
資料分析學習筆記(1):工作環境以及建模理論基礎
一、環境部署
1.python包管理:
(1)安裝:pip install xxx,conda install xxx
(2)解除安裝:pip uninstall xxx, conda uninstall xxx
(3)升級:pip install -upgrade xxx, conda update xxx
2.IDE
1)Jupyter notebook:
(1)Anaconda自帶,無需單獨安裝
(2)記錄思考過程,實時檢視執行程序
(3)基於web的線上編輯器(本地)
(4).ipynb檔案分享
(5)可互動式
(6)記錄歷史執行結果
(7)支援Markdown,Latex
2)IPython
(1)Anaconda自帶,無需單獨安裝
(2)Python的互動式命令列Shell
二、NumPy資料結構以及向量化
1.Numpy :Numerical Python
(1)高效能科學計算和資料分析(pandas)的基礎包,提供多維陣列物件
(2)ndarray,多維陣列(矩陣),具有向量運算能力,快速、節省空間
(3)矩陣運算,無需迴圈,可完成類似Matlab中的向量運算
(4)線性代數、隨機數生成
(5)import numpy as np
2.Scipy
(1)在NumPy庫的基礎上增加了眾多數學、科學以及工程常用的庫函式
(2)現行代數、微分方程求解、訊號處理、影象處理、係數矩陣等
(3)import scipy as sp
3.NumPy資料結構
(1)ndarray,N維陣列物件(矩陣)
所有元素型別必須相同
ndim屬性 維度的個數
shape屬性,各維度的大小
dtype屬性,資料型別
(2)建立ndarray
np.array(collection),collection為序列性物件(list),巢狀序列(list of list)
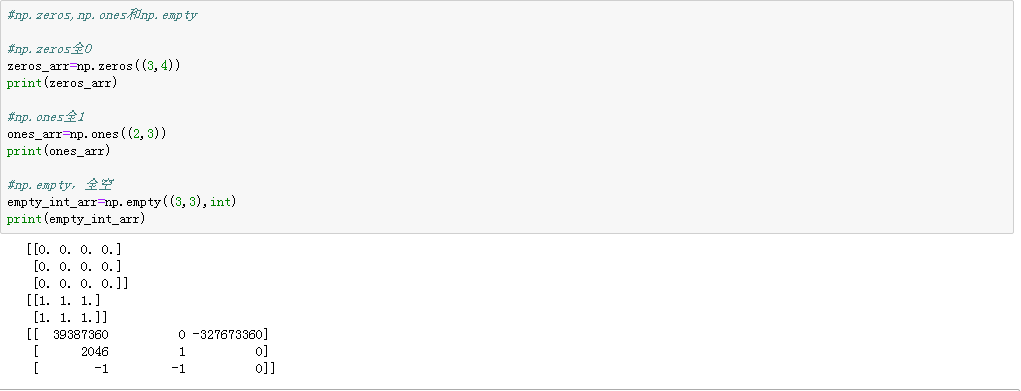
np.zeros,np.ones,no.empty指定大小全為0或者全為1的陣列
注意:第一個引數是元組,用來指定大小,如(3,4)
empty不是總是返回全0,有時候返回的是未初始的隨機值
4.程式碼學習
(1)生成兩行三列的隨機數,並打印出資料的型別
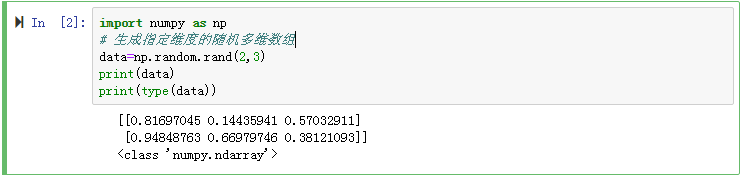
(2)分別打印出剛才建立的維度的個數,維度大小以及資料型別

(3)全0,全1以及全空
5.索引與切片
(1)一維陣列的索引與Python的列表索引功能相似
(2)多維陣列的索引
arr[r1:r2,c1:c2]
arr[1,1]等價於arr[1][1]
[:]代表某個維度的資料
arr[1:2,1:2]代表訪問陣列中第1行到第2行以及第1列到第2列的資料
(3)條件索引
布林值多維陣列arr[condition]condition可以是多個條件的組合。
注意,多個條件組合要使用& | 而不是and or