(九)Hive的5個面試題
(九)Hive的5個面試題
目錄
正文
一、求單月訪問次數和總訪問次數
1、資料說明
資料欄位說明
使用者名稱,月份,訪問次數
資料格式
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,16
A,2015-03,22
B,2015-03,23
B,2015-03,10
B,2015-03,12、資料準備
(1)建立表
use myhive;
create external table if not exists t_access(
uname string comment '使用者名稱',
umonth string comment '月份',
ucount int comment '訪問次數'
) comment '使用者訪問表'
row format delimited fields terminated by ","
location "/hive/t_access"; (2)匯入資料
load data local inpath "/home/hadoop/access.txt" into table t_access;
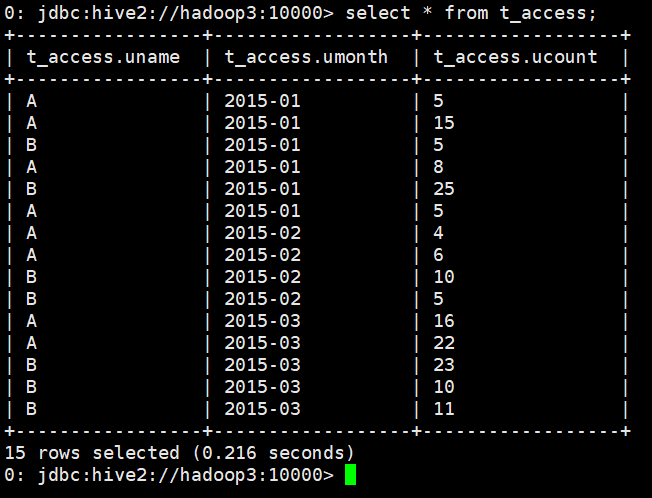
(3)驗證資料
select * from t_access;
3、結果需求
現要求出:
每個使用者截止到每月為止的最大單月訪問次數和累計到該月的總訪問次數,結果資料格式如下

4、需求分析
此結果需要根據使用者+月份進行分組
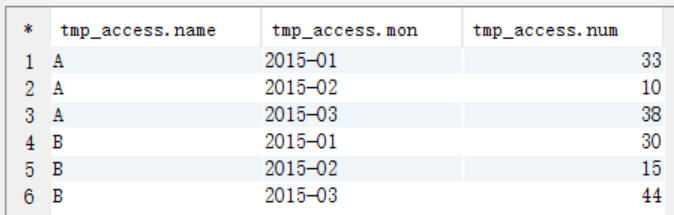
(1)先求出當月訪問次數
--求當月訪問次數
create table tmp_access(
name string,
mon string,
num int
);
insert into table tmp_access
select uname,umonth,sum(ucount)
from t_access t group by t.uname,t.umonth;
select * from tmp_access;
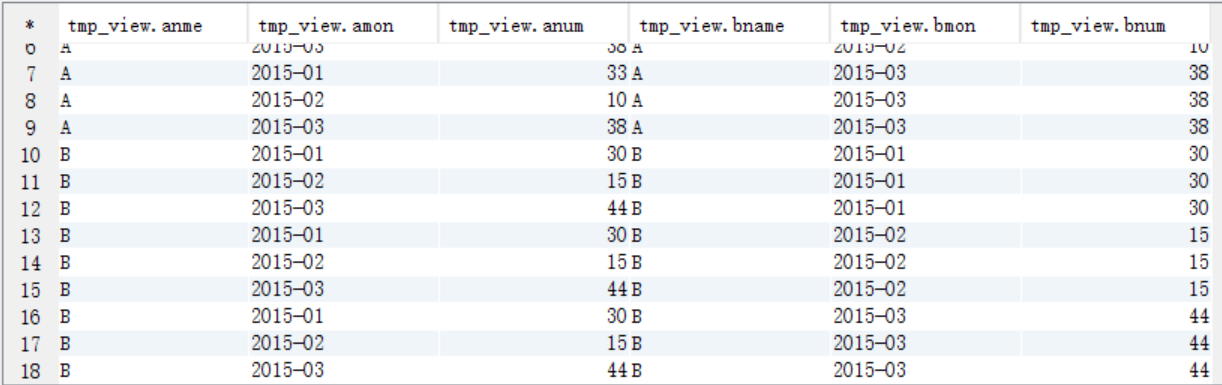
(2)tmp_access進行自連線檢視
create view tmp_view as
select a.name anme,a.mon amon,a.num anum,b.name bname,b.mon bmon,b.num bnum from tmp_access a join tmp_access b
on a.name=b.name;
select * from tmp_view;
(3)進行比較統計
select anme,amon,anum,max(bnum) as max_access,sum(bnum) as sum_access
from tmp_view
where amon>=bmon
group by anme,amon,anum;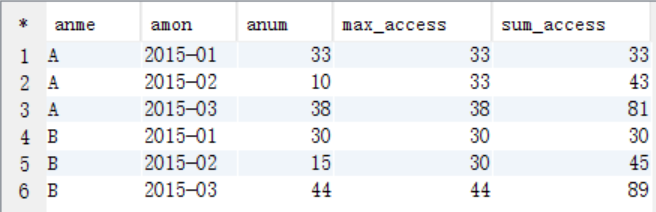
二、學生課程成績
1、說明
use myhive;
CREATE TABLE `course` (
`id` int,
`sid` int ,
`course` string,
`score` int
) ;
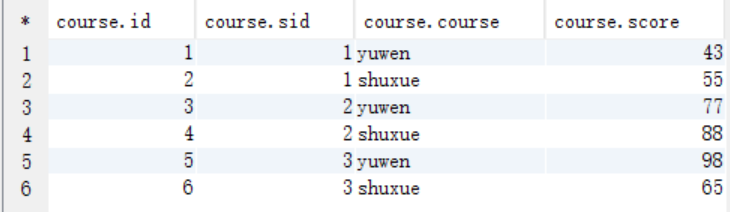
// 插入資料
// 欄位解釋:id, 學號, 課程, 成績
INSERT INTO `course` VALUES (1, 1, 'yuwen', 43);
INSERT INTO `course` VALUES (2, 1, 'shuxue', 55);
INSERT INTO `course` VALUES (3, 2, 'yuwen', 77);
INSERT INTO `course` VALUES (4, 2, 'shuxue', 88);
INSERT INTO `course` VALUES (5, 3, 'yuwen', 98);
INSERT INTO `course` VALUES (6, 3, 'shuxue', 65);
2、需求
求:所有數學課程成績 大於 語文課程成績的學生的學號
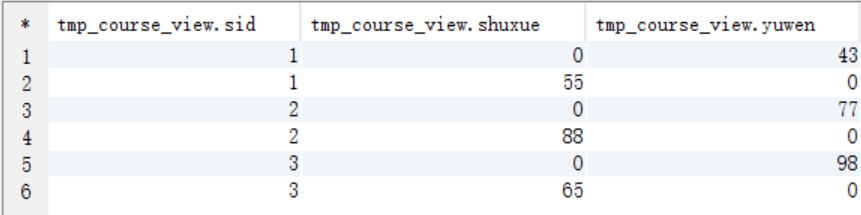
1、使用case...when...將不同的課程名稱轉換成不同的列
create view tmp_course_view as
select sid, case course when "shuxue" then score else 0 end as shuxue,
case course when "yuwen" then score else 0 end as yuwen from course; select * from tmp_course_view;
2、以sid分組合並取各成績最大值
create view tmp_course_view1 as
select aa.sid, max(aa.shuxue) as shuxue, max(aa.yuwen) as yuwen from tmp_course_view aa group by sid; select * from tmp_course_view1;

3、比較結果
select * from tmp_course_view1 where shuxue > yuwen;

三、求每一年最大氣溫的那一天 + 溫度
1、說明
資料格式
2010012325
具體資料
 View Code
View Code
資料解釋
2010012325表示在2010年01月23日的氣溫為25度
2、 需求
比如:2010012325表示在2010年01月23日的氣溫為25度。現在要求使用hive,計算每一年出現過的最大氣溫的日期+溫度。
要計算出每一年的最大氣溫。我用
select substr(data,1,4),max(substr(data,9,2)) from table2 group by substr(data,1,4);
出來的是 年份 + 溫度 這兩列資料例如 2015 99
但是如果我是想select 的是:具體每一年最大氣溫的那一天 + 溫度 。例如 20150109 99
請問該怎麼執行hive語句。。
group by 只需要substr(data,1,4),
但是select substr(data,1,8),又不在group by 的範圍內。
是我陷入了思維死角。一直想不出所以然。。求大神指點一下。
在select 如果所需要的。不在group by的條件裡。這種情況如何去分析?
3、解析
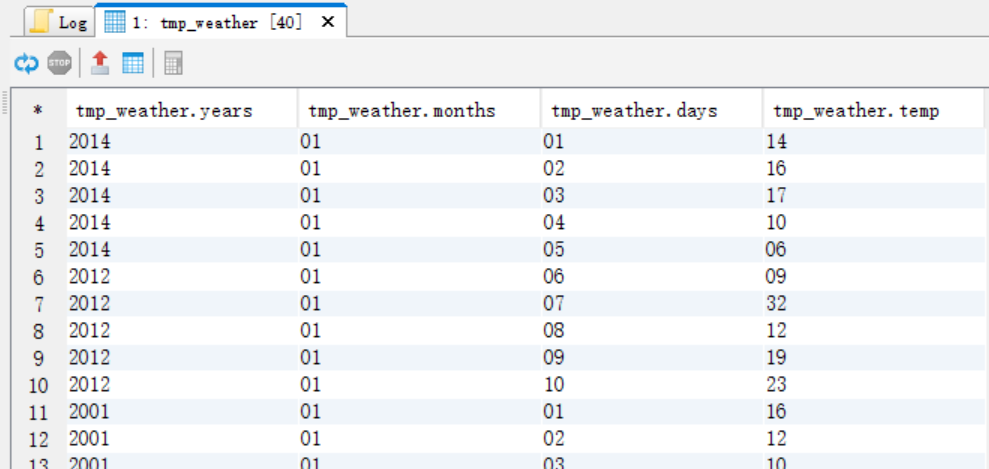
(1)建立一個臨時表tmp_weather,將資料切分
create table tmp_weather as
select substr(data,1,4) years,substr(data,5,2) months,substr(data,7,2) days,substr(data,9,2) temp from weather;select * from tmp_weather;
(2)建立一個臨時表tmp_year_weather
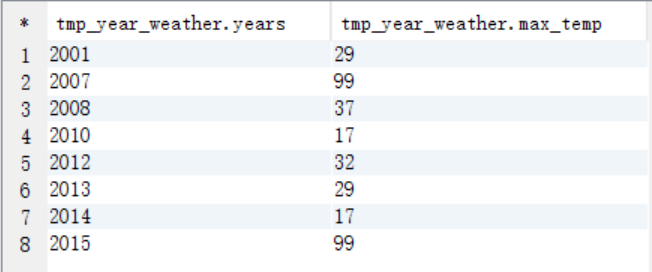
create table tmp_year_weather as
select substr(data,1,4) years,max(substr(data,9,2)) max_temp from weather group by substr(data,1,4);select * from tmp_year_weather;
(3)將2個臨時表進行連線查詢
select * from tmp_year_weather a join tmp_weather b on a.years=b.years and a.max_temp=b.temp;
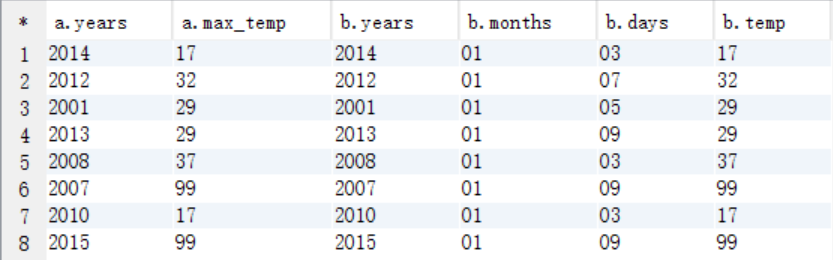
四、求學生選課情況
1、資料說明
(1)資料格式
id course
1,a
1,b
1,c
1,e
2,a
2,c
2,d
2,f
3,a
3,b
3,c
3,e(2)欄位含義
表示有id為1,2,3的學生選修了課程a,b,c,d,e,f中其中幾門。
2、資料準備
(1)建表t_course
create table t_course(id int,course string) row format delimited fields terminated by ",";

(2)匯入資料
load data local inpath "/home/hadoop/course/course.txt" into table t_course;

3、需求
編寫Hive的HQL語句來實現以下結果:表中的1表示選修,表中的0表示未選修
id a b c d e f
1 1 1 1 0 1 0
2 1 0 1 1 0 1
3 1 1 1 0 1 04、解析
第一步:
select collect_set(course) as courses from id_course;
第二步:
set hive.strict.checks.cartesian.product=false;
create table id_courses as select t1.id as id,t1.course as id_courses,t2.course courses
from
( select id as id,collect_set(course) as course from id_course group by id ) t1
join
(select collect_set(course) as course from id_course) t2;
啟用嚴格模式:hive.mapred.mode = strict // Deprecated
hive.strict.checks.large.query = true
該設定會禁用:1. 不指定分頁的orderby
2. 對分割槽表不指定分割槽進行查詢
3. 和資料量無關,只是一個查詢模式hive.strict.checks.type.safety = true
嚴格型別安全,該屬性不允許以下操作:1. bigint和string之間的比較
2. bigint和double之間的比較hive.strict.checks.cartesian.product = true
該屬性不允許笛卡爾積操作
第三步:得出最終結果:
思路:
拿出course欄位中的每一個元素在id_courses中進行判斷,看是否存在。
select id,
case when array_contains(id_courses, courses[0]) then 1 else 0 end as a,
case when array_contains(id_courses, courses[1]) then 1 else 0 end as b,
case when array_contains(id_courses, courses[2]) then 1 else 0 end as c,
case when array_contains(id_courses, courses[3]) then 1 else 0 end as d,
case when array_contains(id_courses, courses[4]) then 1 else 0 end as e,
case when array_contains(id_courses, courses[5]) then 1 else 0 end as f
from id_courses;五、求月銷售額和總銷售額
1、資料說明
(1)資料格式
a,01,150
a,01,200
b,01,1000
b,01,800
c,01,250
c,01,220
b,01,6000
a,02,2000
a,02,3000
b,02,1000
b,02,1500
c,02,350
c,02,280
a,03,350
a,03,250
(2)欄位含義
店鋪,月份,金額
2、資料準備
(1)建立資料庫表t_store
use class;
create table t_store(
name string,
months int,
money int
)
row format delimited fields terminated by ",";(2)匯入資料
load data local inpath "/home/hadoop/store.txt" into table t_store;
3、需求
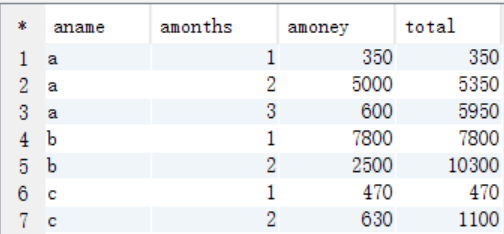
編寫Hive的HQL語句求出每個店鋪的當月銷售額和累計到當月的總銷售額
4、解析
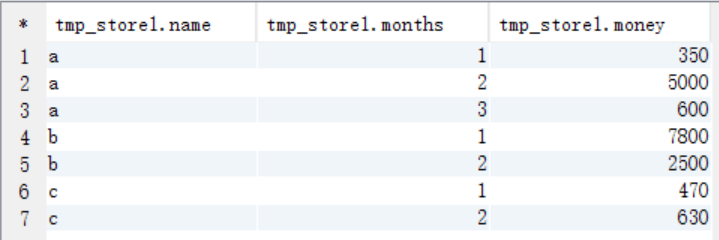
(1)按照商店名稱和月份進行分組統計
create table tmp_store1 as select name,months,sum(money) as money from t_store group by name,months; select * from tmp_store1;
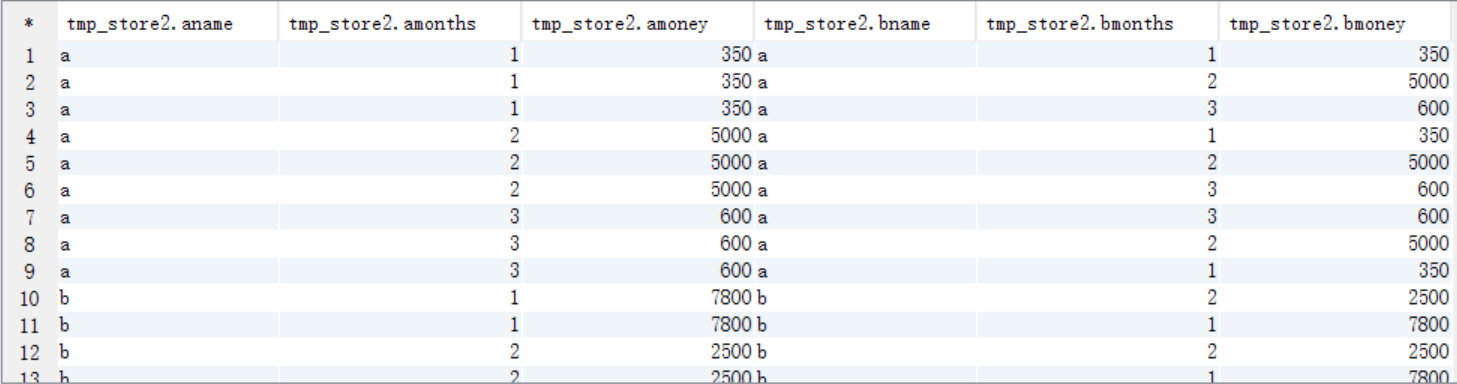
(2)對tmp_store1 表裡面的資料進行自連線
create table tmp_store2 as
select a.name aname,a.months amonths,a.money amoney,b.name bname,b.months bmonths,b.money bmoney from tmp_store1 a
join tmp_store1 b on a.name=b.name order by aname,amonths;select * from tmp_store2;
(3)比較統計
select aname,amonths,amoney,sum(bmoney) as total from tmp_store2 where amonths >= bmonths group by aname,amonths,amoney;