
用SPSS-Modeler分析銀行信用風險評分方法
實際經濟生活中引發信用風險、市場風險和操作風險的因素往往是相伴而生,由於多重因素的風險管理失控而導致整個機構遭受滅頂之災,銀行業監管機構要求商業銀行對信用風險、市場風險和操作風險資本需求的評估採取一種全方位的風險管理觀。
因業務需要,銀行必需承擔風險。一般是風險越大,預期收益越大。風險與收益有非對稱關係。風險本身並不是壞東西,我們的主要責任是管理風險。最糟糕的是對風險沒有正確認識和錯誤管理風險。
銀行獲取的客戶資訊具有不完全性,信用風險具有非系統性特性,信用風險收益率呈非正態分佈。我們做實驗的目的就是在這種情況下使用以計量模型為代表的量化管理工具和手段對申請貸款的人的信用風險進行可行的分析。運用先進的資料探勘技術和統計分析方法,通過對申請貸款的企業或個人客戶的資料資料進行統計分析,挖掘客戶特徵與信用風險之間的關係,並將其發展成為預測模型,以綜合評分來評估客戶未來的某種信用表現。
第一章 引言
1.1資料分析的背景
2008年9月15日,美國第四大投資銀行雷曼兄弟按照美國公司破產法案的相關規定提交了破產申請,成為了美國有史以來倒閉的最大金融公司。其引發的連鎖反應致使信貸市場陷入混亂。
次貸的產生是由於在美國存在著一批人,這批人沒有什麼信譽擔保,甚至目前也沒有什麼償還能力,例如一些名牌大學的大學生。但是當他們畢業之後就會有償還能力,所以,基於此,如果這批人申請貸款來買房,銀行就會降低貸款的標準,也就次於了正常的按揭貸款(即用房產等固定資產進行抵押來申請貸款)。當然了,與此同時,次貸的利息也會比正常貸款的利息要高很多。次貸的產生迎合了一句話——高風險意味著高回報。因為追逐利益的慾望的驅使,次貸閃亮登場了!
但是人們在追求高回報的時候漸漸的忽略了高風險!隨著次貸的產生,房地產市場逐漸走熱,畢竟人們都有貸款可以買房了。在次貸的刺激下,房價攀升,而次貸的風險也就隨之消失在人們記憶中,因為房價在攀升,所以如果一個人無法償還貸款,那麼他買的房子將和他的貸款相抵,不僅如此,因為房子的升值,相反銀行還能掙錢。但是房子不可能總在漲,所以在房價走低的時候,問題就發生了,隨著房價的走低,和上述所講相同,如果一個人無法償還貸款,那麼他買的房子將不能夠償還他的貸款,因為房子貶值了嘛。那麼銀行就會造成虧損。
有的金融機構,還故意將高風險的按揭貸款,“靜悄悄”地打包到證券化產品中去,向投資者推銷這些有問題的按揭貸款證券。突出的表現,是在發行按揭證券化產品時,不向投資者披露房主不僅難以支付的高額可調息按揭付款、而且購房者按揭貸款是零首付的情況。而評級市場的不透明和評級機構的利益衝突,又使得這些嚴重的高風險資產得以順利進入投資市場。也就是說銀行為了避免風險,選擇將次貸當作一種債卷出賣,這樣的債券的產生刺激了次貸,所以,將危機進一步的擴大,全球各大投資銀行都購買了很多次貸債券,所以在房價走低時候,實際上給美國銀行埋單的是全球的投資銀行!
所以,商業銀行應該更好的對待風險,這有兩個辦法,一是規避風險,而是承擔一定的風險,求得最大利潤。
現代社會,信用對個人和企業都是無比重要的品質。個人,有信用,在銀行可以辦理信用卡進行透支;在電信,當你要出國開會或者旅遊,開通國際長途可以不用交押金;愛車上保險,也可以打折。企業,有信用可以獲取大額的透支或者融資額度。便宜服務不是每個客戶都能享受得到的,銀行先考察客戶的信用,再決定是否發放信用卡,以及卡片的型別(普卡、金卡、鑽石卡)和額度;開通國際長途不要押金需要你符合一系列條件才行;汽車保險打折要求你有良好的索賠記錄。
信用評分是使用統計模型的方法來對潛在客戶和已有客戶在貸款時的風險通過評分卡的方式進行評價的一種方法。
1.2分析的目的與意義
信用風險產生的原因及特點:銀行獲取客戶資訊的不完全性。銀行只能通過客戶提交的各種資料、報表和其他有限途徑間接地獲取資訊,而這種資訊的不完全性可能會是未來的風險隱患。信用風險具有非系統性特性。貸款企業或個人的還款能力雖然會受到整體經濟大環境的影響,但是大多數情況下取決於其自身財務狀況、經營的好壞以及還款意願等個體因素。信用風險收益率呈非正態分佈。在大多數情況下貸款能夠順利收回,此時銀行可以得到一定的利息收入,但是當壞賬的小概率事件發生時,銀行將損失整個本息。
對於信用評級,可以運用先進的資料探勘技術和統計分析方法,通過對申請貸款的企業或個人客戶的資料資料進行統計分析,挖掘客戶特徵與信用風險之間的關係,並將其發展成為預測模型,以綜合評分來評估客戶未來的某種信用表現。
信用評分卡建立以後可以幫助銀行一線人員進行多種決策:是否同意某筆貸款的發放、是否同意個人的信用卡申請及向其發放何種型別的信用卡、是否同意客戶關於提高信用卡透支額度的申請、當客戶的信用卡發生延期還款時,催討策略如何。
這種形式便於理解和使用;監管機構容易對銀行稽核標準合規性進行有效監管。通過信用評分卡方式,監管機構很容易看到銀行使用了哪些因素作為稽核標準,從而判斷這種標準是否合規;信用評分卡很容易實施和監控。
第二章 資料稽核與資料預處理
2.1原始資料表說明
建立新的工作流之後,讀入原始資料表,可以看到原始資料表有3000條記錄,表中共有11個欄位,分別是年齡、收入、孩子數量、家庭人口數、在現住址時間、在現工作時間、住房種類、國籍、信用卡型別、是否違約、權重,如圖2-1所示。資料的型別,資料的範圍,如圖2-2所示。資料型別的詳細情況如表2-1所示。
圖2-1 原始資料表
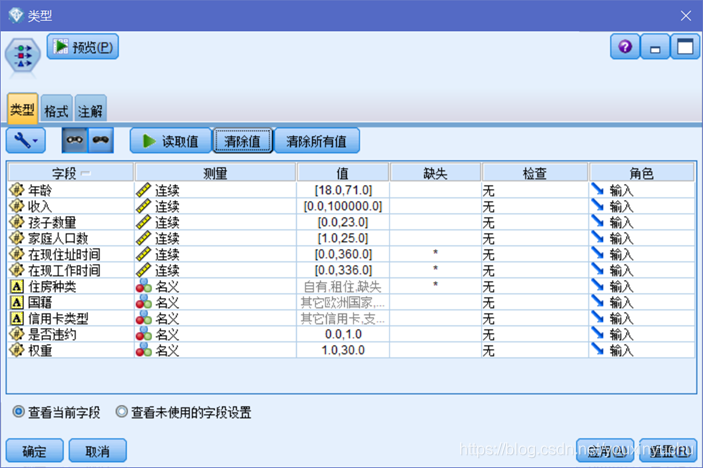
圖2-2 資料型別
表2-1 信用評分建模資料變數情況表
2.2資料分佈與資料稽核
輸出資料稽核,看資料的情況,可以看到,這11個欄位的屬性,在現住址時間和在現工作時間這兩個欄位的有效資料分別是2907和2966,小於總資料量,其他的9個欄位有效數都是3000如圖2-3所示。在資料中在現住址時間這一欄位裡面,999表示資料缺失,如圖2-4所示。
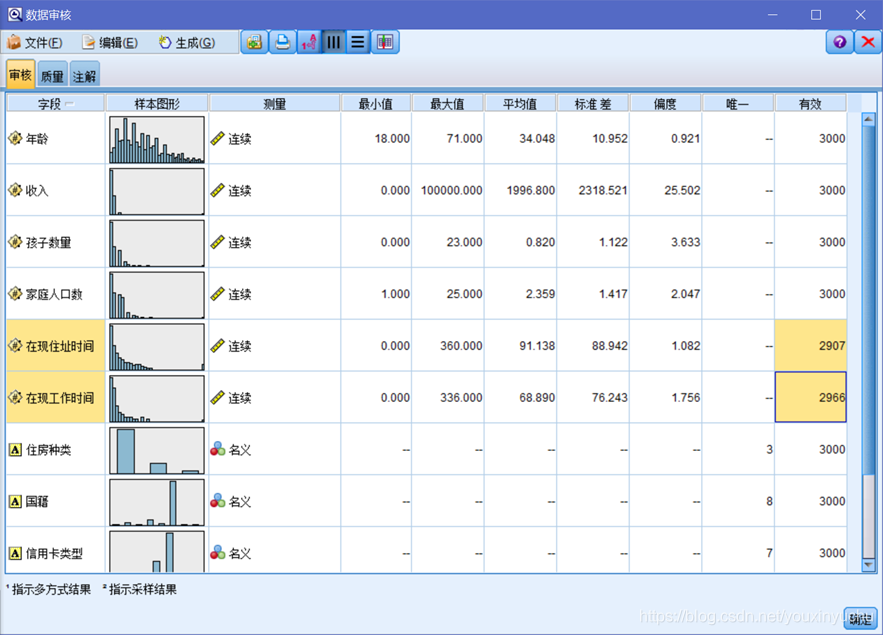
圖2-3資料稽核
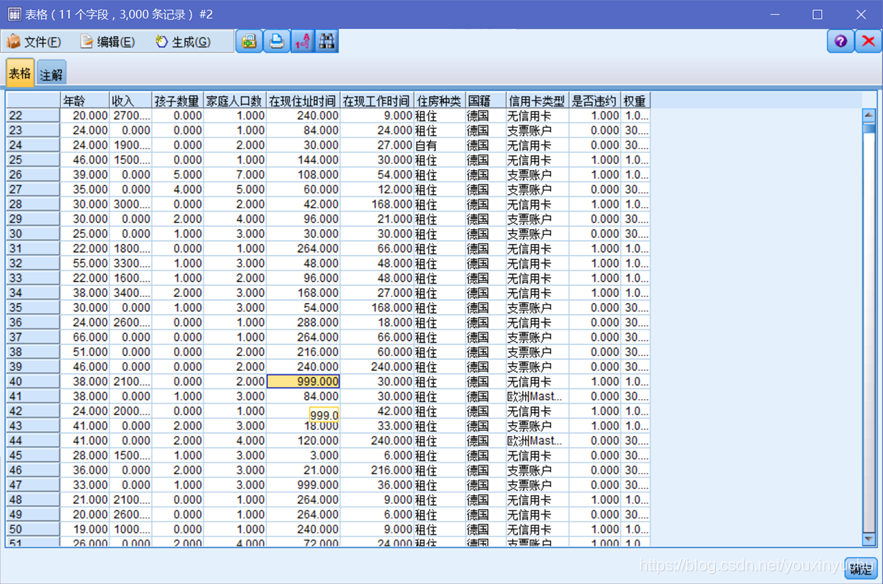
圖2-4 在現住址時間資料缺失
2.3資料預處理
從原始資料表中看到孩子數量可能和家庭人口數有相關性,所以對這兩個屬性做一個相關性分析,看看這兩個屬性之間的相關性如何。如圖2-5所示。
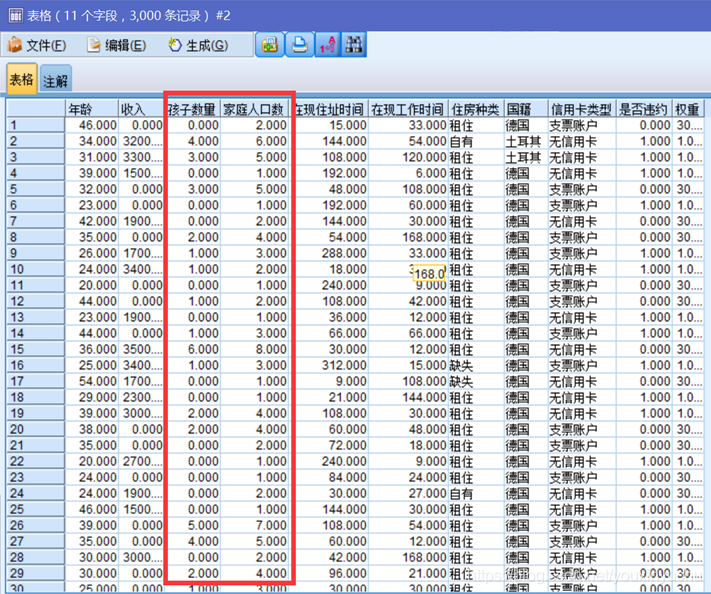
圖2-5 孩子數量和家庭人口數
選擇相關性節點計算孩子數量和家庭人口數量的相關性,直觀的表達出是否相關以及如果相關的話相關程度的強弱。設定如圖2-6所示,結果如圖2-7所示。從結果來看,孩子數量和家庭人口數的相關性為0.949,這說明二者有強相關關係。所以,在後續的資料中,就可以選擇把家庭人口數這個欄位過濾掉,只考慮孩子數量就可以了,如圖2-8所示。
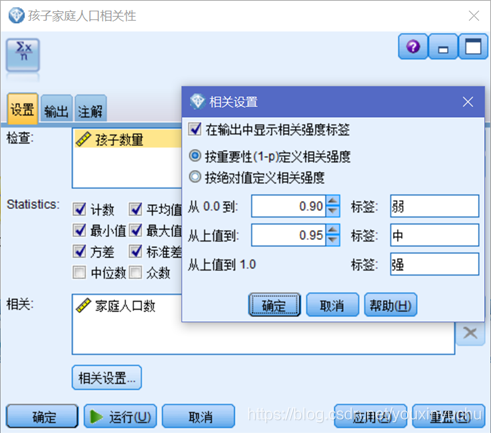
圖2-6 設定計算相關性的節點

圖2-7 孩子數量和家庭人口數的相關性
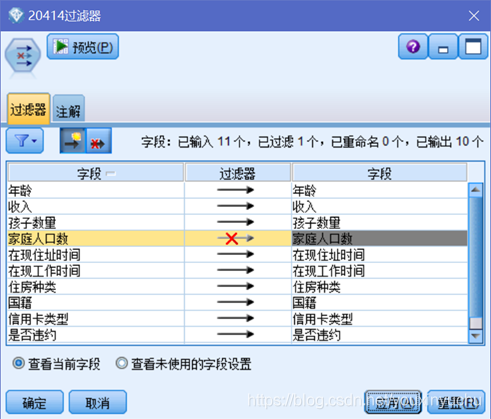
圖2-8 過濾家庭人口數屬性
從前面的觀察中知道資料表有權重這一欄位,所以應該去看一下權重的具體數值,選擇分佈節點,再選取權重欄位,可以看到好客戶的權重值是30,意味著一個好客戶代表著30個好客戶。如圖2-9所示。
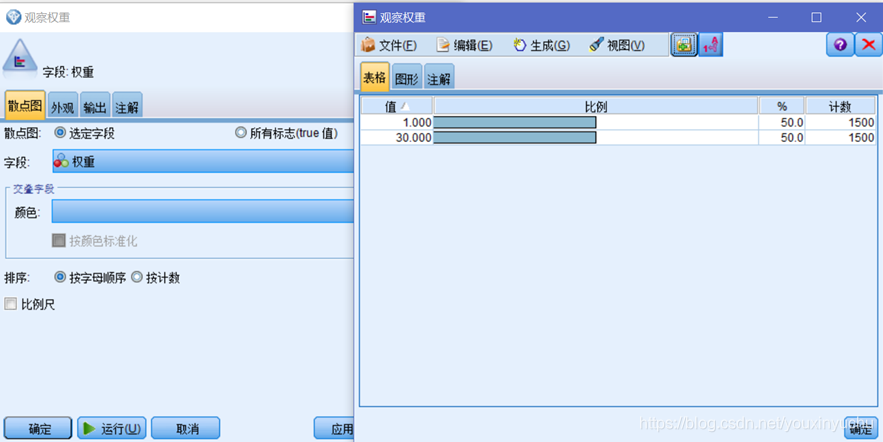
圖2-9 好壞客戶的權重值
知道了權重以後,下一步將好壞客戶篩選出來,確定各自各有多少個。使用選擇節點,用“=”函式,等0的是好客戶,等1的是違約客戶,輸出結果是好客戶有1500條記錄,違約客戶有1500條記錄,根據他們的權重,這意味著好客戶是有1500*30=45000條記錄,違約客戶有1*1500=1500條記錄,如圖2-10所示。
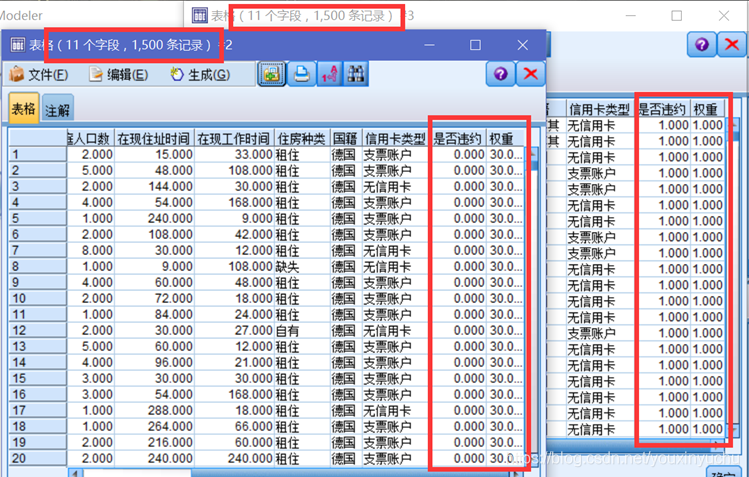
圖2-10 篩選好壞使用者
知道了好使用者在原始資料表中的數量和權重之後,就要考慮把好使用者的數量還原成45000個,以便於後面的資料分析。使用平衡節點來進行這一步的操作,將權重為30的抽取30次,權重為1的抽取1次。得到的新的分佈結果如圖2-11所示。
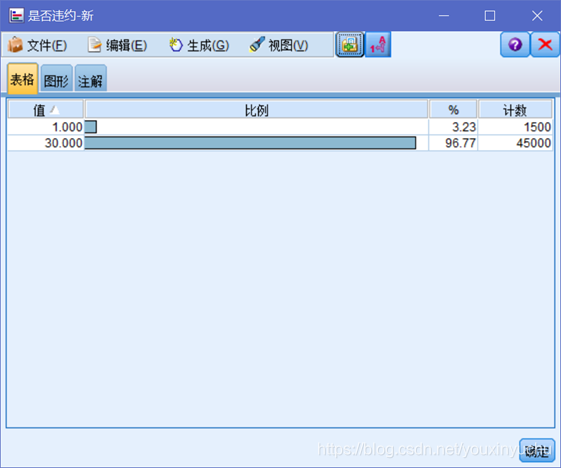
圖2-11 調整過權重的是否違約佔比
第三章 資料分析
3.1總體思路
(一)通過前面的資料預處理可以看到實驗所用的資料比較多,資料比較雜亂,所以就想到先把資料進行分箱,通過分箱將資料劃分為幾個段。
(二)通過計算各欄位的WOE值和IV值知道欄位的證據權重和預測資訊的能力的大小。
(三)用第二步得到的內容構建迴歸模型。
(四)藉助迴歸模型建立評分模型,即評估信用等級的模型。
(五)用K-S法驗證建立的迴歸模型。
3.2基於SPSS Modeler的資料分析過程
3.2.1對連續輸入變數分箱
第一步,對輸入變數進行分箱操作,目的是通過減少變數取值個數,提高建模效率。連續變數的分箱原則有四,分別是分箱數應當適中,不宜過多或過少。過少區分度不足,過多則穩定性不強且不方便管理;各個分箱內的記錄數合理,不應過多或過少;結合目標變數,分箱應該能表現出明顯的趨勢特徵;相鄰分箱的目標變數分佈差異應該較大。
首先對連續變數進行分箱。一共有5個連續變數,分別是年齡、收入、孩子數量、現住址時間、現工作時間。所以這一小節一共有5個分箱操作。在分級化節點裡面使用最優分級自動將上述的5個屬性進行分級操作,並匯出節點。新生成的屬性加上_bin字尾。如圖3-1所示。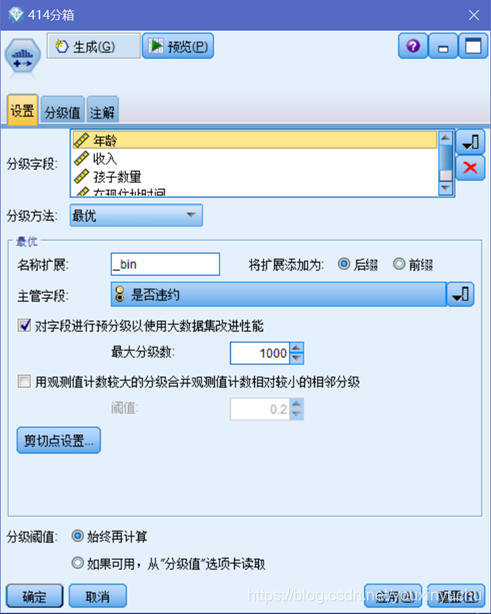
圖3-1 自動分級節點
(一)對年齡這一屬性進行分箱操作。一共分為年齡<23、23<=年齡<28、28<=年齡<46、年齡>=46四個分箱並生成新的匯出節點,如圖3-2所示。
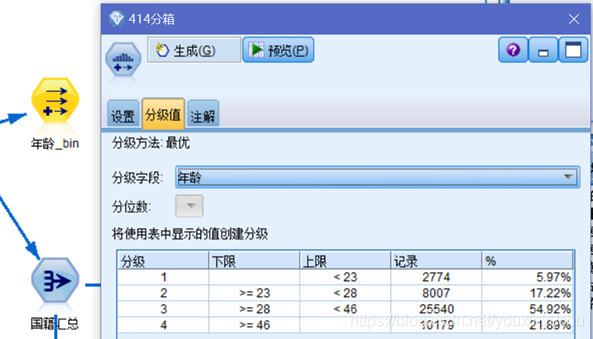
圖3-2 按年齡分箱
(二)對收入這一屬性進行分箱操作。一共分為收入<1000、1000<=收入<2400、2400<=收入三個分箱並生成匯出節點,如圖3-3所示。

圖3-3 按收入分箱
(三)對孩子數量這一屬性進行分箱操作。一共分為孩子數量<1、孩子數量>=1二個分箱並生成匯出節點,如圖3-4所示。
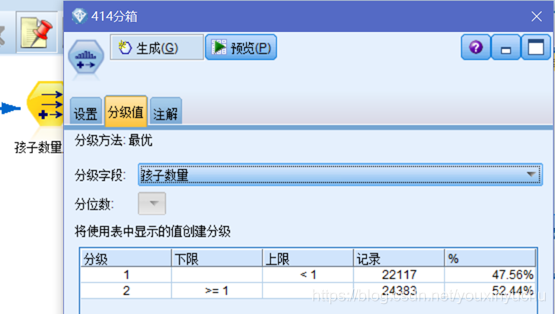
圖3-4 按孩子數量分箱
(四)對現住址時間這一屬性進行分箱操作。一共分為現住址時間<18、18<=現住址時間兩個分箱並生成匯出節點,如圖3-5所示。

圖3-5 按在現住址時間分箱
(五)對現工作時間這一屬性進行分箱操作。一共分為現工作時間<18、18<=現工作時間<96、96<=現工作時間三個分箱並生成匯出節點,如圖3-6所示。
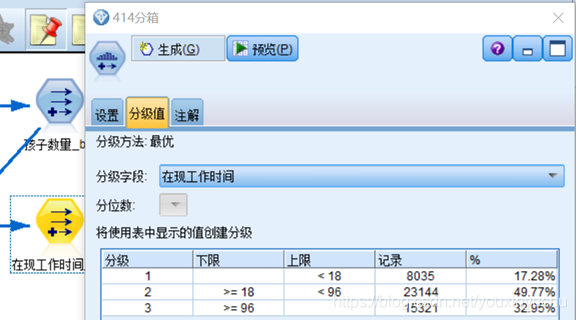
圖3-6 按現工作時間分箱
3.2.2對離散輸入變數分箱
在將連續變數分箱完之後,還有兩個離散變數需要分箱,分別是國籍和信用卡類別,需要將這兩個變數通過別的方式確定分箱的依據。
(一)按國籍屬性分箱,首先彙總國籍屬性下的不同國籍違約客戶數量,然後使用匯出節點計算違約比例,計算公式是違約比例=是否違約_Sum/Record_Count。第三步按照違約比例升序排序,最後使用重新分類節點根據違約比例的排序手動分箱,如圖3-7所示。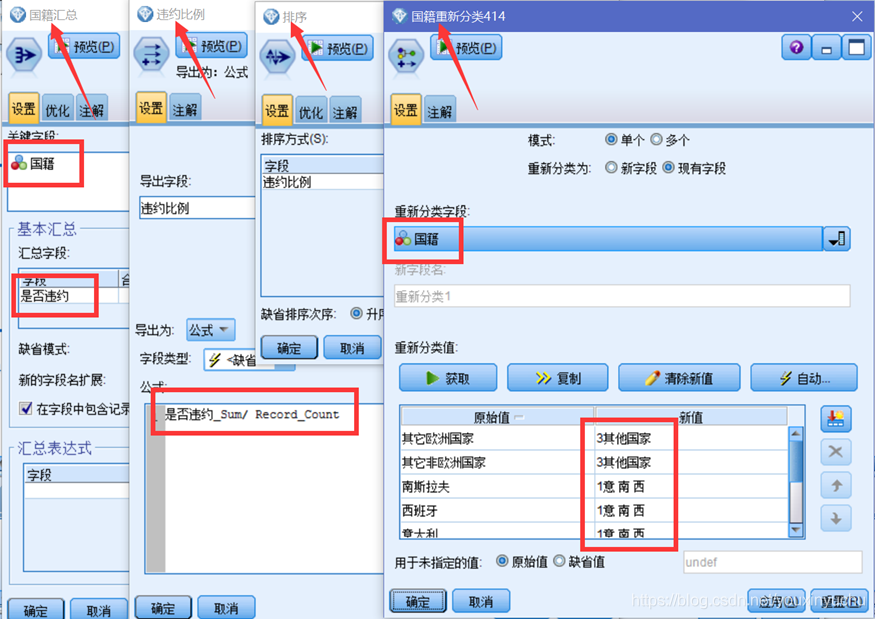
圖3-7 按國籍分箱
(二)按信用卡型別屬性分箱,首先彙總信用卡型別屬性下的不同信用卡型別違約客戶數量,然後使用匯出節點計算違約比例,計算公式是違約比例=是否違約_Sum/Record_Count。第三步按照違約比例升序排序,最後使用重新分類節點根據違約比例的排序手動分箱,如圖3-8所示。
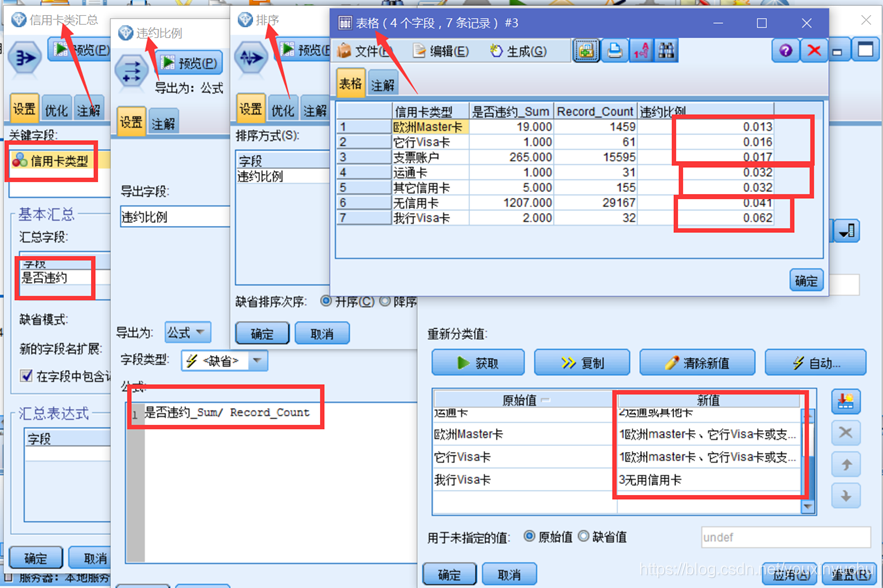
圖3-8 按信用卡型別分箱
到這裡以後,分箱操作就全部完成了,完成分箱操作以後便於後續的操作繼續進行,且簡化了後面的計算量。
3.3計算WOE值和IV值
WOE值意思是證據權重,是對原始自變數的一種編碼。WOE的計算公式是這樣的:
IV值意思是資訊價值或資訊量,可用來表示該變數是否對預測目標變數具有顯著意義。根據經驗,當IV<0.02時,該變數對預測目標變數幾乎無幫助;當0.02<=IV<0.1時,該變數對預測目標變數具有一定幫助;當0.1<=IV<0.3時,該變數對預測目標變數具有較大幫助;當IV>=0.3時,該變數對預測目標變數具有很大幫助。但是當IV>0.5時,該變數對目標變數有過渡預測的傾向,應仔細檢視是不是選用了和目標變數有很強因果關係的變數,這種變數是否可用於預測模型。
IV值的計算公式是這樣的:
3.3.1計算年齡欄位的WOE值和IV值
計算年齡屬性的WOE值,需要好客戶和壞客戶的數量,所以增加一個好客戶新變數。選擇匯出節點,如圖3-9所示。
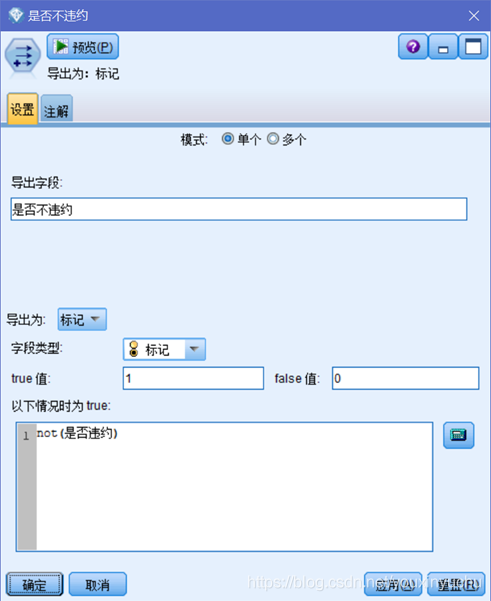
圖3-9 以是否違約為條件匯出
接下來計算好客戶與壞客戶的數量,這裡要做的操作是更改欄位名稱和去除無用資訊,選擇過濾器節點,過濾掉前面做過分箱的年齡、收入、孩子數量、在現住址時間、在現工作時間這五個欄位,因為已經生成了更簡潔的分箱欄位。而國籍和信用卡型別不過濾是因為它們是離散的資料,跟連續資料的分箱無關。將是否違約欄位重新命名為是否壞客戶,將是否不違約欄位重新命名為是否好客戶。如圖3-10所示。
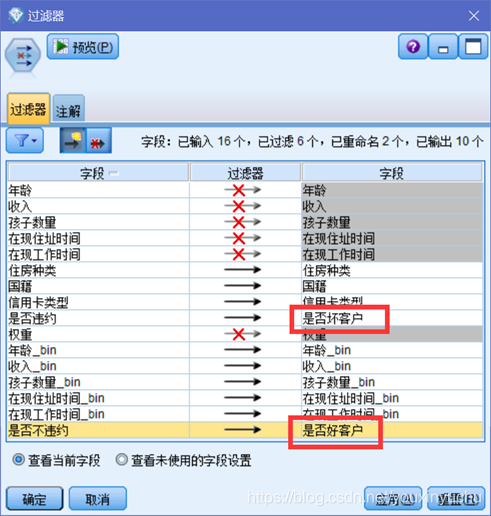
圖3-10 過濾無用資訊並重命名欄位
然後分別從這個節點出發,往後流出兩個彙總節點,一個彙總總的好客戶和壞客戶的數量,一個彙總各個年齡分箱段內的好客戶與壞客戶數量,如圖3-11所示。彙總以後再把兩個彙總結果橫向合併到一起,如圖3-12所示。

圖3-11 分別彙總好壞客戶數量
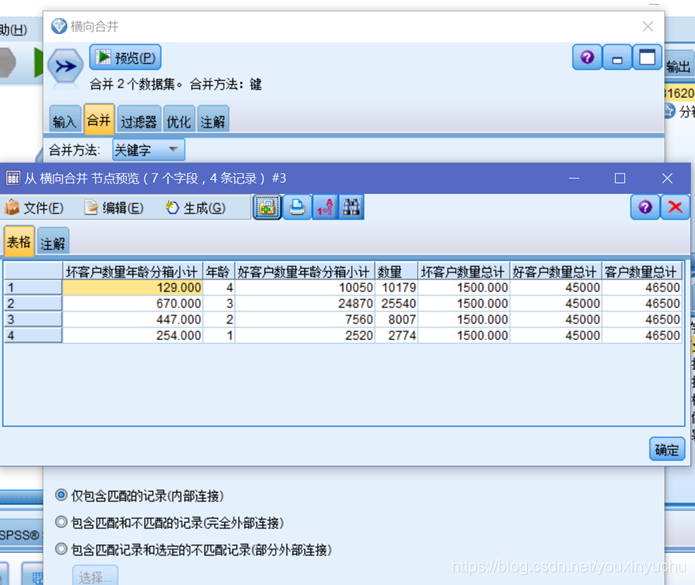
圖3-12 合併彙總的好壞客戶數量
得到上面的資料後,之後分別利用匯出節點計算數量佔比、好客戶佔比、壞客戶佔比以及壞客戶比例。再繼續用匯出節點,算出年齡的WOE值,如圖3-13所示。
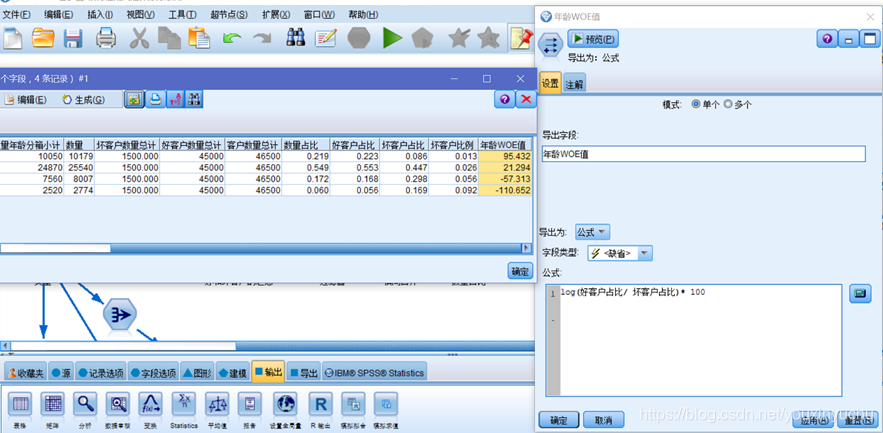
圖3-13 計算年齡的WOE值
計算完年齡WOE值之後,我們進行年齡的IV值計算。因為IV值是一個加總的值,所以先計算每一段年齡分箱的IV值再把它們彙總,如圖3-14所示。
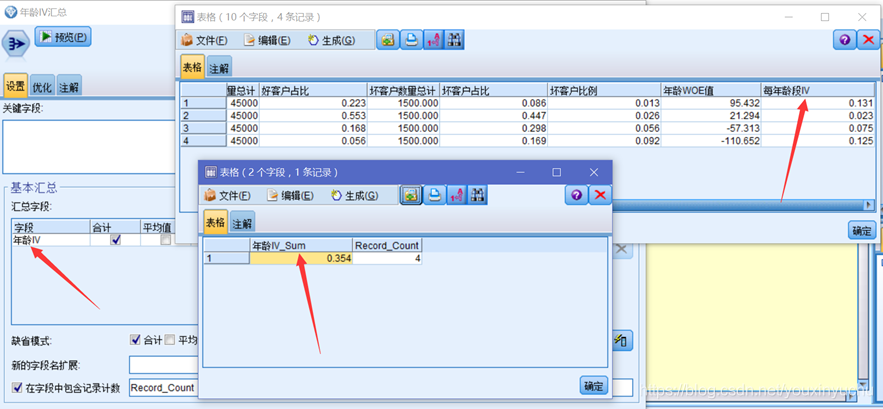
圖3-14 年齡IV值
計算完了年齡欄位的WOE值和IV值之後,將每段的WOE值匯出。
3.3.2計算剩餘欄位的WOE值和IV值
因為已經以年齡欄位為例詳細展示了怎麼計算一個欄位的WOE值和IV值,故剩餘的收入、孩子數量、在現住址時間、在現工作時間、國籍、信用卡型別幾個欄位的計算過程就只寫出關鍵步驟,不再每一步都貼圖展示。
(一)收入的WOE值和IV值
根據計算年齡WOE值和IV值的流,更改必要的欄位後即可得出收入的WOE值和IV值,如圖3-15所示。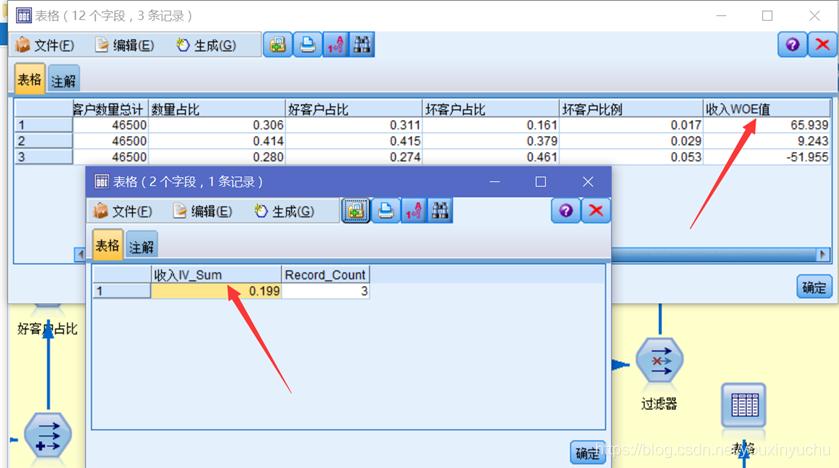
圖3-15收入的WOE值和IV值
(二)孩子數量的WOE值和IV值
根據計算年齡WOE值和IV值的流,更改必要的欄位後即可得出孩子數量的WOE值和IV值,如圖3-16所示。
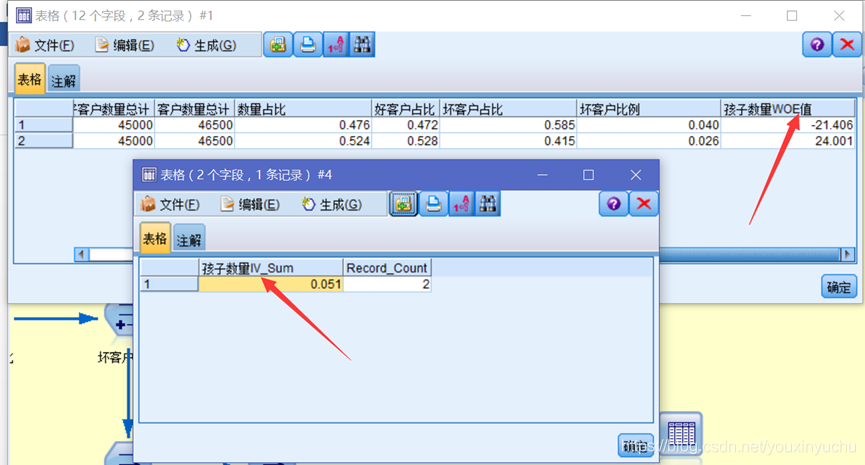
圖3-16孩子數量的WOE值和IV值
(三)在現住址時間的WOE值和IV值
根據計算年齡WOE值和IV值的流,更改必要的欄位後即可得出在現住址時間的WOE值和IV值,如圖3-17所示。

圖3-17在現住址時間的WOE值和IV值
(四)在現工作時間的WOE值和IV值
根據計算年齡WOE值和IV值的流,更改必要的欄位後即可得出在現工作時間的WOE值和IV值,如圖3-18所示。
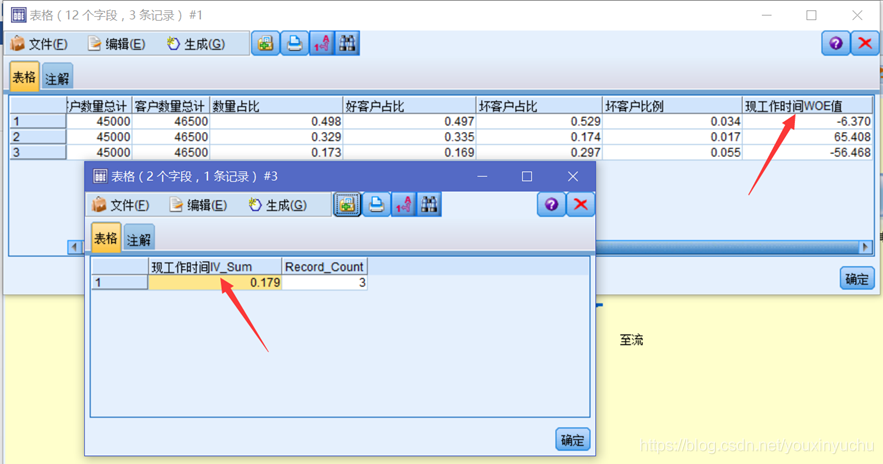
圖3-18在現工作時間的WOE值和IV值
(五)國籍的WOE值和IV值
根據計算年齡WOE值和IV值的流,更改必要的欄位後即可得出國籍的WOE值和IV值,如圖3-19所示。
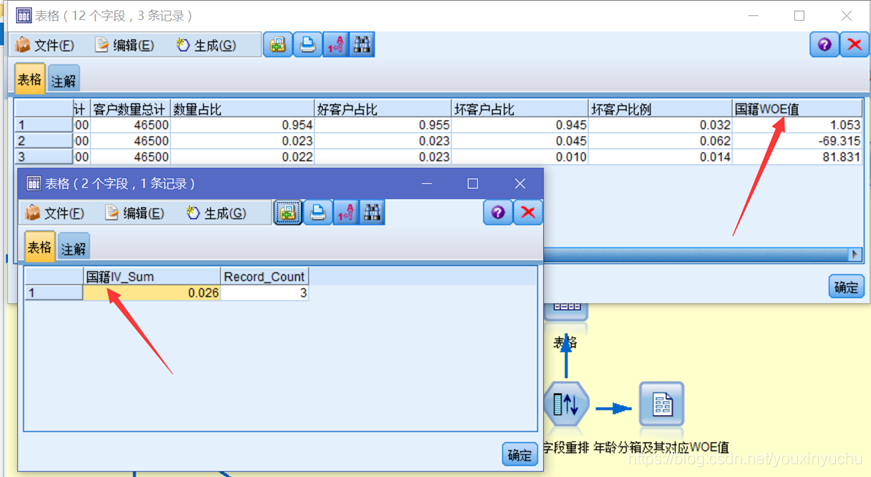
圖3-19國籍的WOE值和IV值
(六)信用卡型別的WOE值和IV值
根據計算年齡WOE值和IV值的流,更改必要的欄位後即可得出信用卡型別的WOE值和IV值,如圖3-20所示。
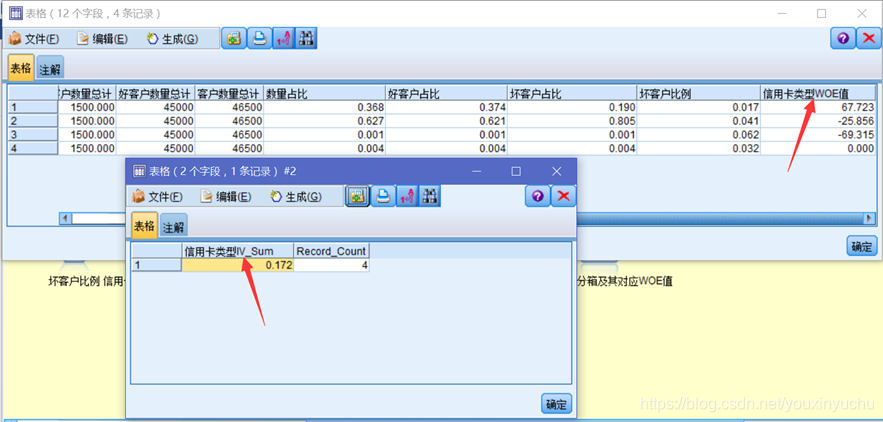
圖3-20信用卡型別的WOE值和IV值
3.4建立輸入變數與目標變數的Logistic迴歸模型
3.4.1匯出Logistic迴歸模型資料
邏輯迴歸是一種在預測目標變數為離散變數時廣泛採用的資料分析技術。
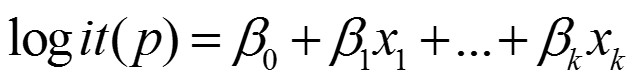
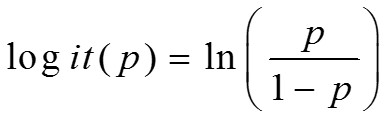 P是關注結果出現的概率,本案例中指的是壞客戶。
P是關注結果出現的概率,本案例中指的是壞客戶。
一般情況下,輸入變數主要為連續變數,當輸入變數為離散變數時,通常採用啞變數的方式將離散變數轉化為連續變數再進行處理。但是在構建信用評分卡時,所有變數都已經被轉換為了離散變數。作為替代,使用各個變數分箱對應的WOE值作為Logistic迴歸的輸入變數。
使用Logistic迴歸進行預測時,除了可以選擇讓全部變數進入模型之外,也可以讓模型選擇最終進入模型的變數:前進法、後退法、逐步法。
在前面做的資料的基礎上,建一個新的新的流,首先新增前文匯出的總WOE值資料,如圖3-21所示。
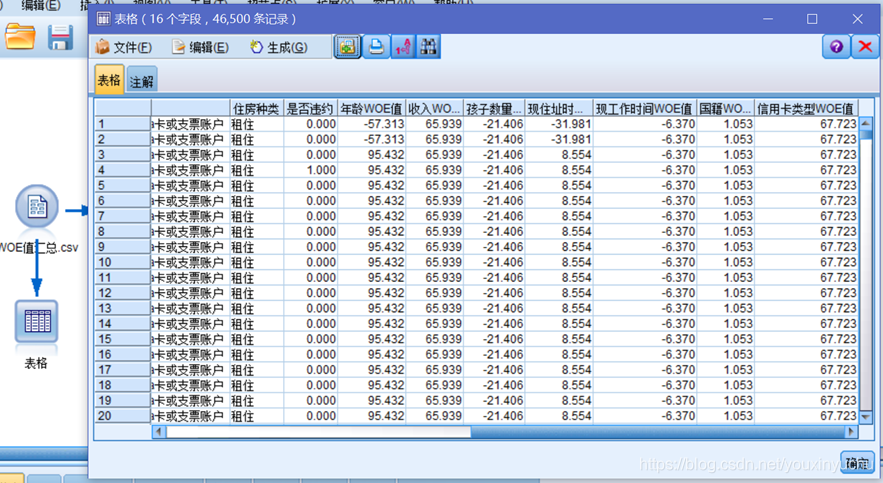
圖3-21 總WOE值資料
在讀入資料後,使用型別節點,調整各欄位的角色,各分箱值不再輸入,所以調整角色為無,WOE值是用來預測的自變數,故調整角色為輸入,是否違約是與粗目標,故調整角色為目標。特別的是在是否違約這一欄位,要改為標記型別的資料,因為是否違約這個欄位只有違約和不違約兩種結果,所示適用用來表示有兩個不同值的標記資料型別。如圖3-22所示。
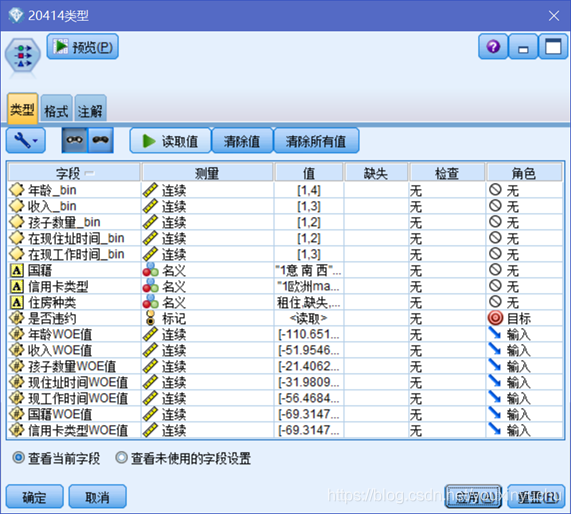
圖3-22 調整欄位的型別
然後使用Logistic模型建立迴歸模型。如圖3-23所示。可以看到現住址時間沒有了,這是因為它的預測能力很弱,自動的被省略了。
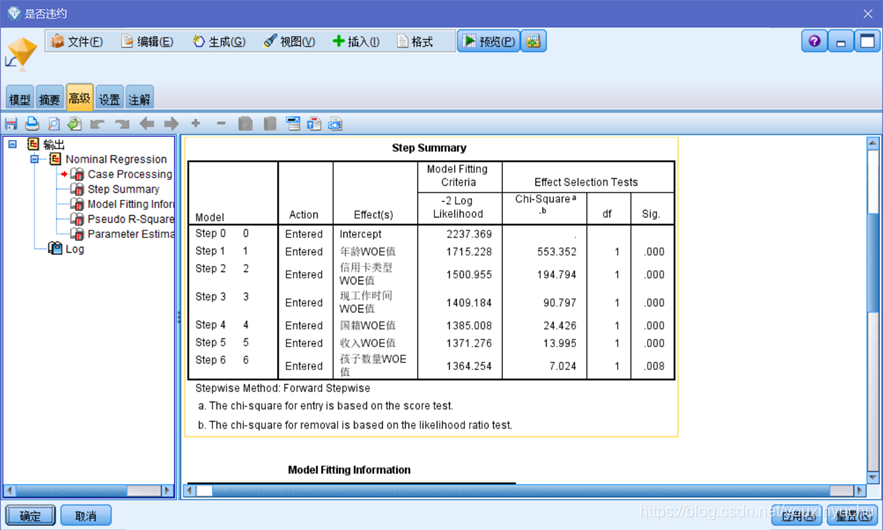
圖3-23 迴歸模型結果
將回歸模型的結果匯出成.txt格式的檔案,再將.txt檔案整理為結構化資料迴歸係數.csv檔案。
3.4.2結構化迴歸模型資料
使用變數檔案源節點匯入.txt檔案,輸出成表格可以觀察到有效資料從第8行開始,到第15行結束,每個係數裡有“*”和“+”符號。如圖3-24所示。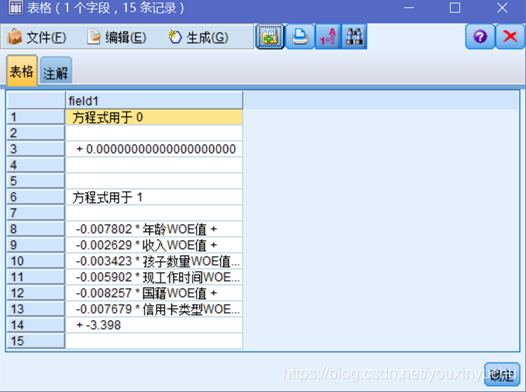
圖3-24 .txt檔案的資料
在讀入資料後首先將欄位名field1改為迴歸係數這幾個比較顯眼字方便後面做函式時候用,然後選擇只顯示8到14行的有效資料。如圖3-25所示。

圖3-25 更改欄位為迴歸係數並選擇有用資料
之後經過兩次條件選擇,可以輸出有用的資料,最後再過濾一次最開始的那個原始欄位,如圖3-26和3-27所示。

圖3-26 選擇有效資料
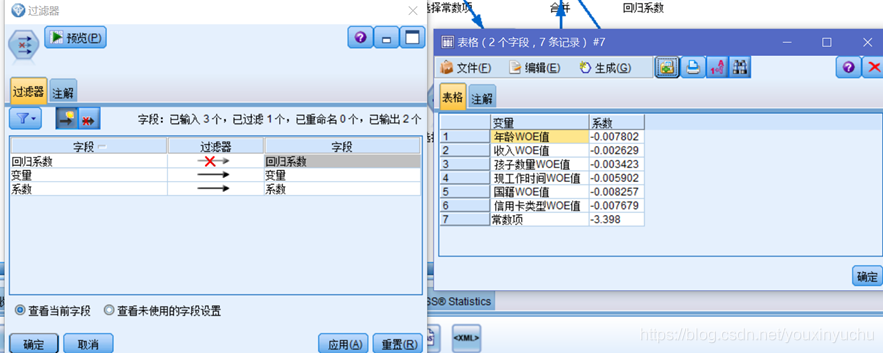
圖3-27 過濾原始欄位
之後從過濾節點出發流出兩個選擇節點,通過保留常數項和丟棄常數項操作,再在包括常數項的節點後面過濾掉變數欄位,因為另外一個丟棄常數項的節點裡面已經有這個欄位。將這兩個節點合併後,得到結構化的迴歸係數,並將迴歸係數匯出成.csv檔案,如圖3-28所示。

圖3-28 匯出結構化迴歸係數
3.5建立評分模型
3.5.1建立模型
本次試驗最終的目的是建立各個變數各個分箱的評分值。將Logistic迴歸係數轉化為信用評分的形式是一個量表編制的過程。應該有這樣的限制:將評分控制在一定範圍內,如0~1000分之間;在特定分數時,好客戶和壞客戶具有一定的比例關係(優比odds=好客戶佔比/壞客戶佔比=(1-p)/p);評分值增加應該能夠反映好客戶和壞客戶比例關係的變化。
先將前面匯出的資料合併到一起並和迴歸係數合併到一起,迴歸係數可以用填充節點處理一下以消除可能存在的文字前後的空格,就可以利用變數關鍵字合併了。如圖3-29所示。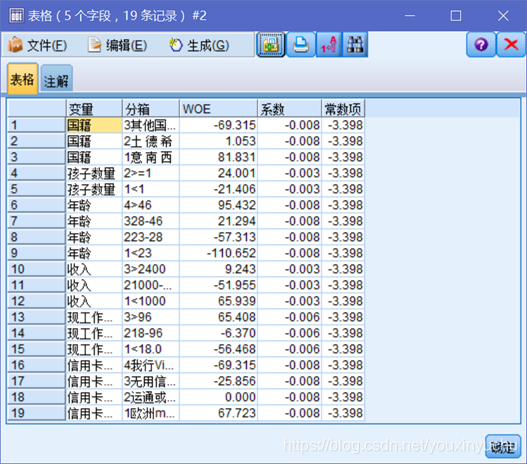
圖3-29 合併WOE值和迴歸係數
使用匯出節點,用公式計算各分箱的評分,如圖3-30所示。
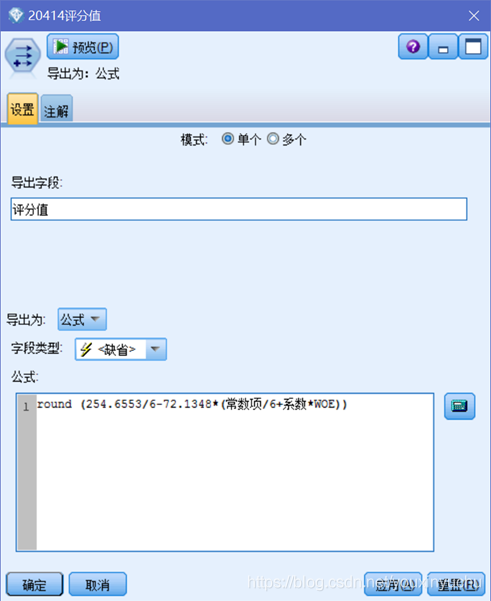
圖3-30 用公式計算評分
用過濾節點過濾掉不需要的節點後,輸出各變數各分箱評分.csv檔案,這一小節完成,如圖3-31所示。
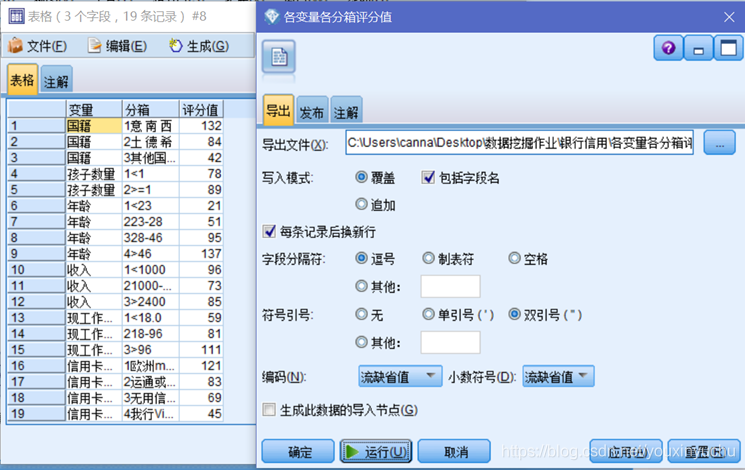
圖3-31 輸出各變數各分箱評分
3.5.2驗證模型
有些時候,在目標變數中我們關注的取值比例很少的情況下,模型準確率、模型命中率、模型覆蓋率等評價指標將會變得沒有意義。就本案例來說,使用逐步法建立Logistic迴歸模型,使用分析節點選中重合矩陣可以看到如圖3-32的結果。從圖中可以看到準確率達到了96.77%,可是進一步觀察重合矩陣就會發現,這個模型將所有的客戶都預測為好客戶,但我想要的是哪些客戶是壞客戶,即違約的客戶,所以從這個角度來說這個模型的意義並不是很大。但是,這個模型的增益圖和提升圖還是有意義的,因為它們是根據客戶為壞的可能性進行排序得到的圖形,如圖3-33所示。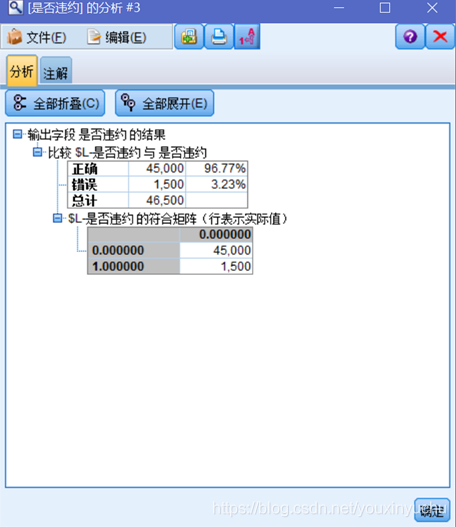
圖3-32 分析節點選中重合矩陣
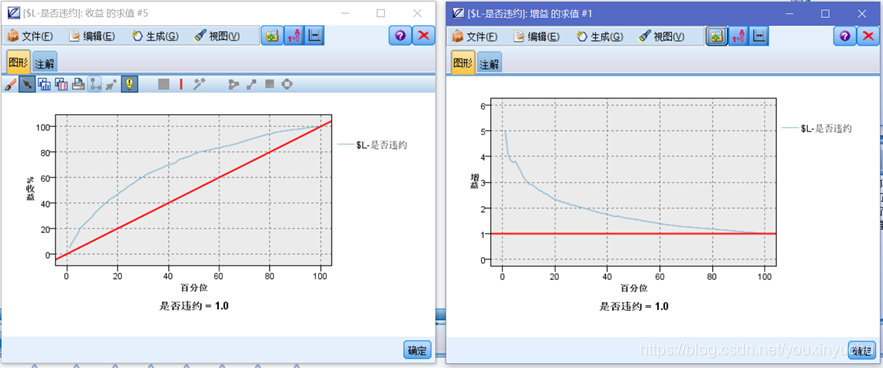
圖3-33 增益圖和提升圖
除了上面的兩個增益圖和提升圖,這次還會使用K-S指標來驗證模型的優劣。適應於目標變數為標誌型的預測模型。在模型有效的情況下,壞客戶累計佔比曲線應該在好客戶累計佔比曲線之上,且這兩條曲線距離越遠,模型效果越好,模型區分好客戶和壞客戶的能力越強。一般認為區分度在30%以上的模型是可以接受的。
在SPSSmodeler中,沒有直接作出K-S指標及圖形的節點,但是可以通過節點的組合生成K-S指標和相關圖形。下面就做一個K-S指標的計算。在匯入前面生成的建模資料後,先用匯出節點的@INDEX生成客戶編號,如圖3-34所示。
圖3-34 生成客戶編號
在這之後,用過濾節點過濾掉無用欄位。然後從這個過濾節點流出6個匯出節點,生成新的欄位,名字與各變數評分表中的名字一致,這是因為後面要與評分表進行合併。如圖3-35所示。
圖3-35 生成新變數
將6個新生成的資料表追加合併,得到279000條記錄。如圖3-36所示。
圖3-36 追加合併
經過欄位重排,排序後與前面生成的評分表合併,得到評分資料。如圖3-37所示。
圖3-37 評分表資料
再經過欄位重排和排序後,按客戶編號彙總評分值。如圖3-38所示。
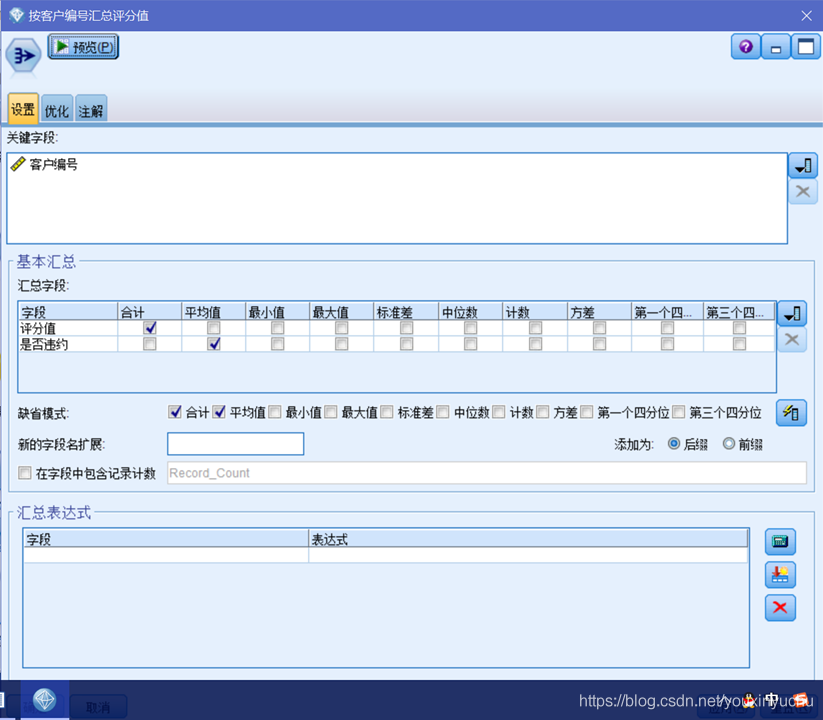
圖3-38 按客戶編號彙總評分
之後按照信用評分排序,排序之後彙總好客戶和壞客戶數量,再在過濾總數之後與排序節點合併,得到好壞客戶數量及評分值的表。
圖3-39 好壞客戶數量及評分
用匯出節點分別計算好客戶累計佔比和壞客戶累計佔比,如圖3-40所示。
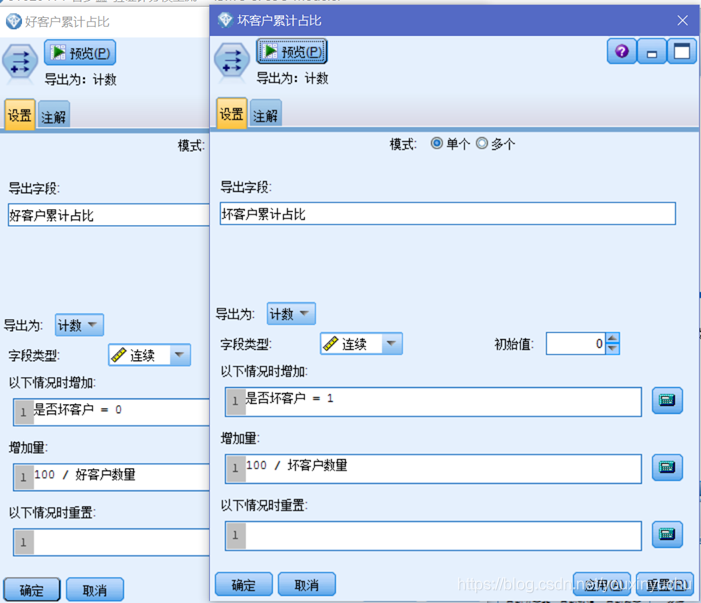
圖3-40 好壞客戶累計佔比
有了好壞客戶的累計佔比,就可以計算K-S圖,如圖3-41所示。
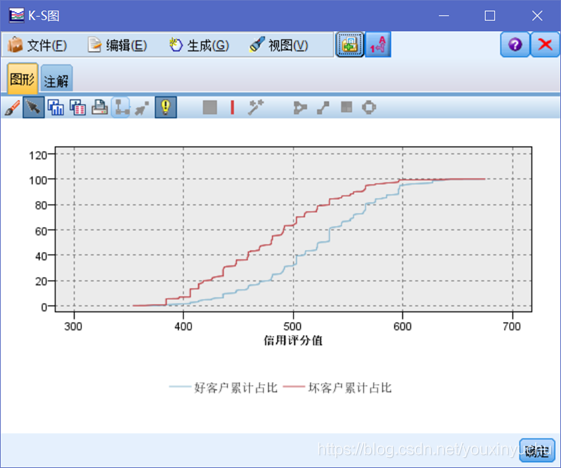
圖3-41 K-S圖
也可以用匯出節點得到K-S值,如圖3-42所示。
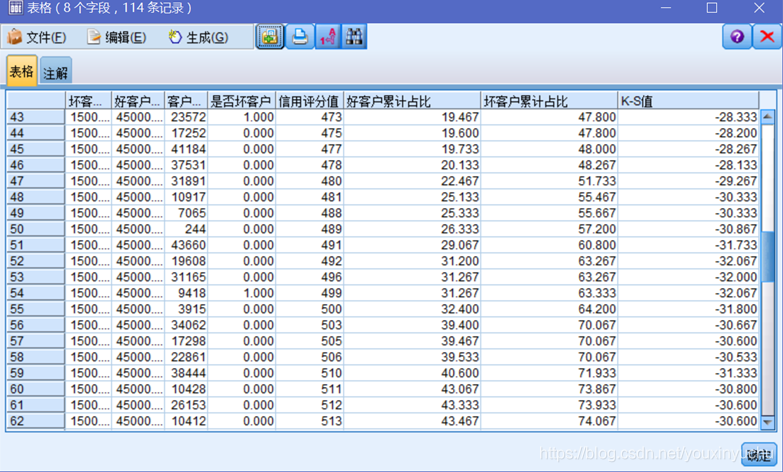
圖3-42 K-S值
到這一步為止,關於本次試驗的實踐操作部分已經完成。
3.6完整資料流
第一個完整的流,是計算WOE值和IV值的流,如圖3-43所示。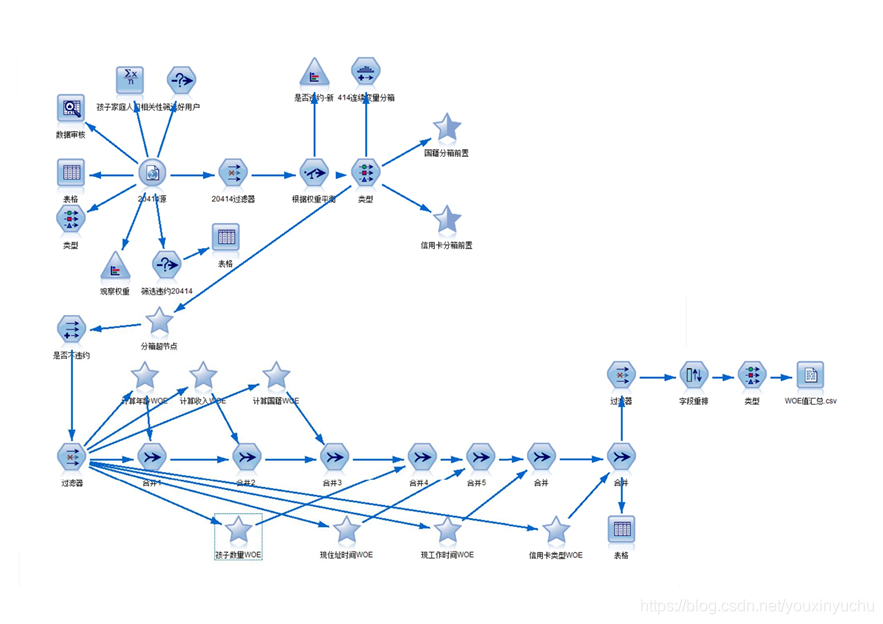
圖3-43 計算WOE值和IV值的流
第二個流,是迴歸模型流,如圖3-44所示。
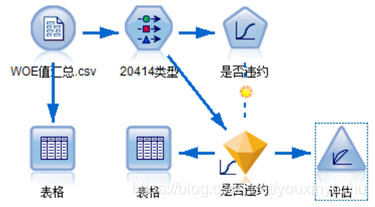
圖3-44 迴歸模型流
第三個流是結構化迴歸係數的流,如圖3-45所示。
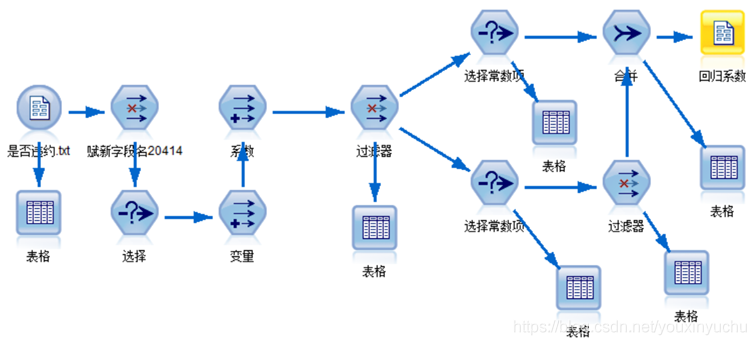
圖3-45 結構化迴歸係數流
第四個流是建立評分模型的流,如圖3-46所示。
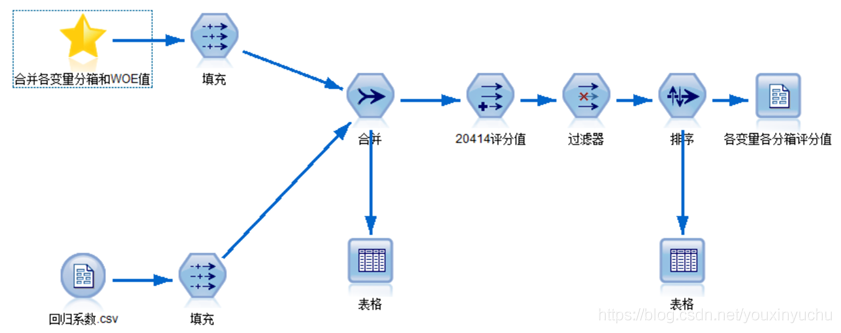
圖3-46建立評分模型流
第五個流是驗證評分模型的流,如圖3-47所示。
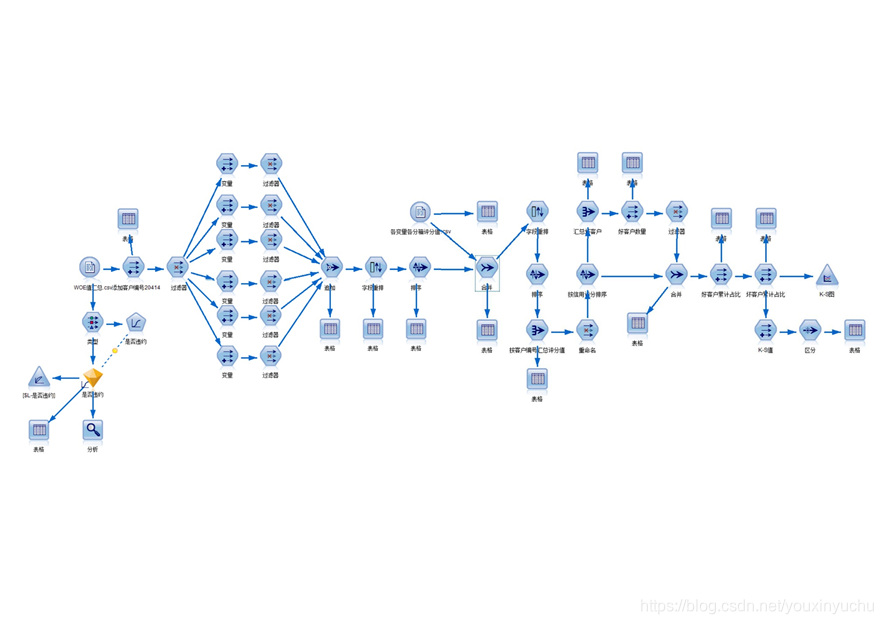
圖3-47 驗證評分模型流
第四章 結論及建議
4.1根據結果對銀行的建議
前面的分析已經隨著實驗步驟寫過了,這裡只分析一下最後的結果。從最後的K-S裡面可以看出來,信用分大於492分的客戶就有很大可能是屬於好客戶了,所以對於這一類客戶的貸款申請可以同意,而對於信用評分低於492分的客戶,就本實驗所用的資料來推測很可能就是壞客戶,因此就不要同意向他們發放貸款。
當然,本次實驗所用的資料並不是特別的豐富,在實際操作中,也可以再收集客戶的婚姻狀況、固定資產、車子房子等等資訊,講這些資訊一併考慮後再決定是不是發放貸款,畢竟貸款是一項長期的業務。