
機器學習之旅(五)
吳恩達教授的機器學習課程的第五週相關內容:
1、代價函式
首先引入一些便於稍後討論的新標記方法:
假設神經網路的訓練樣本有 m 個,每個包含一組輸入 x 和一組輸出訊號 y, L 表示神經網路層數, S I 表示每層的 neuron 個數(SL 表示輸出層神經元個數), S L 代表最後一層中處理
單元的個數。
將神經網路的分類定義為兩種情況:二類分類和多類分類,
在邏輯迴歸中,我們只有一個輸出變數,又稱標量(scalar) , 也只有一個因變數 y,但是在神經網路中,我們可以有很多輸出變數,我們的 h 是一個維度為 K 的向量,並且我們訓練集中的因變數也是同樣維度的一個向量,因此我們的代價函式會比邏輯迴歸更加複雜一些,為:
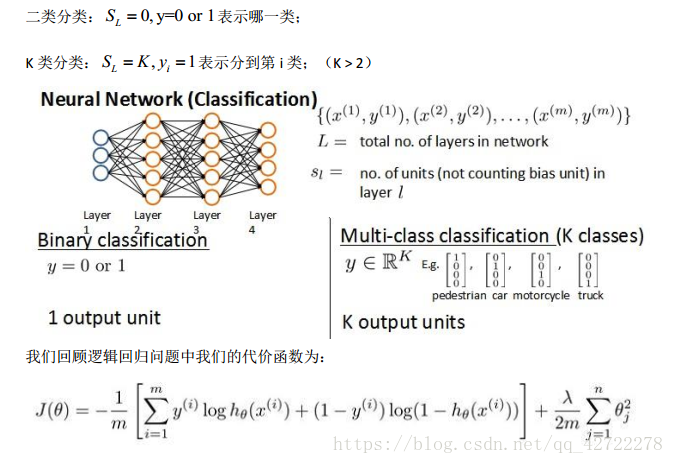

小結:代價函式的輸出更復雜一些,但本質和之前的輸出是一樣的。
2、反向傳播演算法
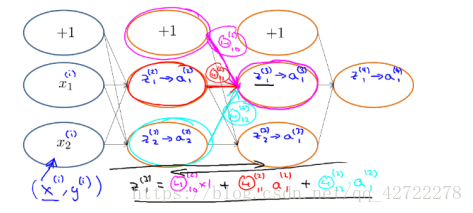
之前我們在計算神經網路預測結果的時候我們採用了一種正向傳播方法,我們從第一層開始正向一層一層進行計算,直到最後一層的 h。
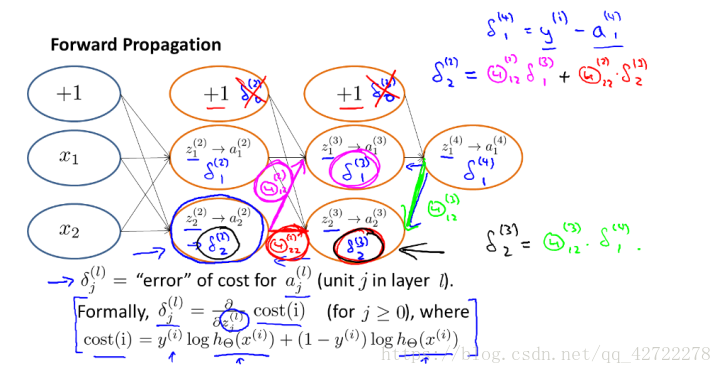
現在,為了計算代價函式的偏導數
,我們需要採用一種反向傳播演算法,也就是首先計算最後一層的誤差,然後再一層一層反向求出各層的誤差,直到倒數第二層。
以一個例子來說明反向傳播演算法。
假設我們的訓練集只有一個例項,我們的神經網路是一個四層的神經網路,
其中 K =4,
,L=4: 前向傳播演算法:
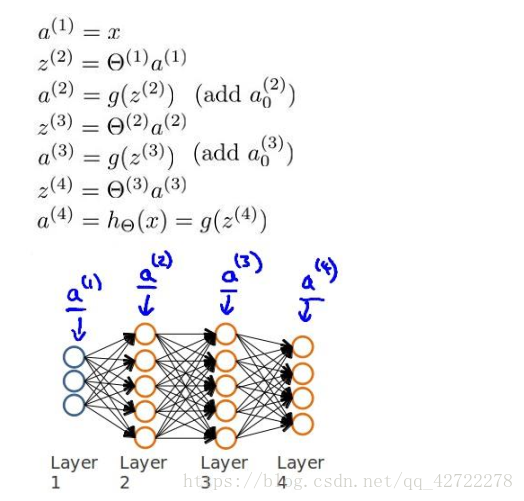

計算代價函式的偏導數:
前向傳播演算法:
反向傳播演算法做的是:
小結:反向傳播,顧名思義是從後往前推導的可以結合著前向傳播理解。
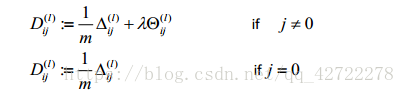
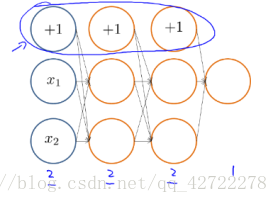

3、實現注意:展開引數
小結:這裡是為了更好的使用
而用的。

4、梯度檢驗
當我們對一個較為複雜的模型(例如神經網路)使用梯度下降演算法時,可能會存在一些不容易察覺的錯誤,意味著,雖然代價看上去在不斷減小,但最終的結果可能並不是最優解。
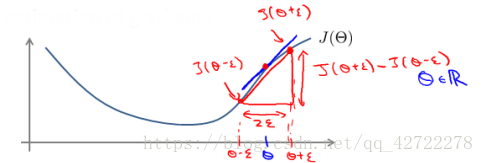
為了避免這樣的問題,我們採取一種叫做梯度的數值檢驗(Numerical Gradient Checking)方法。這種方法的思想是通過估計梯度值來檢驗我們計算的導數值是否真的是我們要求的。
對梯度的估計採用的方法是在代價函式上沿著切線的方向選擇離兩個非常近的點然後計算兩個點的平均值用以估計梯度。
當
是一個向量時,我們則需要對偏導數進行檢驗。因為代價函式的偏導數檢驗只針對
一個引數的改變進行檢驗,下面是一個只針對
進行檢驗的示例:
小結:估計梯度值來檢驗我們計算的導數值是否真的是我們要求的。
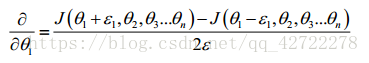
5、隨機初始化
任何優化演算法都需要一些初始的引數。到目前為止我們都是初始所有引數為 0,這樣的初始方法對於邏輯迴歸來說是可行的,但是對於神經網路來說是不可行的。如果我們令所有的初始引數都為 0,這將意味著我們第二層的所有啟用單元都會有相同的值。同理,如果我們初始所有的引數都為一個非 0 的數,結果也是一樣的。
小結:避免啟用單元有相同的值。
6、綜合起來
小結一下使用神經網路時的步驟:
網路結構:第一件要做的事是選擇網路結構,即決定選擇多少層以及決定每層分別有多少個單元。
第一層的單元數即我們訓練集的特徵數量。
最後一層的單元數是我們訓練集的結果的類的數量。
如果隱藏層數大於 1,確保每個隱藏層的單元個數相同,通常情況下隱藏層單元的個數越多越好。
我們真正要決定的是隱藏層的層數和每個中間層的單元數。
訓練神經網路:
- 引數的隨機初始化
- 利用正向傳播方法計算所有的 hθ(x)
- 編寫計算代價函式 J 的程式碼
- 利用反向傳播方法計算所有偏導數
- 利用數值檢驗方法檢驗這些偏導數
- 使用優化演算法來最小化代價函式
小結:訓練神經網路的步驟。
7、第五週程式設計題
1、nnCostFunction.m
h = eye(num_labels);
y = h(y,:); %5000x10
a1 = [ones(m, 1) X]; %5000x401
z2 = a1 * Theta1’ ;
a2 = sigmoid(z2);
n = size(a2,1);
a2 = [ones(n, 1) a2] ; %5000x26
a3 = sigmoid(a2 * Theta2’); %5000x10
J = sum( sum( -y.* log(a3) - (1-y).log(1-a3) ))/ m;
% pay attention :" Theta1(:,2:end) " , no “Theta1” .
regularized = lambda/(2m) * (sum(sum(Theta1(:,2:end).^2)) + sum(sum(Theta2(:,2:end).^2)) );
J = J + regularized;
%part2
delta3 = a3 - y; %500010
delta2 = delta3 * Theta2; %500026
delta2 = delta2(:, 2 : end);
delta2 = delta2 .* sigmoidGradient(z2); %5000*25
Delta_1 = zeros(size(Theta1));
Delta_2 = zeros(size(Theta2));
Delta_1 = Delta_1 + delta2’ * a1;
Delta_2 = Delta_2 + delta3’ * a2;
Theta1_grad = ((1 / m) * Delta_1) + ((lambda / m) * Theta1);
Theta2_grad = ((1 / m) * Delta_2) + ((lambda / m) * Theta2);
Theta1_grad(:, 1) = Theta1_grad(:, 1) - ((lambda / m) * (Theta1(:, 1)));
Theta2_grad(:, 1) = Theta2_grad(:, 1) - ((lambda / m) * (Theta2(:, 1)));
這周的關於公式怎麼推導怎麼來的是一頭霧水,日後看看李航老師的《統計學習方法吧》
2、sigmoidGradient.m
g=sigmoid(z).*(1-sigmoid(z))