
java java中subString、split、stringTokenizer三種擷取字串方法的效能比較
面試的時候,string 基本上是必須問的知識
突然想起面試的時候曾經被人問過:都知道在大資料量情況下,使用String的split擷取字串效率很低,有想過用其他的方法替代嗎?用什麼替代?我當時的回答很斬釘截鐵:沒有。
google了一下,發現有2中替代方法,於是在這裡我將對這三種方式進行測試。
測試的軟體環境為:Windows XP、eclipse、JDK1.6。
測試用例使用類ip形式的字串,即3位一組,使用”.”間隔。資料分別使用:5組、10組、100組、1000組、10000組、100000組。
實現
閒話不說,先上程式碼:
[java] view plain
- package test.java.lang.ref;
- import java.util.Random;
- import java.util.StringTokenizer;
- /**
- * String測試類
- * @author xiaori.Liu
- *
- */
- public class StringTest {
- public static void main(String args[]){
- String orginStr = getOriginStr(10);
- //////////////String.splic()表現//////////////////////////////////////////////
- System.out.println("使用String.splic()的切分字串");
- long st1 = System.nanoTime();
- String [] result = orginStr.split("\\.");
- System.out.println("String.splic()擷取字串用時:" + (System.nanoTime()-st1));
- System.out.println("String.splic()擷取字串結果個數:" + result.length);
- System.out.println();
- //////////////StringTokenizer表現//////////////////////////////////////////////
- System.out.println("使用StringTokenizer的切分字串");
- long st3 = System.nanoTime();
- StringTokenizer token=new StringTokenizer(orginStr,".");
- System.out.println("StringTokenizer擷取字串用時:"+(System.nanoTime()-st3));
- System.out.println("StringTokenizer擷取字串結果個數:" + token.countTokens());
- System.out.println();
- ////////////////////String.substring()表現//////////////////////////////////////////
- long st5 = System.nanoTime();
- int len = orginStr.lastIndexOf(".");
- System.out.println("使用String.substring()切分字串");
- int k=0,count=0;
- for (int i = 0; i <= len; i++) {
- if(orginStr.substring(i, i+1).equals(".")){
- if(count==0){
- orginStr.substring(0, i);
- }else{
- orginStr.substring(k+1, i);
- if(i == len){
- orginStr.substring(len+1, orginStr.length());
- }
- }
- k=i;count++;
- }
- }
- System.out.println("String.substring()擷取字串用時"+(System.nanoTime()-st5));
- System.out.println("String.substring()擷取字串結果個數:" + (count + 1));
- }
- /**
- * 構造目標字串
- * eg:10.123.12.154.154
- * @param len 目標字串組數(每組由3個隨機陣列成)
- * @return
- */
- private static String getOriginStr(int len){
- StringBuffer sb = new StringBuffer();
- StringBuffer result = new StringBuffer();
- Random random = new Random();
- for(int i = 0; i < len; i++){
- sb.append(random.nextInt(9)).append(random.nextInt(9)).append(random.nextInt(9));
- result.append(sb.toString());
- sb.delete(0, sb.length());
- if(i != len-1)
- result.append(".");
- }
- return result.toString();
- }
- }
改變目標資料長度修改getOriginStr的len引數即可。
5組測試資料結果如下圖:

下面這張圖對比了下,split耗時為substring和StringTokenizer耗時的倍數:
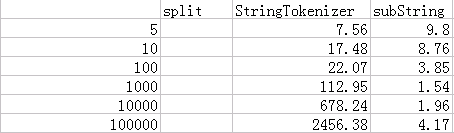
好吧,我又花了點兒時間,做了幾張圖表來分析這3中方式的效能。
首先來一張柱狀圖對比一下這5組資料擷取所花費的時間:
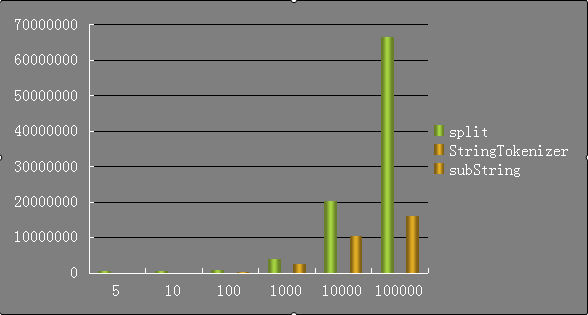
從上圖可以看出StringTokenizer的效能實在是太好了(對比另兩種),幾乎在圖表中看不見它的身影。遙遙領先。substring花費的時間始終比split要少,但是耗時也在隨著資料量的增加而增加。
下面3張折線圖可以很明顯看出split、substring、StringTokenizer3中實現隨著資料量增加,耗時的趨勢。
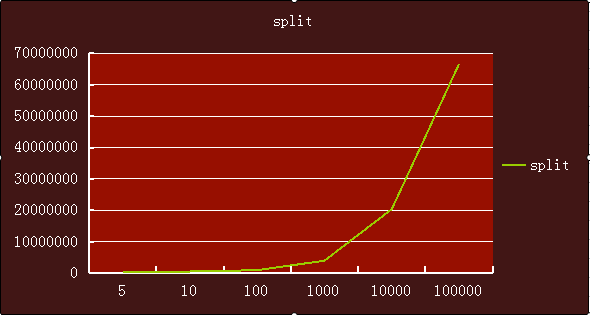
split是變化最大的,也就是資料量越大,擷取所需要的時間增長越快。
substring則比split要平穩一點點,但是也在增長。
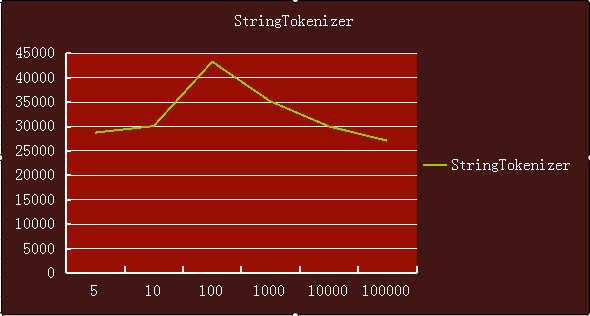
StringTokenizer則是表現最優秀的,基本上平穩,始終保持在5000ns一下。
結論
最終,StringTokenizer在擷取字串中效率最高,不論資料量大小,幾乎持平。substring則要次之,資料量增加耗時也要隨之增加。split則是表現最差勁的。
究其原因,split的實現方式是採用正則表示式實現,所以其效能會比較低。至於正則表示式為何低,還未去驗證。split原始碼如下:
[java] view plaincopyprint?
- public String[] split(String regex, int limit) {
- return Pattern.compile(regex).split(this, limit)
本文來自 HH-i 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/u013938165/article/details/23173309?utm_source=copy