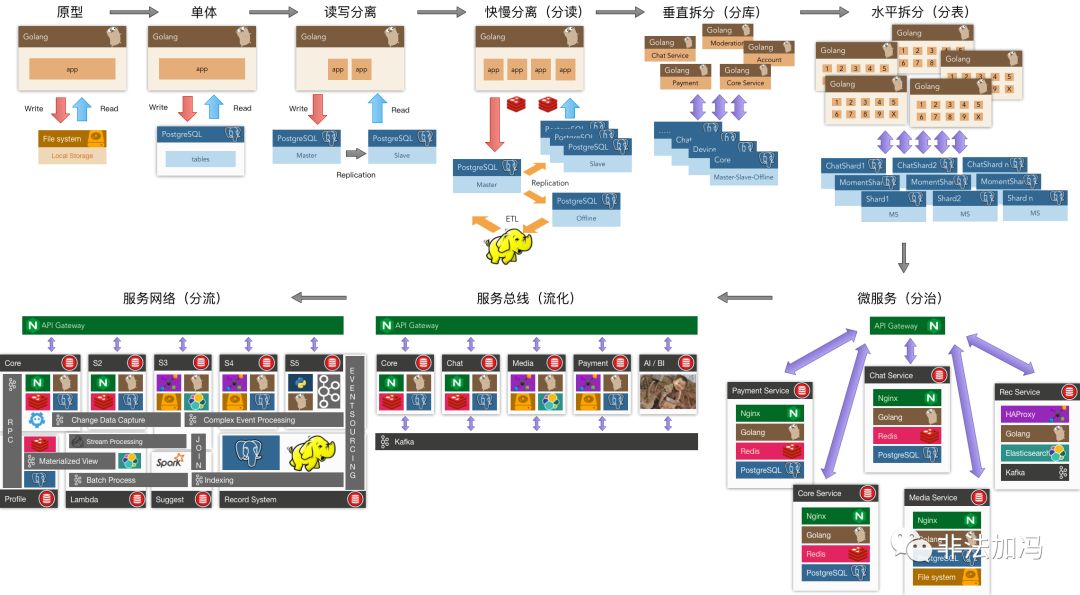
圖:架構演化:一種分拆方法
對玩具應用而言,使用記憶體變數與檔案來儲存狀態也許已經綽綽有餘了。但隨著系統的增長,我們會遇到越來越多的挑戰:軟硬體故障把資料搞成一團漿糊(可靠性);狀態太多而記憶體太小放不下(可伸縮性);併發訪問控制導致程式碼複雜度發生爆炸(可維護性),諸如此類。這些問題相當棘手,卻又相當普遍,資料庫就是用來解決這些問題的。分拆是架構演化的重要方法論,資料庫將狀態管理的職能從應用程式中分拆出來,即所謂的“狀態與計算相分離”。資料庫將程式設計師從重複造輪子的泥潭中解救出來,極大地解放了生產力。
每個系統都服務於一個目的,解決一類問題。問題比方法更重要。但現實很遺憾,以大多數學生,甚至相當一部分公司能接觸到的現實問題而言,拿幾個檔案甚至在記憶體裡放著估計都能應付大多數場景了(需求簡單到低階抽象就可以Handle)。沒什麼機會接觸到資料庫真正要解決的問題,也就難有真正使用與學習資料庫的驅動力,更別提資料庫原理了。
所以我也理解當前這種填鴨教學現狀的苦衷:工作之後很難有這麼大把的完整時間來學習原理了,所以老師只好先使勁灌輸,多少讓學生對這些知識有個印象。等學生參加工作後真正遇到這些問題,也許會想起大學好像還學了個叫資料庫的東西,這些知識就會開始反芻。
資料庫,尤其是關係型資料庫,非常重要。那為什麼要學習其原理呢?
對優秀的工程師來說,只會用資料庫是遠遠不夠的。學習原理對於當CRUD BOY搬磚收益並不大,但當通用元件真的無解需要自己擼起袖子上時,沒有金坷垃怎麼種莊稼?設計系統時,理解原理能讓你以最少的複雜度代價寫出更可靠高效的程式碼;遇到疑難雜症需要排查時,理解原理能帶來精準的直覺與深刻的洞察。
資料庫是一個博大精深的領域,儲存I/O計算無所不包。其主要原理也可以粗略分為幾個部分:資料模型設計原理(應用)、儲存引擎原理(基礎)、索引與查詢優化器的原理(效能)、事務與併發控制的原理(正確性)、故障恢復與複製系統的原理(可靠性)。 所有的原理都有其存在意義:為了解決實際問題。
例如資料模型設計中的正規化理論,就是為了解決資料冗餘這一問題而提出的,它是為了把事情做漂亮(可維護)。它是模型設計中一個很重要的設計權衡:通常而言,冗餘少則複雜度小/可維護性強,冗餘高則效能好。具體來說,冗餘欄位能加快特定型別的讀取(通過消除連線),但在寫入時就需要做更多的工作:維護多物件副本間的一致性,避免多物件事務併發執行時發生踩踏。這就需要仔細權衡利弊,選擇合適的規範化等級。資料模型設計,就是生產中的資料結構設計。不瞭解這些原理,就難以提取良好的抽象,其他工作也就無從談起。
而關係代數與索引的原理,則在查詢優化中扮演重要的角色,它是為了把事情做得快(效能,可擴充套件)。當資料量越來越大,SQL寫的越來越複雜時,它的意義就會體現出來:怎樣寫出等價但是更高效的查詢?當查詢優化器沒那麼智慧時,就需要人來幹這件事。這種優化往往有四兩撥千斤的效果,比如一個需要幾秒的KNN查詢,如果知道R樹索引的原理,就可以通過改寫查詢,建立GIST索引優化到1毫秒內,千倍的效能提升。不瞭解索引與查詢設計原理,就難以充分發揮資料庫的效能。
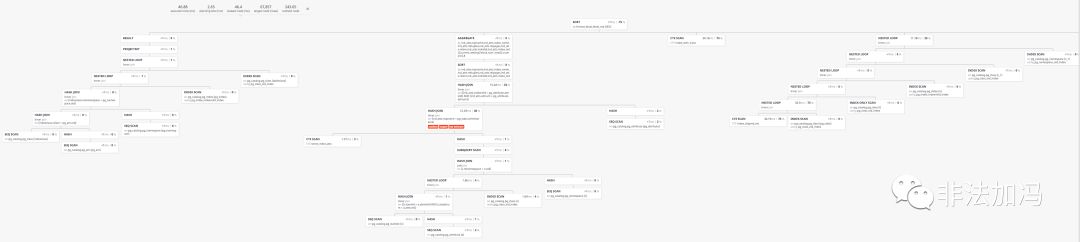
圖:估算表膨脹率的複雜SQL一例,能在50ms內完成
事務與併發控制的原理,是為了把事情做正確。事務是資料處理領域最偉大的抽象之一,它提供了很多有用的保證(ACID),但這些保證到底意味著什麼?事務的原子性讓你在提交前能隨時中止事務並丟棄所有寫入,相應地,事務的永續性則承諾一旦事務成功提交,即使發生硬體故障或資料庫崩潰,寫入的任何資料也不會丟失。這讓錯誤處理變得無比簡單,所有可能的結果被歸結為兩種情況:要麼成功完事,要麼失敗了事(或重試)。有了後悔藥,程式設計師不用再擔心半路翻車會留下慘不忍睹的車禍現場了。
另一方面,事務的隔離性則保證同時執行的事務無法相互影響(在可序列化隔離等級下)。更進一步,資料庫提供了不同的隔離等級保證,以供程式設計師在效能與正確性之間進行權衡。編寫併發程式並不容易,在幾萬TPS的負載下,各種極低概率,匪夷所思的問題都會出現:事務之間相互踩踏,丟失更新,幻讀與寫入偏差,慢查詢拖慢快查詢導致連線堆積,單表資料庫併發增大後的效能急劇惡化,比如我遇到的一個最靈異的例子是:快慢查詢總量都減少,但因相對比例變化導致資料庫被壓垮。這些問題,在低負載的情況下會潛伏著,隨著規模量級增長突然跳出來,給你一個大大的驚喜。現實中真正可能出現的各類異常,也絕非SQL標準中簡單的幾種異常能說清的。 不理解事務的原理,意味著應用的正確性與資料的完整性可能遭受不必要的損失。
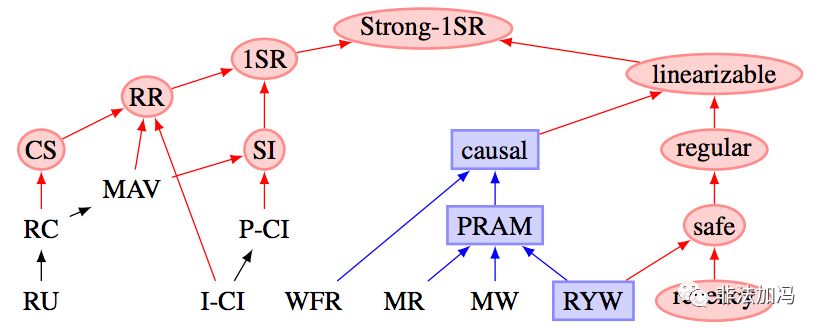
圖:隔離等級與一致性
故障恢復與複製的原理,可能對於普通程式設計師沒有那麼重要,但架構師與DBA必須清楚。高可用是很多應用的追求目標,但什麼是高可用,高可用怎麼保證?讀寫分離?快慢分離?異地多活?x地x中心?說穿了底下的核心技術其實就是複製(Replication)(或再加上自動故障切換(Failover))。這裡有無窮無盡的坑:複製延遲帶來的各種靈異現象,網路分割槽與腦裂,存疑事務,諸如此類。 不理解複製的原理,高可用就無從談起。
對於一些程式設計師而言,可能資料庫就是“增刪改查”,包一包介面,原理似乎屬於“屠龍之技”。如果止步於此,那原理確實沒什麼好學的,但有志者應當打破砂鍋問到底的精神。私認為只瞭解自己本領域知識是不夠的,只有把當前領域賴以建立的上層領域摸清楚,才能稱為專家。在資料庫面前,後端也是前端;對於程式設計師的知識棧而言,資料庫是一個合適的棧底。
https://www.sohu.com/a/237554990_671058