
android圖形基礎知識
Android核心分析(23)-----Andoird GDI之基本原理及其總體框架
2010-06-13 22:49 18223人閱讀 評論(18) 收藏 舉報
AndroidGDI基本框架
在Android中所涉及的概念和程式碼最多,最繁雜的就是GDI相關的程式碼了。但是本質從抽象上來講,這麼多的程式碼和框架就幹了一件事情:對顯示緩衝區的操作和管理。
GDI主要管理圖形影象的輸出,從整體方向上來看,GDI可以被認為是一個物理螢幕使用的管理器。因為在實際的產品中,我們需要在物理螢幕上輸出不同的視窗,而每個視窗認為自己獨佔螢幕的使用,對所有視窗輸出,應用程式不會關心物理螢幕是否被別的窗口占用,而只是關心自己在本視窗的輸出,至於輸出是否能在螢幕上看見,則需要GDI來管理。
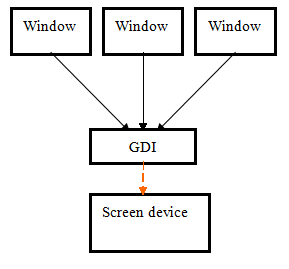{kind=link}
從最上層到最底層的資料流的分析可以看到實際上GDI在上層為GUI提供一個抽象的概念,就好像作業系統中的檔案系統所提供檔案,目錄等抽象概念一樣,GDI輸出抽象成了文字,畫筆,點陣圖操作等裝置無關的操作,讓應用程式設計師只需要面對邏輯的裝置上下文進行輸出操作,而不要涉及到具體輸出裝置,以及輸出邊界的管理。GDI負責將文字、線條、點陣圖等概念物件對映到具體的物理裝置,所以GDI的在大體方向上可以分為以下幾大要素:
畫布
字型
文字輸出
繪畫物件
點陣圖輸出
Android的GDI系統
Android的
Frameworks/Libs/Surfaceflinger
Frameworks/base/core/jni/android_view_Surface.cpp
Frameworks/base/core/java/android/view/surface.java
Frameworks/base/Graphics:繪圖介面
Frameworks/Libs/Ui
External/Skia
其中External/Skia是一個C++的2D圖形引擎庫,Android的2D繪製系統都是建立在該基礎之上.Skia完成了:文字輸出,點陣圖,點,線,影象解碼等功能。
我在這裡給出AndroidGDI的基本框架示意圖。
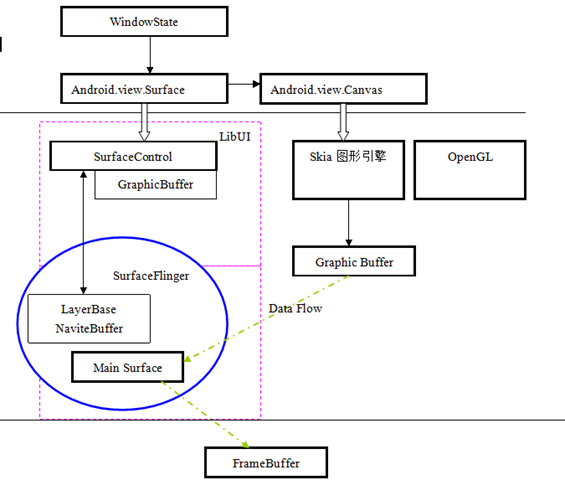{kind=link}
對於上面的GDI架構圖我們只是一個大概的瞭解,我們有太多的問題需要解決,有太多的疑問需要得到答案,我就一直在想,為什麼設計者有提出如此眾多的概念,這個概念的背景是什麼?他要管理什麼,他要抽象什麼?從前面知道,Android的整個設計理念就是無邊界化,他是如何穿透Linux程序這個鴻溝來達到無邊界的?Surface,Canvas, Layer,LayerBase,NativeBuffer,SurfaceFlinger,SurfaceFlingerClient這些到底是一個什麼東西?如何管理,傳遞的是什麼?建立的是什麼?這些都是抽象的概念,繪畫的終極的緩衝區到底是如何管理的?緩衝區到底在哪裡?
我們還是看看做終極的,最本質的設計概念,在從這些概念出發,來探討這些概念的形成過程,是否有必要去生成寫概念。SurfaceFlinger本質上幹什麼的?SurfaceFlinger的確就是這個意義:應用程式通過SurfaceFlinger將自己的“Surface”投擲到螢幕緩衝區。至於如何投擲的,我們將會在後面詳細描述。
Android核心分析(24)-----Android GDI之顯示緩衝管理
2010-06-14 13:36 24466人閱讀 評論(22) 收藏 舉報
Android GDI之螢幕裝置管理-動態連結庫
萬丈高樓從地起,從最根源的硬體幀緩衝區開始。我們知道顯示FrameBuffer在系統中就是一段記憶體,GDI的工作就是把需要輸出的內容放入到該段記憶體的某個位置。我們從基本的點(畫素點)和基本的緩衝區操作開始。
1 基本知識
1.1點的格式
對於不同的LCD來講,FrameBuffer的二進位制格式不一樣,並且可以分為兩部分:
1)點的格式:通常將Depth,即表示多少位表示一個點。
1位表示一個點
2位表示一個點
16位表示一個點
32位表示一個點(Alpha通道)
2) 點內格式:RGB分量分佈表示。
例如對於我們常見的16位表示一個點
{kind=link}
1.2.格式之間的轉換
所以螢幕輸出實際上是一個值對映的關係。我們可以有如下的點格式轉換,
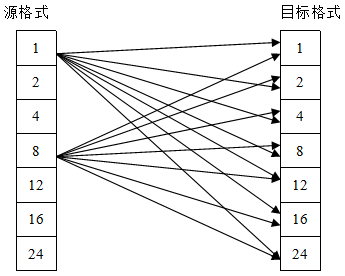{kind=link}
源格式可能來自單色點陣圖和彩色點陣圖,對於具體的目標機來講,我們的目標格式可能就是一種,例如16位(5/6/5)格式。其實就只存在一種格式的轉換,即從目標格式都是16位格式。
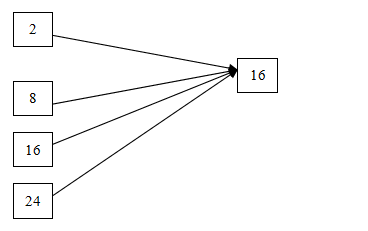{kind=link}
但是,在設計GDI時,基本要求有一個可移植性好,所以我們還是必須考慮對於不同點格式LCD之間的轉換操作。所以在GDI的驅動程式中涉及到如下幾類主要操作:
區域操作(Blit):我們在顯示緩衝區上做的最多的操作就是區塊搬運。由此,很多的應用處理器使用了硬體圖形加速器來完成區域搬運:blit.從我們的主要操作的物件來看,可以分為兩個方向:
1)記憶體區域到螢幕區域
2)螢幕區域到螢幕區域
3)螢幕區域到記憶體區域
4)記憶體區域到記憶體區域
在這裡我們需要特別提出的是,由於在Linux不同程序之間的記憶體不能自由的訪問,使得我們的每個Android應用對於記憶體區域和螢幕緩衝區的使用變得很複雜。在Android的設計中,在螢幕緩衝區和顯示記憶體緩衝區的管理分類很多的層次,最上層的物件是可以在程序間自由傳遞,但是對於緩衝區內容則使用共享記憶體的機制。
基於以上的基礎知識,我們可以知道:
(1)程式碼中Config及其Format的意義所在了。也就理解了相容性的意義:採用同硬體相同的點的描述物件
(2)所有螢幕上圖形的移動都是顯示緩衝區搬運的結果。
1.2圖形加速器
應用處理器都可能帶有圖形加速器,對於不同的應用處理器對其圖形加速器可能有不同的處理方式,對於2D加速來講,都可歸結為Blit。多為資料的搬運,放大縮小,旋轉等。
2 Android的緩衝區抽象定義
不同的硬體有不同的硬體圖形加速裝置和緩衝記憶體實現方法。Android Gralloc動態庫抽象的任務就是消除不同的裝置之間的差別,在上層看來都是同樣的方法和物件。在Moudle層隱藏緩衝區操作細節。Android使用了動態連結庫gralloc.xxx.so,來完成底層細節的封裝。
2.1 本地定義@hardware/libhandware/modules/gralloc
每個動態連結庫都是用相同名稱的呼叫介面:
1)硬體圖形加速器的抽象:BlitEngine,CopyBit的加速操作。
2)硬體FrameBuffer記憶體管理
3)共享快取管理
從資料關係上我們來考察..動態連結庫的抽象行為:在層次:[email protected]/libhardware中對動態連結庫中的內容作了全新的包裝。/system/lib/hw/gralloc.xxx.so動態庫檔案。從檔案Gralloc.h(handware/libhardware/include/hardware)是抽象的結果:hw_get_module從gralloc.xxx.so提取了HAL_MODULE_INFO_SYM(SYM變數)
{kind=link}
從展露在外部的資料結構,我們在@Gralloc.cpp看到到了這樣的佈局:
static structhw_module_methods_t gralloc_module_methods = {
open:gralloc_device_open
};
structprivate_module_t HAL_MODULE_INFO_SYM = {
base: {
common: {
tag: HARDWARE_MODULE_TAG,
…
id: GRALLOC_HARDWARE_MODULE_ID,
name: "Graphics Memory Allocator Module",
author: "The Android Open Source Project",
methods: &gralloc_module_methods
},
registerBuffer:gralloc_register_buffer,
unregisterBuffer:gralloc_unregister_buffer,
lock: gralloc_lock,
unlock: gralloc_unlock,
},
framebuffer: 0,
flags: 0,
numBuffers: 0,
bufferMask: 0,
…
};
我們建立了什麼物件來支撐緩衝區的操作?
buffer_handle_t:外部介面。
methods.open,registerBuffer,unregisterBuffer,lock,unlock
下面是外部介面和內部物件的結構關係,該型別的結構充分利用CStruct的資料排列特性:基本結構體放置在最前面,本地私有放置在後面,滿足了抽象的需要。
typedef constnative_handle* buffer_handle_t;
private_module_t HAL_MODULE_INFO_SYM 嚮往暴露的動態連結庫介面,通過該介面,我們直接可以使用該物件。
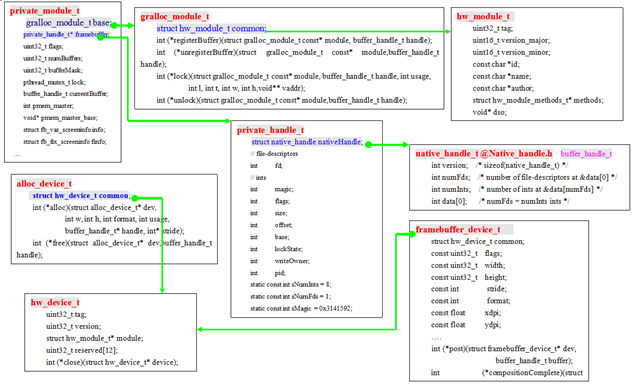{kind=link}
看不清楚上面圖,可以偏一下頭橫著看:
{kind=link}
幾個介面函式的解釋:
(1)fb_post
對於幀緩衝區實際地址並不需要向上層報告,所有的操作都是通過fb_post了完成。
fp_post的任務就是將一個Buffer的內容傳遞到硬體緩衝區。其實現方式有兩種:
(方式1)無需拷貝動作,是把Framebuffer的後buffer切為前buffer,然後通過IOCTRL機制告訴FB驅動切換DMA源地地址。這個實現方式的前提是Linux核心必須分配至少兩個緩衝區大小的實體記憶體和實現切換的ioctrol,這個實現快速切換。
(方式2)利用Copy的方式。不修改核心,則在適配層利用從拷貝的方式進行,但是這個是費時了。
(2)gralloc的主要功能是要完成:
1)開啟螢幕裝置 "/dev/fb0",,並對映硬體顯示緩衝區。
2)提供分配共享顯示快取的介面
3)提供BiltEngine介面(完成硬體加速器的包裝)
(3)gralloc_alloc輸出buffer_handle_t控制代碼。
這個控制代碼是共享的基本依據,其基本原理在後面的章節有詳細描述。
3 總結
總結一下,/system/lib/hw/gralloc.xxx.so是跟硬體體系相關的一個動態連結庫,也可以叫做Android的硬體抽象層。他實現了Android的硬體抽象介面標準,提供顯示記憶體的分配機制和CopyBit等的加速實現。而如何具體實現這些功能,則跟硬體平臺的配備有關係,所以我們看到了對於與不同的硬體架構,有不同的配置關係。
Android核心分析(25)------Android GDI之共享緩衝區機制
2010-06-14 16:29 17969人閱讀 評論(13) 收藏 舉報
Androird GDI之共享緩衝區機制
1 native_handle_t對private_handle_t的包裹
private_handle_t是gralloc.so使用的本地緩衝區私有的資料結構,而Native_handle_t是上層抽象的可以在程序間傳遞的資料結構。在客戶端是如何還原所傳遞的資料結構呢?首先看看native_handle_t對private_handle_t的抽象包裝。
{kind=link}
numFds= sNumFds=1;
numInts= sNumInts=8;
這個是Parcel中描述控制代碼的抽象模式。實際上是指的Native_handle所指向控制代碼物件的具體內容:
numFds=1表示有一個檔案控制代碼:fd/
numInts= 8表示後面跟了8個INT型的資料:magic,flags,size,offset,base,lockState,writeOwner,pid;
由於在上層系統不要關心buffer_handle_t中data的具體內容。在程序間傳遞buffer_handle_t(native_handle_t)控制代碼是其實是將這個控制代碼內容傳遞到Client端。在客戶端通過Binder讀取readNativeHandle @Parcel.cpp新生成一個native_handle。
native_handle*Parcel::readNativeHandle() const
{
…
native_handle* h =native_handle_create(numFds, numInts);
for(int i=0 ; err==NO_ERROR && i<="" font="">
h->data[i] = dup(readFileDescriptor());
if (h->data[i] < 0) err = BAD_VALUE;
}
err= read(h->data + numFds, sizeof(int)*numInts);
….
return h;
}
這裡需要提到的是為在構造客戶端的native_handle時,對於對方傳遞過來的檔案控制代碼的處理。由於不是在同一個程序中,所以需要dup(…)一下為客戶端使用。這樣就將Native_handle控制代碼中的,客戶端感興趣的從服務端複製過來。這樣就將Private_native_t的資料:magic,flags,size,offset,base,lockState,writeOwner,pid;複製到了客戶端。
客戶端利用這個新的Native_buffer被Mapper傳回到gralloc.xxx.so中,獲取到native_handle關聯的共享緩衝區對映地址,從而獲取到了該緩衝區的控制權,達到了客服端和Server間的記憶體共享。從SurfaceFlinger來看就是作圖區域的共享。
2 Graphic Mapper是幹什麼的?
服務端(SurfaceFlinger)分配了一段記憶體作為Surface的作圖緩衝,客戶端怎樣在這個作圖緩衝區上工作呢?這個就是Mapper(GraphicBufferMapper)y要乾的事情。兩個程序間如何共享記憶體,如何獲取到共享記憶體?Mapper就是幹這個得。需要利用到兩個資訊:共享緩衝區裝置控制代碼,分配時的偏移量。Mapper利用這樣的原理:
客戶端只有lock,unlock,實質上就是mmap和ummap的操作。對於同樣一個共享緩衝區,偏移量才是總要的,起始地址不重要。實際上他們操作了同一實體地址的記憶體塊。我們在上面討論了native_handle_t對private_handle_t 的包裹過程,從中知道服務端給客戶端傳遞了什麼東西。
程序1在共享記憶體裝置上預分配了8M的記憶體。以後所有的分配都是在這個8M的空間進行。對以該檔案裝置來講,8M實體記憶體提交後,就實實在在的佔用了8M記憶體。每個每個程序都可以同個該記憶體裝置共享該8M的記憶體,他們使用的工具就會mmap。由於在mmap都是用0開始獲取對映地址,所以所有的客戶端程序都是有了同一個物理其實地址,所以此時偏移量和size就可以標識一段記憶體。而這個偏移量和size是個數值,從服務程序傳遞到客戶端直接就可以使用。
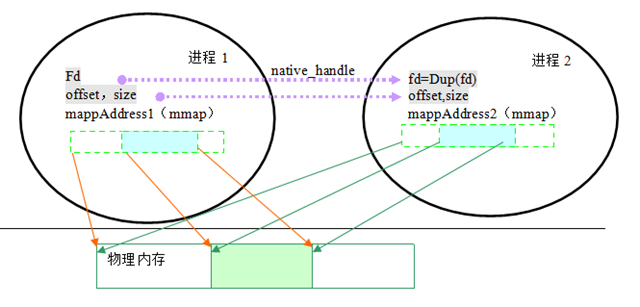{kind=link}
3 GraphicBuffer(緩衝區代理物件)
typedef structandroid_native_buffer_t
{
struct android_native_base_t common;
intwidth;
intheight;
intstride;
intformat;
intusage;
…
buffer_handle_thandle;
…
}android_native_buffer_t;
關係圖表:
GraphicBuffer :EGLNativeBase:android_native_buffer_t
GraphicBuffer(parcel&)建立本地的GraphicBuffer的資料native_buffer_t。在通過接收對方的傳遞的native_buffer_t 構建GraphicBuffer。我們來看看在客戶端Surface::lock獲取操作緩衝區的函式呼叫:
Surface::lock(SurfaceInfo*other, Region* dirtyIn, bool blocking)
{int Surface::dequeueBuffer(android_native_buffer_t** buffer)(Surface)
{status_t Surface::getBufferLocked(int index, int usage)
{
sp buffer= s->requestBuffer(index, usage);
{
virtual sp requestBuffer(intbufferIdx, int usage)
{ remote()->transact(REQUEST_BUFFER, data, &reply);
sp buffer = newGraphicBuffer(reply);
Surface::Lock建立一個在Client端建立了一個新的GraphicBuffer物件,該物件通過(1)描述的原理將SurfaceFlinger的buffer_handle_t相關資料構成新的客戶端buffer_handle_t資料。在客戶端的Surface物件就可以使用GraphicMapper對客戶端buffer_handle_t進行mmap從而獲取到共享緩衝區的開始地址了。
4 總結
Android在該節使用了共享記憶體的方式來管理與顯示相關的緩衝區,他設計成了兩層,上層是緩衝區管理的代理機構GraphicBuffer,及其相關的native_buffer_t,下層是具體的緩衝區的分配管理及其緩衝區本身。上層的物件是可以在經常間通過Binder傳遞的,而在程序間並不是傳遞緩衝區本身,而是使用mmap來獲取指向共同實體記憶體的對映地址。
Android核心分析(26)-----Android GDI之SurfaceFlinger
2010-06-14 20:31 36394人閱讀 評論(28) 收藏 舉報
Android GDI之SurfaceFlinger
SurfaceFinger按英文翻譯過來就是Surface投遞者。SufaceFlinger的構成並不是太複雜,複雜的是他的客戶端建構。SufaceFlinger主要功能是:
1) 將Layers(Surfaces) 內容的重新整理到螢幕上
2) 維持Layer的Zorder序列,並對Layer最終輸出做出裁剪計算。
3) 響應Client要求,建立Layer與客戶端的Surface建立連線
4) 接收Client要求,修改Layer屬性(輸出大小,Alpha等設定)
但是作為投遞者的實際意義,我們首先需要知道的是如何投遞,投擲物,投遞路線,投遞目的地。
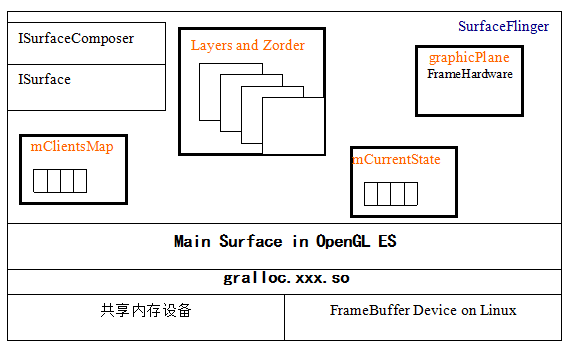
1 SurfaceFlinger的基本組成框架
{kind=link}
SurfaceFlinger管理物件為:
mClientsMap:管理客戶端與服務端的連線。
ISurface,IsurfaceComposer:AIDL呼叫介面例項
mLayerMap:服務端的Surface的管理物件。
mCurrentState.layersSortedByZ:以Surface的Z-order序列排列的Layer陣列。
graphicPlane 緩衝區輸出管理
OpenGL ES:圖形計算,影象合成等圖形庫。
gralloc.xxx.so這是個跟平臺相關的圖形緩衝區管理器。
pmem Device:提供共享記憶體,在這裡只是在gralloc.xxx.so可見,在上層被gralloc.xxx.so抽象了。
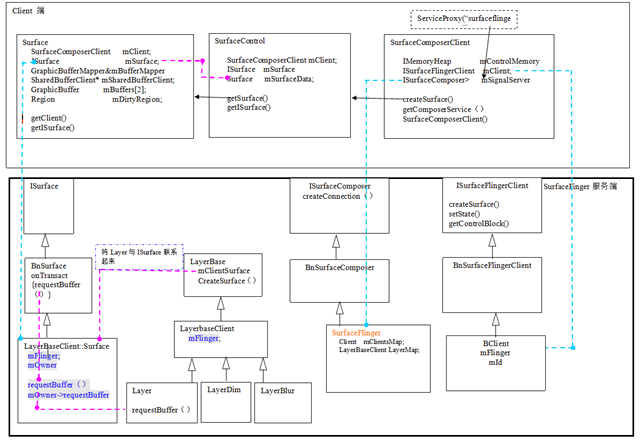
2 SurfaceFinger Client和服務端物件關係圖
{kind=link}
Client端與SurfaceFlinger連線圖:
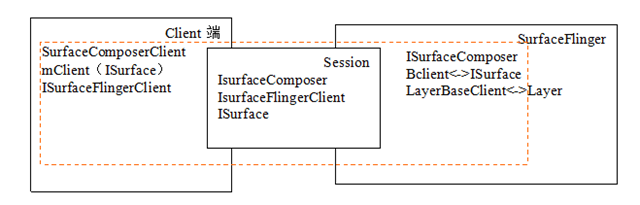{kind=link}
Client物件:一般的在客戶端都是通過SurfaceComposerClient來跟SurfaceFlinger打交道。
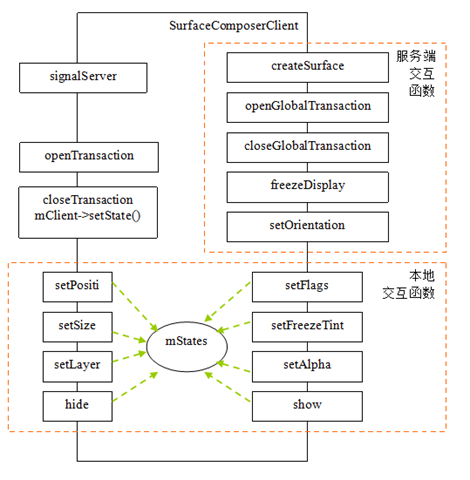{kind=link}
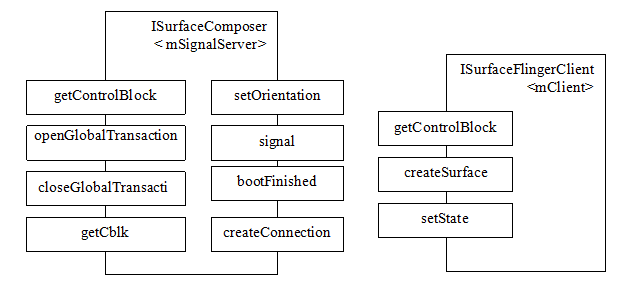{kind=link}
3 主要物件說明
3.1 DisplayHardware&FrameBuffer
首先SurfaceFlinger需要操作到螢幕,需要建立一個螢幕硬體緩衝區管理框架。Android在設計支援時,考慮多個螢幕的情況,引入了graphicPlane的概念。在SurfaceFlinger上有一個graphicPlane陣列,每一個graphicPlane物件都對應一個DisplayHardware.在當前的Android(2.1)版本的設計中,系統支援一個graphicPlane,所以也就支援一個DisplayHardware。
SurfaceFlinger,Hardware硬體緩衝區的資料結構關係圖。
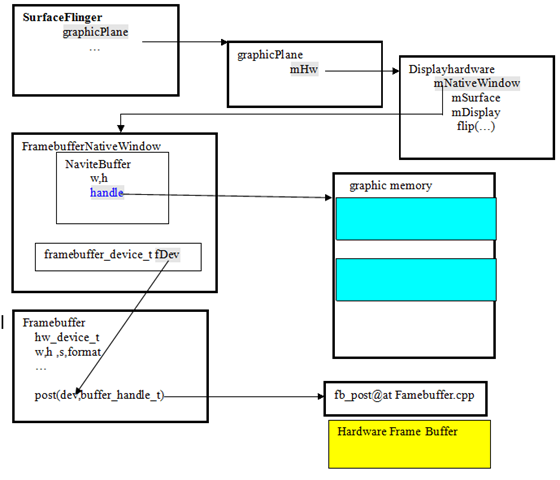{kind=link}
3.2 Layer
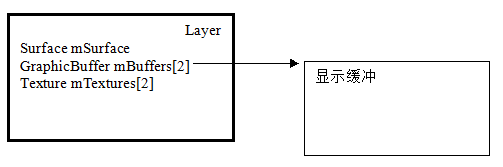{kind=link}
method:setBuffer 在SurfaceFlinger端建立顯示緩衝區。這裡的緩衝區是指的HW性質的,PMEM裝置檔案對映的記憶體。
1) layer的繪製
voidLayer::onDraw(const Region& clip) const
{
intindex = mFrontBufferIndex;
GLuint textureName = mTextures[index].name;
…
drawWithOpenGL(clip,mTextures[index]);
}
3.2mCurrentState.layersSortedByZ
以Surface的Z-order序列排列的LayerBase陣列,該陣列是層顯示遮擋的依據。在每個層計算自己的可見區域時,從Z-order 頂層開始計算,是考慮到遮擋區域的裁減,自己之前層的可見區域就是自己的不可見區域。而繪製Layer時,則從Z-order底層開始繪製,這個考慮到透明層的疊加。
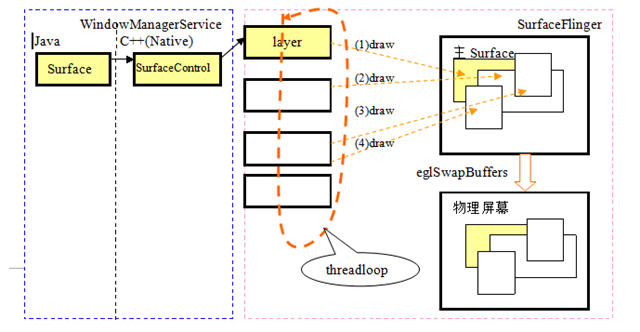
4 SurfaceFlinger的執行框架
我們從前面的章節<Android Service>的基本原理可以知道,SurfaceFlinger的執行框架存在於:threadLoop,他是SurfaceFlinger的主迴圈體。SurfaceFlinger在進入主體迴圈之前會首先執行:SurfaceFlinger::readyToRun()。
4.1SurfaceFlinger::readyToRun()
(1)建立GraphicPanle
(2)建立FrameBufferHardware(確定輸出目標)
初始化:OpenGL ES
建立相容的mainSurface.利用eglCreateWindowSurface。
建立OpenGL ES程序上下文。
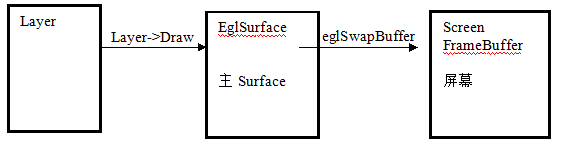
建立主Surface(OpenGL ES)。DisplayHardware的Init()@DisplayHardware.cpp函式對OpenGL做了初始化,並建立立主Surface。為什麼叫主Surface,因為所有的Layer在繪製時,都需要先繪製在這個主Surface上,最後系統才將主Surface的內容”投擲”到真正的螢幕上。
(3) 主Surface的繫結
1)在DisplayHandware初始完畢後,hw.makeCurrent()將主Surface,OpenGL ES程序上下文繫結到SurfaceFlinger的上下文中,
2)之後所有的SurfaceFlinger程序中使用EGL的所有的操作目的地都是[email protected]。
這樣,在OpenGL繪製圖形時,主Surface被記錄在程序的上下文中,所以看不到顯示的主Surfce相關引數的傳遞。下面是Layer-Draw,Hardware.flip的動作示意圖:
{kind=link}
4.2 ThreadLoop
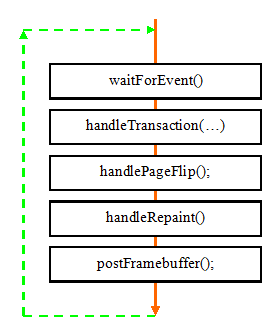{kind=link}
(1)handleTransaction(…):主要計算每個Layer有無屬性修改,如果有修改著內用需要重畫。
(2)handlePageFlip()
computeVisibleRegions:根據Z-Order序列計算每個Layer的可見區域和被覆蓋區域。裁剪輸出範圍計算-
在生成裁剪區域的時候,根據Z_order依次,每個Layer在計算自己在螢幕的可顯示區域時,需要經歷如下步驟:
1)以自己的W,H給出自己初始的可見區域
2)減去自己上面視窗所覆蓋的區域
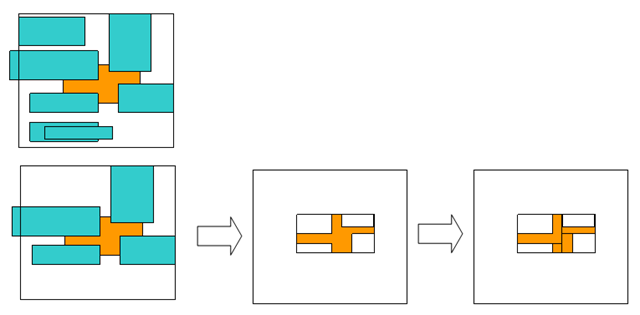{kind=link}
在繪製時,Layer將根據自己的可將區域做相應的區域資料Copy。
(3)handleRepaint()
composeSurfaces(需要重新整理區域):
根據每個Layer的可見區域與需要重新整理區域的交集區域從Z-Order序列從底部開始繪製到主Surface上。
(4)postFramebuffer()
(DisplayHardware)hw.flip(mInvalidRegion);
eglSwapBuffers(display,mSurface):將mSruface投遞到螢幕。
5總結
現在SurfaceFlinger乾的事情利用下面的示意圖表示出來:
{kind=link}
Android核心分析(27)-----Android GDI 之SurfaceFlinger之動態結構示意圖
2010-06-14 22:02 18942人閱讀 評論(12) 收藏 舉報
SurfaceFlinger物件建立過程示意
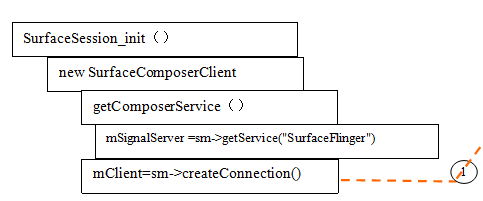
1SurfaceSession的建立
客戶端請求建立Surface時,首先在要與SurfaceFlinger建立一個Session,然後再Session上建立一個Connection通過概念返回Bclient物件。WindowManagerService在新增第一個視窗前會檢查SurfaceSession是否建立,如何沒有建立,將會新建立一個例項來代表與SurfaceFlinger的一個連線。
new SurfaceSession()@windowAddedLocked()@WindowManagerService.java。
SurfaceSession的建立過程大部分是在C++ Native空間中完成的,表現在SurfaceSession的初始化函式:init()本地函式上。從下面的初始化函式可以看到:
Init()<->[email protected]_view_Surface.cpp
new SurfaceComposerClient
SurfaceSession在C++Native空間建立一個SurfaceComposerClient例項。而該例項的建立實現瞭如下的與SurfaceFlinger通訊基礎:
(1)建立了代理SurfaceFlinger服務的代理服務端
(2)建立了IsurfaceFlingerClient連線,在SurfaceFlinger端建立了對應的Client,並將BClient返回給WindowManagerService。
{kind=link}
{kind=link}
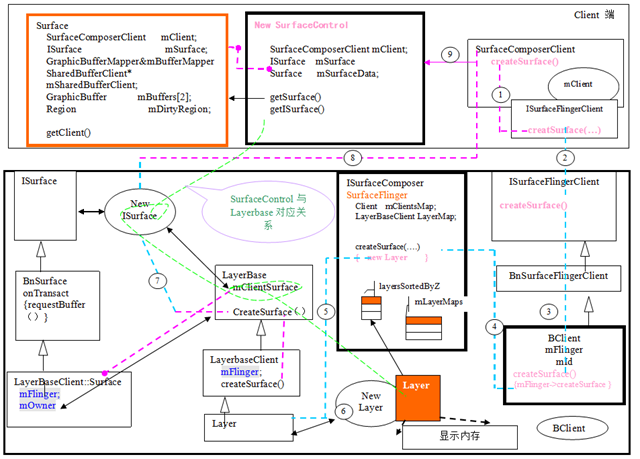
2Surface的建立
在WindowManagerService中WindowState類中,我們知道每個主視窗子啊需要是都需要建立一個Surface與之對應。win.createSurfaceLocked()@relayoutWindow
Surface.java
Init()< -->Surface_init(….,session,pid,dpy,w,h,format)@android_view_Surface.cpp
SurfaceControl surface(client->createSurface
在mClient的連線上:建立ISurface介面:
M_Client->greateSurface(...)@
Bclient ::createSurface(mId...)@SurfaceFlinger.cpp
mFlinger->createSurface(clientid....)
createNormalSurfaceLocked
*createNormalSurfaceLocked:建立一個Layer分配顯示記憶體
*createPushBuffersSurfaceLocked:建立一個LayBuffer但是不分配顯示記憶體。
{kind=link}
Android核心分析(28)-----Android GDI之Surface&Canvas
2010-06-14 22:05 20162人閱讀 評論(41) 收藏 舉報
Surface&Canvas
Canvas為在畫布的意思。Android上層的作圖幾乎都通過Canvas例項來完成,其實Canvas更多是一種介面的包裝。drawPaints ,drawPoints,drawRect,drawBitmap...
{kind=link}
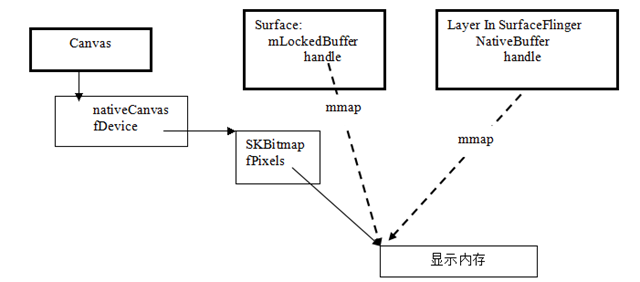
1 Canvas與Surface之間本質關係
對於本節,我們不去研究Skia圖形引擎本身,我們需要了解的我們的所做的圖形到底放置到了那個地方,並且這個Canvas如何與Surface連線在一起的。
Canvas(Java)在C++Native層有一個Native Canvas的C++物件所對應。
lockCanvas()@java
[email protected]_view_Surface.cpp
SurfaceControl->newSurface(control) @Surface.cpp
Surface: lock操作:
{kind=link}
GraphicBuffer :lock
getBufferMapper().lock<-> GraphicBufferMapper ::lock
mAllocMod->lock<->gralloc_module_t::lock
通過SurfaceLock可取得Surface(mLockedBuffe)所對應的圖形緩衝區地址。
(1) 建立與SkCanvas連線的點陣圖裝置,而該點陣圖使用上面取得的圖形緩衝區地址做自己的點陣圖記憶體。
(2) 設定SkCanvas的作圖目標裝置為該點陣圖。
通過該過程就建立起了SurfaceControl與Canvas之間的聯絡。
{kind=link}
不是使用OpenGL繪製時,Android在View屬性發生變化,新建View時,或者Z-order發生變化時,需要對系統螢幕上的View重新繪製,此時我們的View會執行OnDraw(canvas),這個根源在哪裡呢?
ViewRoot.Java
performTraversals(..)
…
draw()
canvas = surface.lockCanvas(dirty);
…
mView.draw(canvas);
draw(cavas)@view.java
background.draw(canvas);
onDraw(cavas)
dispatchDraw(cavas)
onDrawScrolbars(cavas)
surface.unlockCanvasAndPost(canvas);