
Python資料分析----Python3操作Excel-以豆瓣圖書Top250為例
本文利用Python3爬蟲抓取豆瓣圖書Top250,並利用xlwt模組將其儲存至excel檔案,圖片下載到相應目錄。旨在進行更多的爬蟲實踐練習以及模組學習。
工具
1.Python 3.5
2.BeautifulSoup、xlwt模組
開始動手
首先檢視目標網頁的url: https://book.douban.com/top250?start=0, 然後我嘗試了在程式碼裡直接通過字串連線僅改變”start=“後面的數字的方法來遍歷所有的250/25 = 10頁內容,但是後來發現不行,那樣的話出來的永遠是第一頁,於是通過瀏覽器的F12開發者工具檢查,發現start是要post上去的,如下圖:
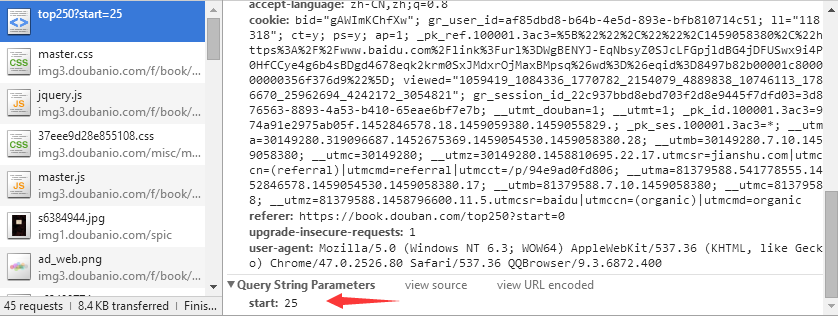 (圖1)
(圖1)
所以建立一個postData的dict:
| 1 |
|
每次將其post上去即可解決返回都是第一頁的問題。
分析網頁可知,一本書的羅列資訊以及要爬取的點如下圖:
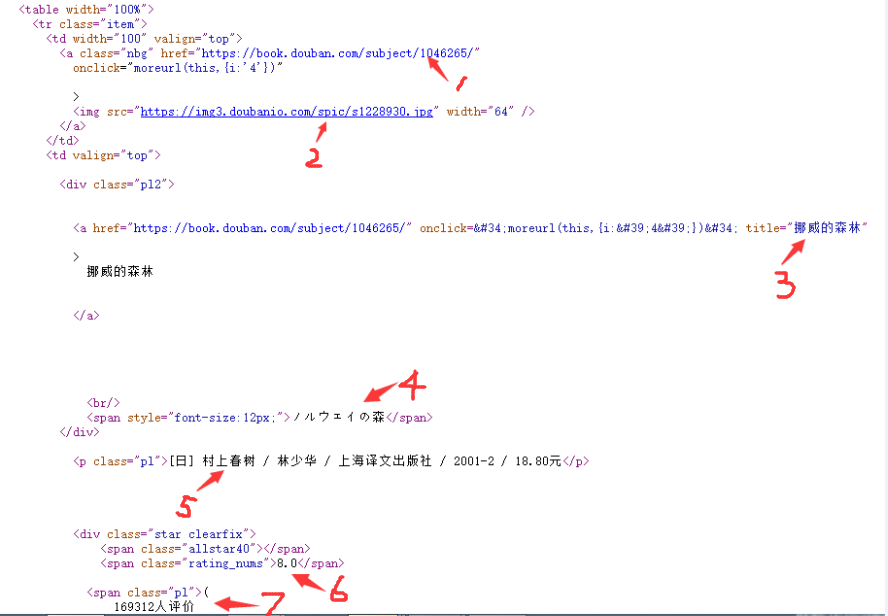 (圖2)
(圖2)
從上到下需要爬取的資訊有:
1.圖書連結地址
2.封面圖片連結 我到時候會將此連結開啟,下載圖片到本地 (download_img函式)
3.書名 要注意的是這裡書名取title的內容而不去a標籤中的string資訊,因為string資訊可能包含諸如空格、換行符之類的字元,給處理造成麻煩,直接取title格式正確且無需額外處理。
4.別名 這裡主要是副標題或者是外文名,有的書沒有這項,那麼我們就寫入一個“無”,千萬不可以寫入一個空串,否則的話會出現故障,我下面會提到。
5.出版資訊 如作者、譯者、出版社、出版年份、價格, 這也是重要資訊之一,否則有多本書名字一致可能會無法分辨
6.評分
7.評價人數
除此之外,我還爬取一個“標籤”資訊,它在圖書連結開啟之後的網頁中,找到它的位置如下:
 (圖3)
(圖3)
爬到標籤以後將它們用逗號連線起來作為標籤值。
好了,既然明確了要爬的指標,以及瞭解了網頁結構以及指標所在的html中的位置,那麼就可以寫出如下程式碼:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
|
通過xlwt模組存入xls檔案及其問題
爬取下來了以後當然要考慮儲存,這時我想試試把它存到Excel檔案(.xls)中,於是搜得python操作excel可以使用xlwt,xlrd模組,雖然他們暫時只支援到excel2003,但是足夠了。xlwt為Python生成.xls檔案的模組,而xlrd為讀取的。由於我想的是直接生成xls檔案,不需用到xlrd,所以先安裝xlwt。
直接進入Python目錄使用如下命令即可安裝xlwt:
| 1 |
|
安裝完後寫出操作程式碼,這裡同時也寫入txt檔案,方便比較:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
滿以為這樣就可以了,但是還是出現了一些錯誤。
比如曾經出現了寫著寫著就寫不下去了的情況(以下並非以上程式碼產生的結果):
 (圖4)
(圖4)
這時我把不是str的都改成str了,不該str的儘量用數字(int,float),然後又遇到了下面的情況:
 (圖5)
(圖5)
寫到第64項又寫不下去了,但是那些int,float都寫完了,‘無’也是斷斷續續顯示幾個,我想,既然找不到問題,那麼慢慢套吧。首先極大可能是中文編碼的問題,因為我把一些可以不為str型別的都賦成非str型別以後都正確地顯示了,而且上圖中的顯示在圖片路徑名那裡斷了,所以我讓那一列都不顯示,居然,成功了!
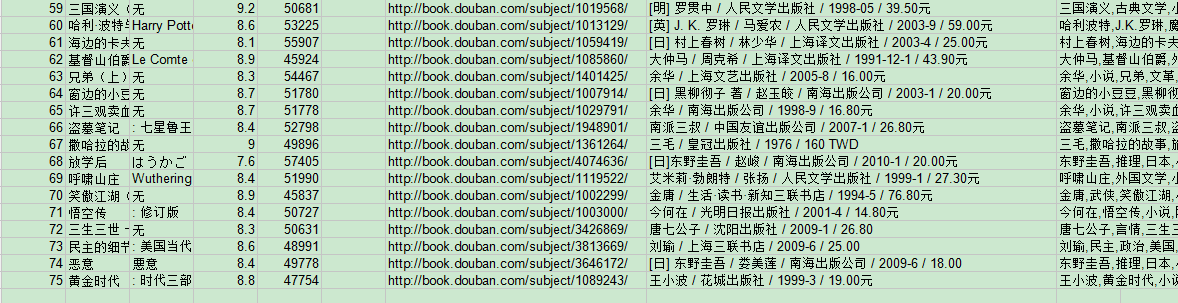 (圖6)
(圖6)
如圖,除了不顯示的那一列,其它完全正常,可以斷定就是下面這裡出現的錯誤:
| 1 |
|
我的圖片路徑那裡是直接字串拼接而成的,所以可能會有編碼的錯誤。那麼稍微改一下試試:
| 1 2 |
|
好吧,還是不行,還是出現圖5的問題,但是列印在Python IDLE裡面又都是正確的。
既然如此,把圖片連結全部改成一樣的英文試一下:
| 1 2 |
|
又是正確的:('無'已改為'None')
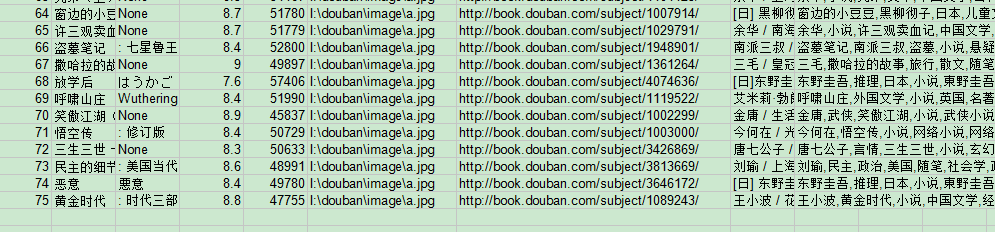 (圖7)
(圖7)
所以說,還是圖片路徑的問題,那我們索性將圖片路徑那列換成圖片連結,採取消極應對方法,反正這項是圖片連結還是圖片路徑無關緊要,反正圖片路徑裡面有圖片就可以了。此外我還加了一個計時的程式碼,計算總爬取時間,因為我覺得這樣幹爬太慢了,沒有個將近10分鐘完不成,考慮利用多執行緒去爬,這裡先記錄一下時間以觀後效。然後發現還是不行!現在成了只要imageurl固定(中文也行),就能夠順利輸出到xls中,否則就不行。很詭異。於是我又嘗試了縮短imageurl,實驗得知,當取imageurl[:-6]時是可以的,但imageurl[:-5]就不行了。後面又幹脆不寫入imageurl這一列,可以,不寫入別名或者不寫入圖書連結都是正常的,但是不寫入標號就不行。至今仍不得解。初步猜測莫非是寫入的字元數受限制了?還得靠更多的實驗才能確定。而且也說不定就是Windows下的編碼問題,這又得靠在Linux下進行實驗判斷。所以要做的事情還很多,這裡先把正確的絕大部分工作做了再說。
於是乾脆不要圖書地址一列,最後得出如下最終程式碼:
 View Code
View Code
執行(7分多鐘):
 (圖8)
(圖8)
還是斷了,那就真不知道怎麼辦才好了。再改變方法,先寫到TXT文字檔案再匯入到xls中,就先不管本文標題了。
執行:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
在.txt中是正確的:
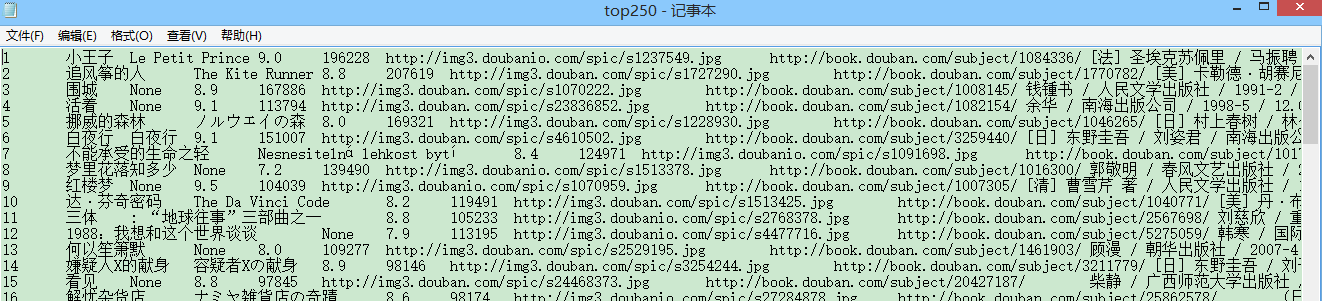 (圖9)
(圖9)
然後在xls檔案中選擇資料->匯入資料即可得到最終結果:
 (圖10)
(圖10)
封面圖片:
 (圖11)
(圖11)
問題先解決到這,後面的問題有待深入研究。
後期可改進
1.採用多程序/多執行緒加快爬取速度
2.可考慮採用xlutis模組分多步寫入到excel中
3.可考慮改換excel處理模組
3.考慮在Linux環境下進行試驗