python jieba庫的基本使用
阿新 • • 發佈:2018-11-06
第一步:先安裝jieba庫
輸入命令:pip install jieba

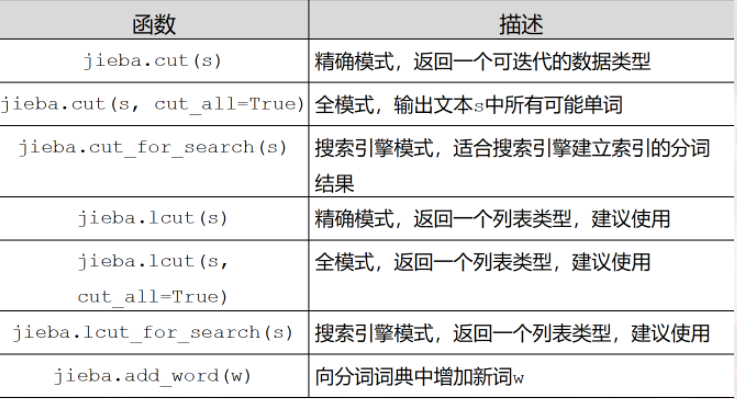
jieba庫常用函式:
jieba庫分詞的三種模式:
1、精準模式:把文字精準地分開,不存在冗餘
2、全模式:把文中所有可能的詞語都掃描出來,存在冗餘
3、搜尋引擎模式:在精準模式的基礎上,再次對長詞進行切分
精準模式:
>>> import jieba
>>> jieba.lcut("中國是一個偉大的國家")
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\25282\AppData\Local\Temp\jieba.cache
Loading model cost 0.869 seconds.
Prefix dict has been built succesfully.
['中國', '是', '一個', '偉大', '的', '國家']
全模式:
>>> jieba.lcut("中國是一個偉大的國家",cut_all=True)
['中國', '國是', '一個', '偉大', '的', '國家']
搜尋引擎模式:
>>> jieba.lcut_for_search("中華人民共和國是偉大的")
['中華', '華人', '人民', '共和', '共和國', '中華人民共和國', '是', '偉大', '的']
向分詞詞典增加新詞:
>>> jieba.add_word("蟒蛇語言")
>>> jieba.lcut("python是蟒蛇語言")
['python', '是', '蟒蛇語言']
jieba庫應用舉例1 ——統計八榮八恥中出現的詞彙


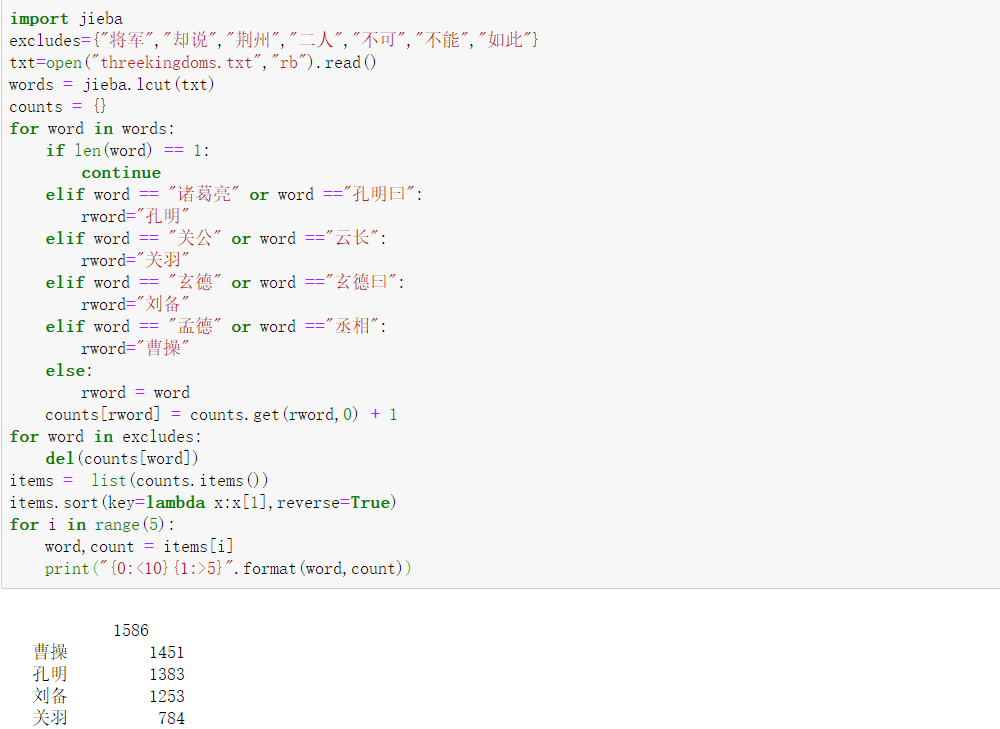
jieba庫分詞統計例項2--三國演義詞彙
(1)查找出“threekingdoms.txt”檔案中出現頻率前十位的詞彙

(2)統計出“threekingdoms.txt”檔案 “關羽”、“曹操”、“諸葛亮”、“劉備” 等人名出現的次數