
怎樣學好爬蟲的,選取爬蟲入手的瀏覽器,爬蟲認知篇(2)
阿新 • • 發佈:2018-11-07
選取一個瀏覽器,小白,網上得出結論谷歌瀏覽器OK!不是不讓用了嗎?怎麼還用谷歌??
為什麼爬蟲要用Chrome?
- 為什麼大家似乎都值得header應該怎麼寫?
- 為什麼大家都知道怎麼爬取網頁的路線?
- 為什麼....
如果你也跟我一樣,有過上面類似的疑問,那麼我覺得,這篇文章你可能值得看一下。
1. 設定谷歌
開啟設定--->有一個設定--->開啟設定
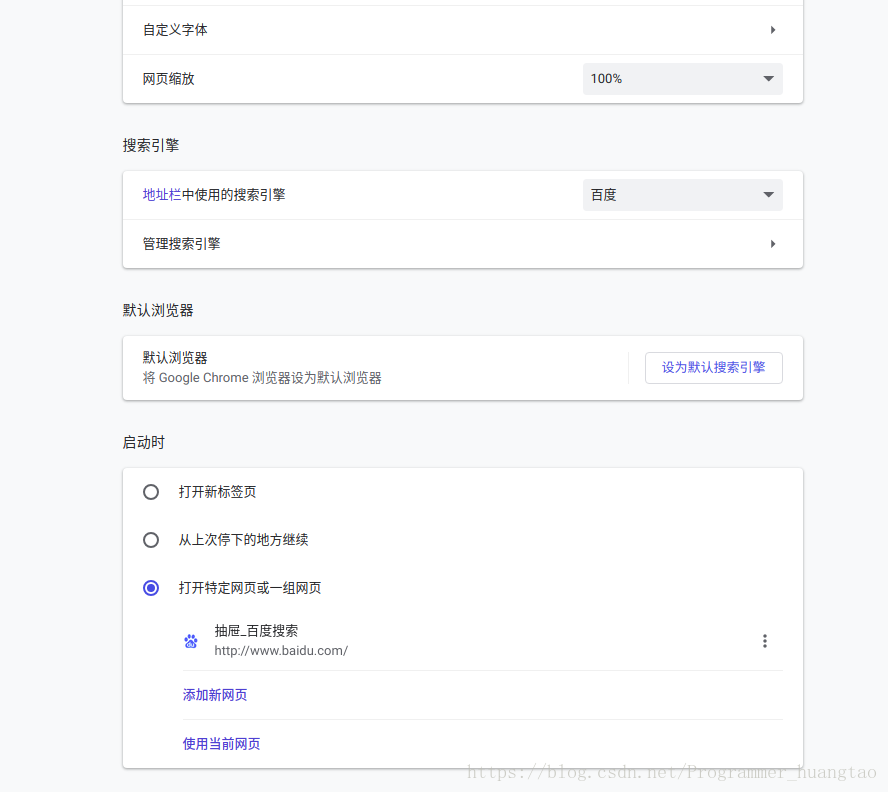
設定下滑到搜尋引擎選擇不是谷歌的,建議百度,把它設定成其他的引擎就行了,爬蟲用的是這個谷歌瀏覽器程式的功能,又不是谷歌瀏覽器介面對吧.
2.使用谷歌
用Chrome很容易看到網頁的原始碼輕鬆右鍵 -> 檢查,就可以看到這個原始碼.

通過瀏覽器得到載入的資料
檢查中還可以看網頁從伺服器上不斷載入包,雖然一開始我們點開的時候,網頁其實已經載入好了。對於所謂的靜態網頁在這個地方其實已經載入好了。(百度的首頁,一般會被認為是靜態網頁),但是還可以通過這個來看。 比如: 重新整理一下網頁~~~~~不過,在那之前,我們要點之前檢查的最上面的 network,一般預設是選中All模式的,在中間偏上的部分。點好之後,我們就可以重新整理

比如:我們可以檢查之前的那個包,就可以看那些包的具體資訊。那樣,我們就可以得到了所有很多重要的資訊了

比如像上面的我們可以看到這個資訊,是通過上面header拿到的。不過這個,有些會把這個給隱藏掉。但基本是沒有問題的,一般我們只要知道一個就好了。還有其他的騷操作,比如:看看這個包是怎麼拿下來的,這樣我們就可以特定地拿資料了。

通過這個,我們可以看到這個,用的是https://www.baidu.com/img/bd_logo1.png get,還可以得到對方的伺服器地址。

最後還可以通過最後的tim來看一下這個東西下載所用的時間
(可以算是測測速?)

這就是谷歌瀏覽器的設定及其用法,以後的爬蟲會經常使用的,也是作為爬蟲的一個基本技能.(沒設定的人趕緊去設定一下,沒用過的人趕緊去試一試!!!!)