
爬蟲Scrapy框架的setting.py檔案詳解
-
# -*- coding: utf-8 -*- -
# Scrapy settings for demo1 project -
# -
# For simplicity, this file contains only settings considered important or -
# commonly used. You can find more settings consulting the documentation: -
# -
# http://doc.scrapy.org/en/latest/topics/settings.html -
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html -
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html -
BOT_NAME = 'demo1' #Scrapy專案的名字,這將用來構造預設 User-Agent,同時也用來log,當您使用 startproject 命令建立專案時其也被自動賦值。 -
SPIDER_MODULES = ['demo1.spiders'] #Scrapy搜尋spider的模組列表 預設: [xxx.spiders] -
NEWSPIDER_MODULE = 'demo1.spiders' #使用 genspider 命令建立新spider的模組。預設: 'xxx.spiders' -
#爬取的預設User-Agent,除非被覆蓋 -
#USER_AGENT = 'demo1 (+http://www.yourdomain.com)' -
#如果啟用,Scrapy將會採用 robots.txt策略 -
ROBOTSTXT_OBEY = True -
#Scrapy downloader 併發請求(concurrent requests)的最大值,預設: 16 -
#CONCURRENT_REQUESTS = 32 -
#為同一網站的請求配置延遲(預設值:0) -
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay -
# See also autothrottle settings and docs -
#DOWNLOAD_DELAY = 3 下載器在下載同一個網站下一個頁面前需要等待的時間,該選項可以用來限制爬取速度,減輕伺服器壓力。同時也支援小數:0.25 以秒為單位 -
#下載延遲設定只有一個有效 -
#CONCURRENT_REQUESTS_PER_DOMAIN = 16 對單個網站進行併發請求的最大值。 -
#CONCURRENT_REQUESTS_PER_IP = 16 對單個IP進行併發請求的最大值。如果非0,則忽略 CONCURRENT_REQUESTS_PER_DOMAIN 設定,使用該設定。 也就是說,併發限制將針對IP,而不是網站。該設定也影響 DOWNLOAD_DELAY: 如果 CONCURRENT_REQUESTS_PER_IP 非0,下載延遲應用在IP而不是網站上。 -
#禁用Cookie(預設情況下啟用) -
#COOKIES_ENABLED = False -
#禁用Telnet控制檯(預設啟用) -
#TELNETCONSOLE_ENABLED = False -
#覆蓋預設請求標頭: -
#DEFAULT_REQUEST_HEADERS = { -
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', -
# 'Accept-Language': 'en', -
#} -
#啟用或禁用蜘蛛中介軟體 -
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html -
#SPIDER_MIDDLEWARES = { -
# 'demo1.middlewares.Demo1SpiderMiddleware': 543, -
#} -
#啟用或禁用下載器中介軟體 -
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html -
#DOWNLOADER_MIDDLEWARES = { -
# 'demo1.middlewares.MyCustomDownloaderMiddleware': 543, -
#} -
#啟用或禁用擴充套件程式 -
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html -
#EXTENSIONS = { -
# 'scrapy.extensions.telnet.TelnetConsole': None, -
#} -
#配置專案管道 -
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html -
#ITEM_PIPELINES = { -
# 'demo1.pipelines.Demo1Pipeline': 300, -
#} -
#啟用和配置AutoThrottle擴充套件(預設情況下禁用) -
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html -
#AUTOTHROTTLE_ENABLED = True -
#初始下載延遲 -
#AUTOTHROTTLE_START_DELAY = 5 -
#在高延遲的情況下設定的最大下載延遲 -
#AUTOTHROTTLE_MAX_DELAY = 60 -
#Scrapy請求的平均數量應該並行傳送每個遠端伺服器 -
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 -
#啟用顯示所收到的每個響應的調節統計資訊: -
#AUTOTHROTTLE_DEBUG = False -
#啟用和配置HTTP快取(預設情況下禁用) -
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings -
#HTTPCACHE_ENABLED = True -
#HTTPCACHE_EXPIRATION_SECS = 0 -
#HTTPCACHE_DIR = 'httpcache' -
#HTTPCACHE_IGNORE_HTTP_CODES = [] -
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
解釋幾個引數:
ROBOTSTXT_OBEY = True -----------是否遵守robots.txt
CONCURRENT_REQUESTS = 16 -----------開啟執行緒數量,預設16
AUTOTHROTTLE_START_DELAY = 3 -----------開始下載時限速並並延遲時間
AUTOTHROTTLE_MAX_DELAY = 60 -----------高併發請求時最大延遲時間
最底下的幾個:是否啟用在本地快取,如果開啟會優先讀取本地快取,從而加快爬取速度,視情況而定
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR ='httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE ='scrapy.extensions.httpcache.FilesystemCacheStorage'
以上幾個可以視專案需要開啟,但是有兩個引數最好每次都開啟,而每次都是專案檔案手動開啟不免有些麻煩,最好是專案建立後就自動開啟
#DEFAULT_REQUEST_HEADERS = {
#'接受':'text / html,application / xhtml + xml,application / xml; q = 0.9,* / *; q = 0.8',
#'Accept-Language':'en',
#}
這個是瀏覽器請求頭,很多網站都會檢查客戶端的頭,比如豆瓣就是每一個請求都檢查頭的user_agent,否則只會返回403,可以開啟
#USER_AGENT ='Chirco(+ http://www.yourdomain.com)'
這個是至關重要的,大部分伺服器在請求快了會首先檢查User_Agent,而scrapy預設的瀏覽器頭是scrapy1.1我們需要開啟並且修改成瀏覽器頭,如:Mozilla / 5.0(Windows NT 6.1; WOW64)AppleWebKit / 537.1(KHTML,和Gecko一樣)Chrome / 22.0.1207.1 Safari / 537.1
但是最好是這個USER-AGENT會隨機自動更換最好了。
下面的程式碼可以從預先定義的使用者代理的列表中隨機選擇一個來採集不同的頁面
在settings.py中新增以下程式碼
-
DOWNLOADER_MIDDLEWARES = { -
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware' : None, -
'randoms.rotate_useragent.RotateUserAgentMiddleware' :400 -
}
rotate_useragent的程式碼為:
-
# -*- coding: utf-8 -*- -
import random -
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware -
class RotateUserAgentMiddleware(UserAgentMiddleware): -
def __init__(self, user_agent=''): -
self.user_agent = user_agent -
def process_request(self, request, spider): -
#這句話用於隨機選擇user-agent -
ua = random.choice(self.user_agent_list) -
if ua: -
print('User-Agent:'+ua) -
request.headers.setdefault('User-Agent', ua) -
#the default user_agent_list composes chrome,I E,firefox,Mozilla,opera,netscape -
user_agent_list = [\ -
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"\ -
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",\ -
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",\ -
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",\ -
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",\ -
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",\ -
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",\ -
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\ -
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\ -
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\ -
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\ -
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\ -
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\ -
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\ -
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\ -
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",\ -
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",\ -
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" -
]
執行爬蟲可以看到資訊:
-
2017-04-16 00:07:40 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023 -
User-Agent:Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3 -
2017-04-16 00:07:40 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET http://www.jianshu.com/robots.txt> from <GET http://jianshu.com/robots.txt> -
User-Agent:Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1 -
2017-04-16 00:07:41 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.jianshu.com/robots.txt> (referer: None) -
User-Agent:Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24 -
2017-04-16 00:07:41 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET http://www.jianshu.com/> from <GET http://jianshu.com/> -
User-Agent:Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3
也可以把user_agent_list放到設定檔案中去:
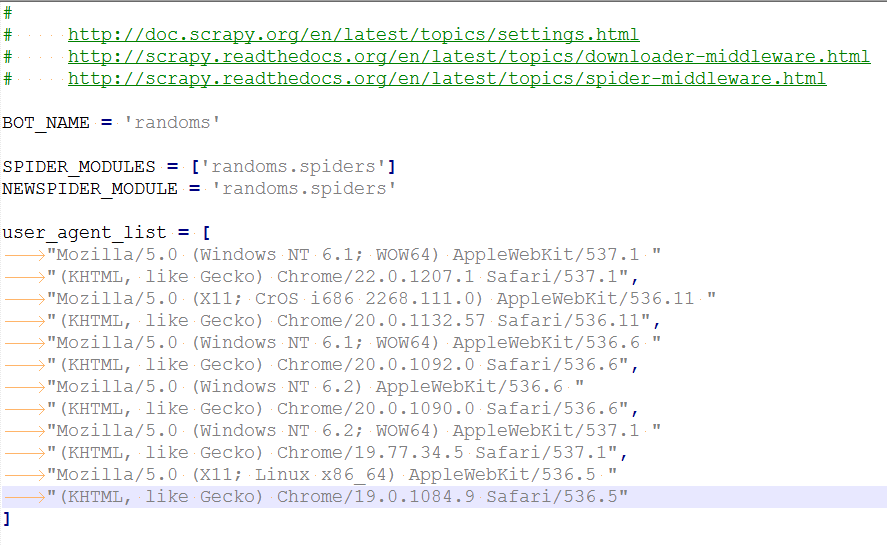
在rotate_useragent檔案中加入一行程式碼
from randoms.settings import user_agent_list執行效果如下:
