
Flink 專題1 : 搭建Flink 及Flink 簡介
目錄
Flink 專題1 : 搭建Flink 及Flink 簡介
圖片來源於網路
Flink 簡介
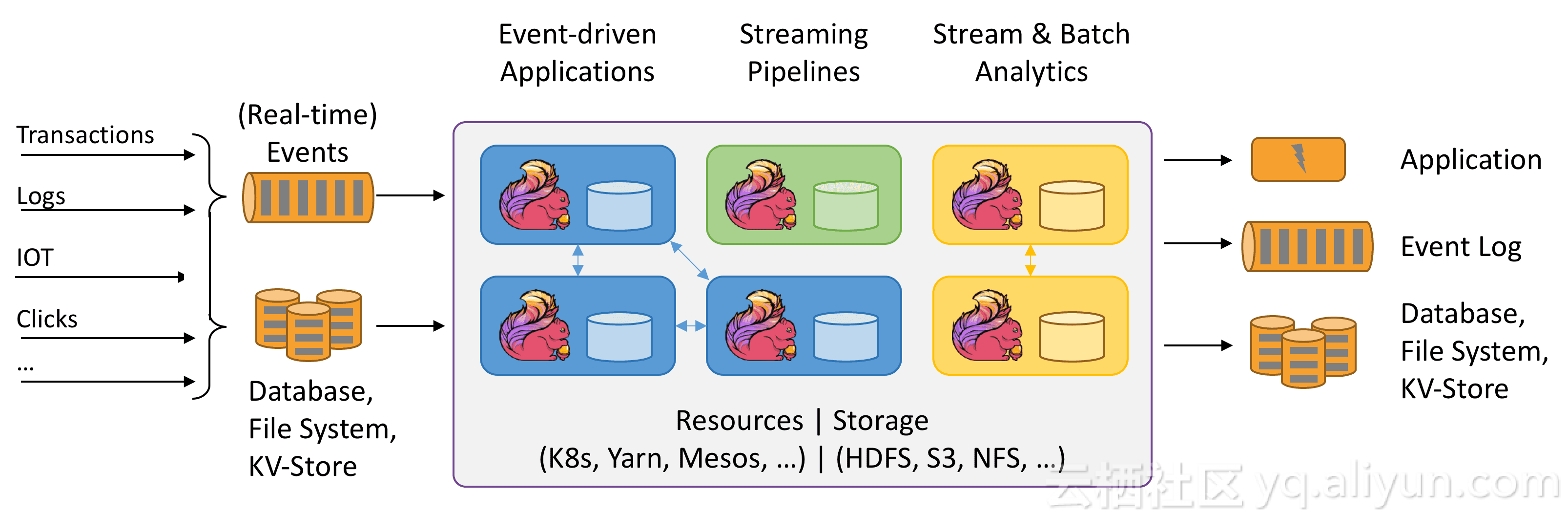
Apache Flink® - 基於資料流的有狀態計算
Flink 的優勢:
- 流場景使用案例
資料驅動的應用
批流資料分析
資料通道和ETL - 正確性保證
Exactly-once狀態一致性保證
事件時間處理
複雜的late date處理 更多 - API分層體系
統一SQL支援Stream和Batch資料處理
DataStream API & DataSet API
ProcessFunction (Time & State) - Operational Focus
部署靈活
高可用配置
Savepoints - 適用於各種應用場景Scales to any use case#
架構可擴充套件
超大state支援
增量checkpointing - 高效能
低延時
高吞吐
記憶體計算
Flink 安裝
安裝地址:
flink : http://mirror.bit.edu.cn/apache/flink/flink-1.6.2/flink-1.6.2-bin-hadoop27-scala_2.11.tgz
hadoop : https://archive.apache.org/dist/hadoop/common/hadoop-2.7.6/hadoop-2.7.6.tar.gz
hadoop 安裝略過
flink 安裝步驟
flink 安裝包含單點模式,叢集模式,flink on yarn 模式 ,flink on k8s 等模式 ,flink 通過是基於jvm 進行操作, 通過程式碼可以在單機情況下模擬 叢集模式資料 ,以此可以實現本地化的degug 操作。
下面介紹一下叢集模式部署:
flink 叢集模式 結構 :
Flink 叢集模式 包含 JobManager /TaskManager
配置檔案設定:
flink-conf.yaml
jobmanager.rpc.address: test-hadoop01
jobmanager.rpc.port: 6123
// 設定jobManager 的記憶體大小
jobmanager.heap.size: 2048m
// 設定每個taskManager 的記憶體大小
taskmanager.heap.size: 3072m
// 設定每個TaskManager 所佔槽位 (最好和當前 機器的 可用核數相同(注意要排除預留給自己自身的核數))
taskmanager.numberOfTaskSlots: 8
parallelism.default: 3 // 預設並行度
// hdfs 地址
fs.default-scheme: hdfs://test-hadoop02:9000/
fs.hdfs.hadoopconf: hdfs:///flink/data/
state.checkpoints.dir: hdfs:///checkpoints/
//設定checkpoint 保留版本數量(選擇)
state.checkpoints.num-retained: 20
// 設定savepoint 地址 (選擇 )
state.savepoints.dir: hdfs://namenode01.td.com/flink-1.5.3/flink-savepoints
//該引數控制了 Flink 是否該重新分配失敗的 TaskManager 容器。預設值:true (選擇 )
yarn.reallocate-failed:true
//ApplicationMaster 能接受最多的失敗 container 數,直到 YARN 會話失敗。預設:初始請求的 TaskManager 數(-n) (選擇 )
yarn.maximum-failed-containers:10
//ApplicationMaster(以及 TaskManager containers)重試次數。此引數預設值為1,如果 Application master 失敗,那麼整個 YARN session 會失敗。如果想增大 ApplicationMaster 重啟次數,可以把該引數的值調大一些。 (選擇 )
yarn.application-attempts:5 slaves
將叢集的所有節點均寫入該檔案中
test-hadoop01
test-hadoop02
test-hadoop03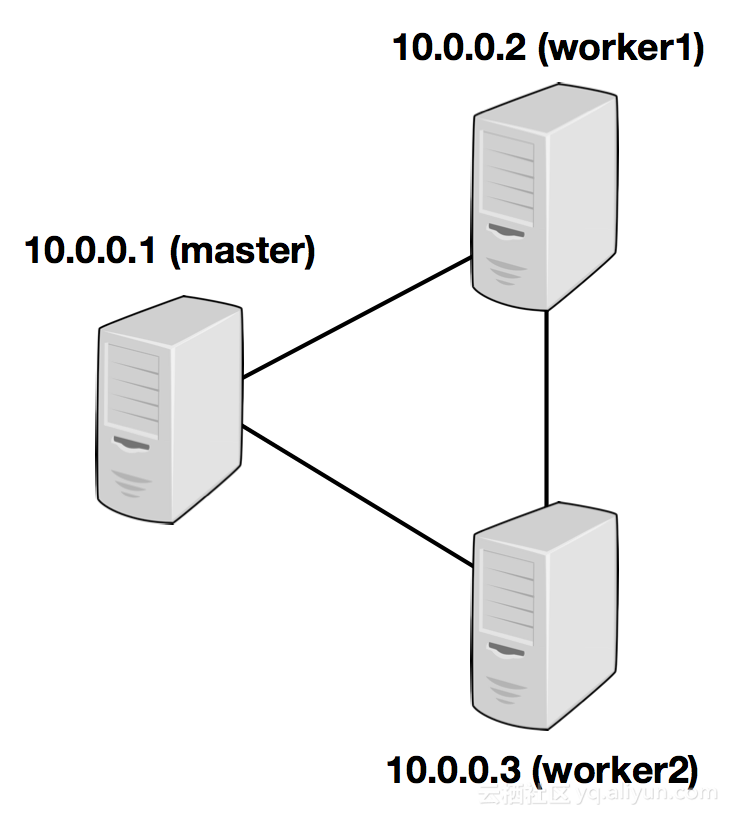
新增jobManager/TaskManager
可以使用 bin/jobmanager.sh 和 bin/taskmanager.sh 兩個指令碼把 JobManager 和 TaskManager 例項新增到正在執行的叢集中。
新增 JobManager
./bin/jobmanager.sh ((start|start-foreground) [host] [webui-port])|stop|stop-all
新增 TaskManager
./bin/taskmanager.sh start|start-foreground|stop|stop-all
啟動叢集
1 叢集模式啟動
/bin/start-cluster.sh
2. yarn 模式啟動
./bin/yarn-session.sh
Usage:
Required
-n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
Optional
-D <arg> Dynamic properties
-d,--detached Start detached
-jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)
-nm,--name Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for HA modeFlink 基於 YARN 的恢復機制
Flink 的 YARN 客戶端通過下面的配置引數來控制容器的故障恢復。這些引數可以通過 conf/flink-conf.yaml 或者在啟動 YARN session 的時候通過 -D 引數來指定。
yarn.reallocate-failed:該引數控制了 Flink 是否該重新分配失敗的 TaskManager 容器。預設值:true
yarn.maximum-failed-containers:ApplicationMaster 能接受最多的失敗 container 數,直到 YARN 會話失敗。預設:初始請求的 TaskManager 數(-n)
yarn.application-attempts:ApplicationMaster(以及 TaskManager containers)重試次數。此引數預設值為1,如果 Application master 失敗,那麼整個 YARN session 會失敗。如果想增大 ApplicationMaster 重啟次數,可以把該引數的值調大一些。