
中文分詞綜述
現有分詞介紹:
自然語言處理是一個資訊時代最重要的技術之一,簡單來講,就是讓計算機能夠理解人類語言的一種技術。在其中,分詞技術是一種比較基礎的模組。對於英文等拉丁語系而言,由於詞之間有空格作為詞邊際表示,詞語一般情況下都能簡單且準確的提取出來。而中文等文字,除了標點符號以外,字之間緊密相連,沒有明顯的詞邊界,因此很難將詞提取出來。分詞的意義非常大,在中文中,單字作為最基本的語義單位,雖然也有自己的意義,但表意能力較差,意義較分散,而詞的表意能力更強,能更加準確的描述一個事物,因此在自然語言處理中,通常情況下詞(包括單字成詞)是最基本的處理單位。在具體的應用上,比如在常用的搜尋引擎中,term如果是詞粒度的話,不僅能夠減少每個term的倒排列表長度,提升系統性能,並且召回的結果相關性高更準確。比如搜尋query”的確”,如果是單字切分的話,則有可能召回”你講的確實在理”這樣的doc。分詞方法大致分為兩種:基於詞典的機械切分,基於統計模型的序列標註切分兩種方式。
基於詞典的方法:
基於詞典的方法本質上就是字串匹配的方法,將一串文字中的文字片段和已有的詞典進行匹配,如果匹配到,則此文字片段就作為一個分詞結果。但是基於詞典的機械切分會遇到多種問題,最為常見的包括歧義切分問題和未登入詞問題。
歧義切分:
歧義切分指的是通過詞典匹配給出的切詞結果和原來語句所要表達的意思不相符或差別較大,在機械切分中比較常見,比如下面的例子:“結婚的和尚未結婚的人”,通過機械切分的方式,會有兩種切分結果:1,“結婚/的/和/尚未/結婚/的/人”;2,“結婚/的/和尚/未/結婚/的/人”。可以明顯看出,第二種切分是有歧義的,單純的機械切分很難避免這樣的問題。
未登入詞識別:
未登入詞識別也稱作新詞發現,指的是詞沒有在詞典中出現,比如一些新的網路詞彙,如“網紅”,“走你”;一些未登入的人名,地名;一些外語音譯過來的詞等等。基於詞典的方式較難解決未登入詞的問題,簡單的case可以通過加詞典解決,但是隨著字典的增大,可能會引入新的bad case,並且系統的運算複雜度也會增加。
基於詞典的機械分詞改進方法:
為了解決歧義切分的問題,在中文分詞上有很多優化的方法,常見的包括正向最大匹配,逆向最大匹配,最少分詞結果,全切分後選擇路徑等多種演算法。
最大匹配方法:
正向最大匹配指的是從左到右對一個字串進行匹配,所匹配的詞越長越好,比如“中國科學院計算研究所”,按照詞典中最長匹配原則的切分結果是:“中國科學院/計算研究所”,而不是“中國/科學院/計算/研究所”。但是正向最大匹配也會存在一些bad case,常見的例子如:“他從東經過我家”,使用正向最大匹配會得到錯誤的結果:“他/從/東經/過/我/家”。
逆向最大匹配的順序是從右向左倒著匹配,如果能匹配到更長的詞,則優先選擇,上面的例子“他從東經過我家”逆向最大匹配能夠得到正確的結果“他/從/東/經過/我/家”。但是逆向最大匹配同樣存在badcase:“他們昨日本應該回來”,逆向匹配會得到錯誤的結果“他們/昨/日本/應該/回來”。
針對正向逆向匹配的問題,將雙向切分的結果進行比較,選擇切分詞語數量最少的結果。但是最少切分結果同樣有bad case,比如“他將來上海”,正確的切分結果是“他/將/來/上海”,有4個詞,而最少切分結果“他/將來/上海”只有3個詞。
全切分路徑選擇方法:
全切分方法就是將所有可能的切分組合全部列出來,並從中選擇最佳的一條切分路徑。關於路徑的選擇方式,一般有n最短路徑方法,基於詞的n元語法模型方法等。
n最短路徑方法的基本思想就是將所有的切分結果組成有向無環圖,每個切詞結果作為一個節點,詞之間的邊賦予一個權重,最終找到權重和最小的一條路徑作為分詞結果。
基於詞的n元語法模型可以看作是n最短路徑方法的一種優化,不同的是,根據n元語法模型,路徑構成時會考慮詞的上下文關係,根據語料庫的統計結果,找出構成句子最大模型概率。一般情況下,使用unigram和bigram的n元語法模型的情況較多。
基於序列標註的分詞方法:
針對基於詞典的機械切分所面對的問題,尤其是未登入詞識別,使用基於統計模型的分詞方式能夠取得更好的效果。基於統計模型的分詞方法,簡單來講就是一個序列標註問題。
在一段文字中,我們可以將每個字按照他們在詞中的位置進行標註,常用的標記有以下四個label:B,Begin,表示這個字是一個詞的首字;M,Middle,表示這是一個詞中間的字;E,End,表示這是一個詞的尾字;S,Single,表示這是單字成詞。分詞的過程就是將一段字元輸入模型,然後得到相應的標記序列,再根據標記序列進行分詞。舉例來說:“達觀資料位是企業大資料服務商”,經過模型後得到的理想標註序列是:“BMMESBEBMEBME”,最終還原的分詞結果是“達觀資料/是/企業/大資料/服務商”。
在NLP領域中,解決序列標註問題的常見模型主要有HMM和CRF。
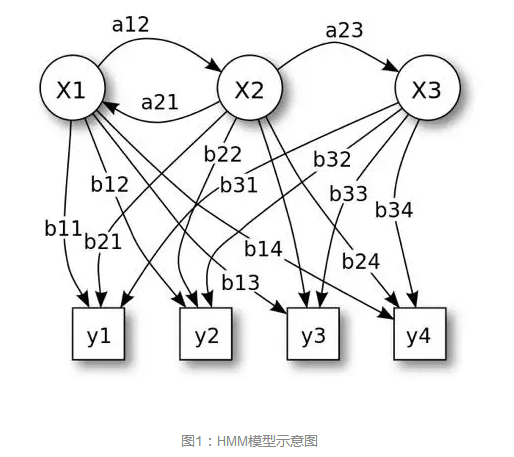
HMM
HMM(HiddenMarkov Model)隱馬爾科夫模型應用非常廣泛,基本的思想就是根據觀測值序列找到真正的隱藏狀態值序列。在中文分詞中,一段文字的每個字元可以看作是一個觀測值,而這個字元的詞位置label(BEMS)可以看作是隱藏的狀態。使用HMM的分詞,通過對切分語料庫進行統計,可以得到模型中5大要要素:起始概率矩陣,轉移概率矩陣,發射概率矩陣,觀察值集合,狀態值集合。在概率矩陣中,起始概率矩陣表示序列第一個狀態值的概率,在中文分詞中,理論上M和E的概率為0。轉移概率表示狀態間的概率,比如B->M的概率,E->S的概率等。而發射概率是一個條件概率,表示當前這個狀態下,出現某個字的概率,比如p(人|B)表示在狀態為B的情況下人字的概率。
有了三個矩陣和兩個集合後,HMM問題最終轉化成求解隱藏狀態序列最大值的問題,求解這個問題最長使用的是Viterbi演算法,這是一種動態規劃演算法,具體的演算法可以參考維基百科詞條,在此不詳細展開。(https://en.wikipedia.org/wiki/Viterbi_algorithm)
CRF
CRF(Conditionalrandom field,條件隨機場)是用來標註和劃分結構資料的概率化結構模型,通常使用在模式識別和機器學習中,在自然語言處理和影象處理等領域中得到廣泛應用。和HMM類似,當對於給定的輸入觀測序列X和輸出序列Y,CRF通過定義條件概率P(Y|X),而不是聯合概率分佈P(X,Y)來描述模型。CRF演算法的具體演算法可以參考維基百科詞條。(https://en.wikipedia.org/wiki/Conditional_random_field)
在實際應用中有很多工具包可以使用,比如CRF++,CRFsuite,SGD,Wapiti 等,其中CRF++的準確度較高。在分詞中使用CRF++時,主要的工作是特徵模板的配置。CRF++支援unigram,bigram兩種特徵,分別以U和B開頭。舉例來講U00:%x[-2,0]表示第一個特徵,特徵取值是當前字的前方第二個字,U01:%x[-1,0]表示第二個特徵,特徵取值當前字前一個字,U02:%x[0,0]表示第三個特徵,取當前字,以此類推。特徵模板可以支援多種特徵,CRF++會根據特徵模板提取特徵函式,用於模型的建立和使用。特徵模板的設計對分詞效果及訓練時間影響較大,需要分析嘗試找到適用的特徵模板。
深度學習介紹
隨著AlphaGo的大顯神威,Deep Learning(深度學習)的熱度進一步提高。深度學習來源於傳統的神經網路模型。傳統的神經網路一般由輸入層,隱藏層,輸出層組成,其中隱藏層的數目按需確定。深度學習可以簡單的理解為多層神經網路,但是深度學習的卻不僅僅是神經網路。深度模型將每一層的輸出作為下一層的輸入特徵,通過將底層的簡單特徵組合成為高層的更抽象的特徵來進行學習。在訓練過程中,通常採用貪婪演算法,一層層的訓練,比如在訓練第k層時,固定訓練好的前k-1層的引數進行訓練,訓練好第k層之後的以此類推進行一層層訓練。
深度學習在很多領域都有所應用,在影象和語音識別領域中已經取得巨大的成功。從2012年開始,LSVRC(LargeScale Visual Recognition Challenge)比賽中,基於Deep Learningd計算框架一直處於領先。2015年LSVRC(http://www.image-net.org/challenges/LSVRC/2015/results)的比賽中,微軟亞洲研究院(MSRA)在影象檢測(Objectdetection),影象分類定位(Object Classification+localization)上奪冠,他們使用的神經網路深達152層。
在NLP中的應用
在自然語言處理上,深度學習在機器翻譯、自動問答、文字分類、情感分析、資訊抽取、序列標註、語法解析等領域都有廣泛的應用。2013年末google釋出的word2vec工具,可以看做是深度學習在NLP領域的一個重要應用,雖然word2vec只有三層神經網路,但是已經取得非常好的效果。通過word2vec,可以將一個詞表示為詞向量,將文字數字化,更好的讓計算機理解。使word2vec模型,我們可以方便的找到同義詞或聯絡緊密的詞,或者意義相反的詞等。
P.S:word2vec的安裝:
word2vec
要解決問題: 在神經網路中學習將word對映成連續(高維)向量,這樣通過訓練,就可以把對文字內容的處理簡化為K維向量空間中向量運算,而向量空間上的相似度可以用來表示文字語義上的相似度。
一般來說, word2vec輸出的詞向量可以被用來做很多 NLP 相關的工作,比如聚類、找同義詞、詞性分析等等。另外還有其向量的加法組合演算法。官網上的例子是 :
vector(‘Paris’) - vector(‘France’) +
vector(‘Italy’) ≈vector(‘Rome’), vector(‘king’) - vector(‘man’) + vector(‘woman’) ≈
vector(‘queen’)
但其實word2vec也只是少量的例子完美符合這種加減法操作,並不是所有的 case 都滿足。
快速入門
1、從http://word2vec.googlecode.com/svn/trunk/ 下載所有相關程式碼:
一種方式是使用svn Checkout,可加代理進行check。
另一種就是export to github,然後再github上下載,我選擇第二種方式下載。
2、執行make編譯word2vec工具:(如果其中makefile檔案後有.txt字尾,將其去掉)在當前目錄下執行make進行編譯,生成可執行檔案(編譯過程中報出很出Warning,暫且不管);
3、執行示例指令碼:./demo-word.sh 看一下./demo-word.sh的內容,大致執行了3步操作
從http://mattmahoney.net/dc/text8.zip 下載了一個檔案text8 ( 一個解壓後不到100M的txt檔案,可自己下載並解壓放到同級目錄下);
使用檔案text8進行訓練,訓練過程比較長;
執行word2vec生成詞向量到 vectors.bin檔案中,(速度比較快,幾分鐘的事情)
在demo-word.sh中有如下命令
time ./word2vec -train text8 -output vectors.bin -cbow 1 -size 200 -window 8 -negative 0 -hs 1 -sample 1e-4 -threads 20 -binary 1 -iter 15
time ./word2vec -train text8 -output vectors.bin -cbow 1 -size 200 -window 8 -negative 0 -hs 1 -sample 1e-4 -threads 20 -binary 1 -iter 15
以上命令
-train text8 表示的是輸入檔案是text8
-output vectors.bin 輸出檔案是vectors.bin
-cbow 1 表示使用cbow模型,預設為Skip-Gram模型
-size 200 每個單詞的向量維度是200
-window 8 訓練的視窗大小為5就是考慮一個詞前八個和後八個詞語(實際程式碼中還有一個隨機選視窗的過程,視窗大小小於等於8)
-negative 0 -hs 1不使用NEG方法,使用HS方法。-
sampe指的是取樣的閾值,如果一個詞語在訓練樣本中出現的頻率越大,那麼就越會被取樣。
-binary為1指的是結果二進位制儲存,為0是普通儲存(普通儲存的時候是可以開啟看到詞語和對應的向量的)
-iter 15 迭代次數
demo-word.sh中最後一行命令是./distance vectors.bin
該命令是計算距離的命令,可計算與每個詞最接近的詞了:
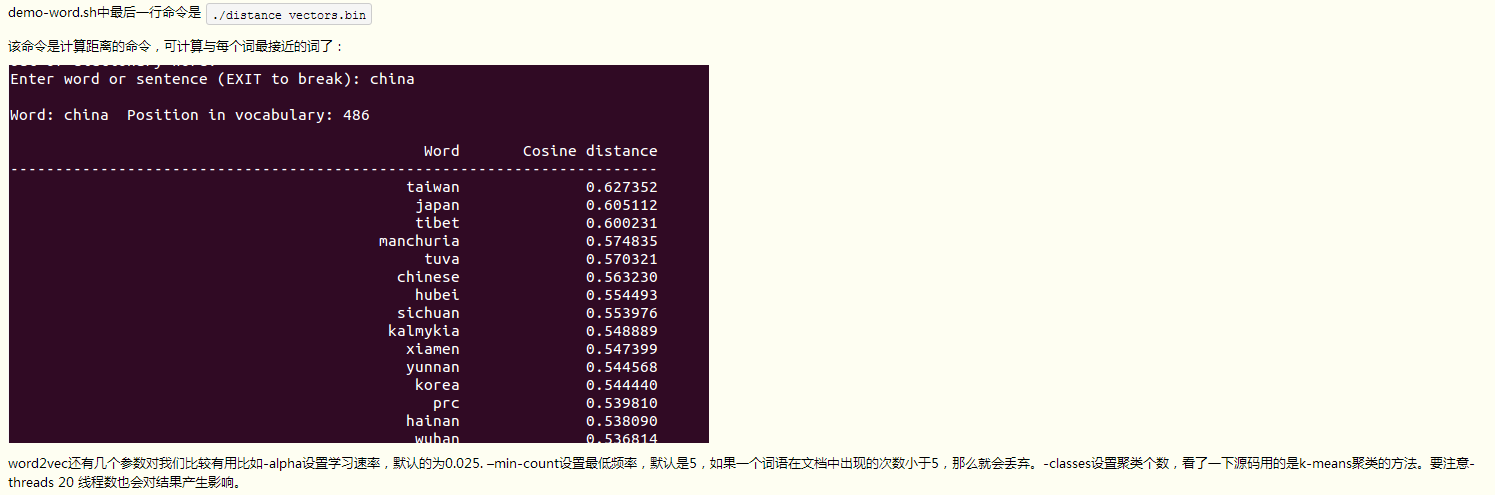
word2vec還有幾個引數對我們比較有用比如-alpha設定學習速率,預設的為0.025. –min-count設定最低頻率,預設是5,如果一個詞語在文件中出現的次數小於5,那麼就會丟棄。-classes設定聚類個數,看了一下原始碼用的是k-means聚類的方法。要注意-threads 20 執行緒數也會對結果產生影響。
架構:skip-gram(慢、對罕見字有利)vs CBOW(快)
訓練演算法:分層softmax(對罕見字有利)vs 負取樣(對常見詞和低緯向量有利)
欠取樣頻繁詞:可以提高結果的準確性和速度(適用範圍1e-3到1e-5)
文字(window)大小:skip-gram通常在10附近,CBOW通常在5附近
4、執行命令 ./demo-phrases.sh:檢視該指令碼內容,主要執行以下步驟:
從http://www.statmt.org/wmt14/training-monolingual-news-crawl/news.2012.en.shuffled.gz 下載了一個檔案news.2012.en.shuffled.gz ( 一個解壓到1.7G的txt檔案,可自己下載並解壓放到同級目錄下);
將檔案中的內容拆分成 phrases,然後執行./word2vec生成短語向量到 vectors-phrase.bin檔案中(資料量大,速度慢,將近半個小時),如下:
最後一行命令./distance vectors-phrase.bin,一個計算word相似度的demo中去,結果如下:
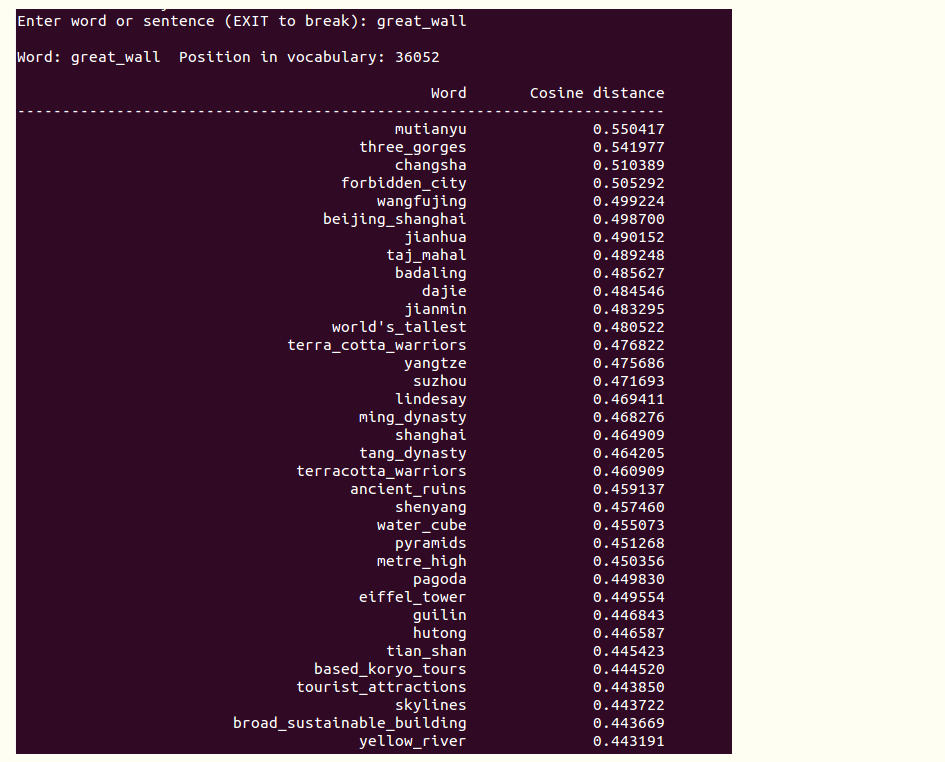
結果好壞跟訓練詞庫有關。
番外:
如果需要中文語料庫,推薦使用維基的或者搜狗(http://www.sogou.com/labs/dl/ca.html),中文分詞可使用結巴分詞,我覺得很好用。然後進行訓練,因為英文不用分詞,所以上述過程不涉及分詞。
本文主要偏應用,講解一個例子,便於對word2vec有一個初步瞭解,後續再更原理。
{
http://www.sogou.com/labs/resource/ca.php針對下載的搜狗的語料庫,如何將dat轉換txt

然後用這個提取出來就好了
}