
python複習筆記(四)
此筆記摘錄於廖雪峰先生的教程,感謝廖先生的無私分享,特此致敬!
字串和編碼
字元編碼
-
字串也是一種資料型別,但是,字串比較特殊的是還有一個編碼問題。
-
因為計算機只能處理數字,如果要處理文字,就必須先把文字轉換為數字才能處理。最早的計算機在設計時採用8個位元(bit)作為一個位元組(byte),所以,一個位元組能表示的最大的整數就是255(二進位制11111111=十進位制255),如果要表示更大的整數,就必須用更多的位元組。
-
ASCII編碼和Unicode編碼的區別
- ASCII編碼是1個位元組,而Unicode編碼通常是2個位元組。
- 字母A用ASCII編碼是十進位制的65,二進位制的01000001。
- 字元0用ASCII編碼是十進位制的48,二進位制的00110000,字元’0’和整數0是不同的。
- 漢字中已經超出了ASCII編碼的範圍,用Unicode編碼是十進位制的20013,二進位制的01001110 00101101。
- 如果把ASCII編碼的A用Unicode編碼,只需要在前面補0就可以,因此,A的Unicode編碼是00000000 01000001。
- ASCII編碼是1個位元組,而Unicode編碼通常是2個位元組。
-
UTF-8編碼把一個Unicode字元根據不同的數字大小編碼成1-6個位元組,常用的英文字母被編碼成1個位元組,漢字通常是3個位元組,只有很生僻的字元才會被編碼成4-6個位元組。如果你要傳輸的文字包含大量英文字元,用UTF-8編碼就能節省空間。UTF-8編碼有一個額外的好處,就是ASCII編碼實際上可以被看成是UTF-8編碼的一部分,所以,大量只支援ASCII編碼的歷史遺留軟體可以在UTF-8編碼下繼續工作。
-
現在計算機系統通用的字元編碼工作方式:
- 在計算機記憶體中,統一使用Unicode編碼,當需要儲存到硬碟或者需要傳輸的時候,就轉換為UTF-8編碼。
- 用記事本編輯的時候,從檔案讀取的UTF-8字元被轉換為Unicode字元到記憶體裡,編輯完成後,儲存的時候再把Unicode轉換為UTF-8儲存到檔案。
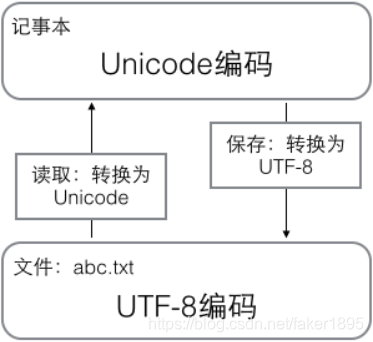
-
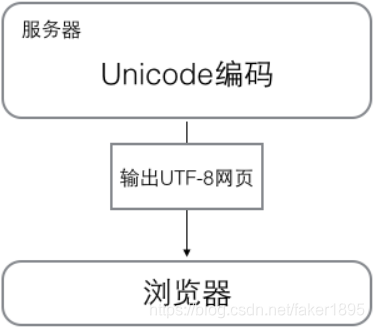
瀏覽網頁的時候,伺服器會把動態生成的Unicode內容轉換為UTF-8再傳輸到瀏覽器,所以你看到很多網頁的原始碼上會有類似的資訊,表示該網頁正是用的UTF-8編碼。
Python的字串
-
在最新的Python 3版本中,字串是以Unicode編碼的,也就是說,Python的字串支援多語言。
-
對於單個字元的編碼,Python提供了ord()函式獲取字元的整數表示,chr()函式把編碼轉換為對應的字元。
>>> ord('A')
65
>>> ord('中')
20013
>>> chr(66)
'B'
>>> chr(25991)
'文'
-
由於Python的字串型別是str,在記憶體中以Unicode表示,一個字元對應若干個位元組。如果要在網路上傳輸,或者儲存到磁碟上,就需要把str變為以位元組為單位的bytes,Python對bytes型別的資料用帶b字首的單引號或雙引號表示。
-
純英文的str可以用ASCII編碼為bytes,內容是一樣的,含有中文的str可以用UTF-8編碼為bytes。含有中文的str無法用ASCII編碼,因為中文編碼的範圍超過了ASCII編碼的範圍,Python會報錯。在bytes中,無法顯示為ASCII字元的位元組,用\x##顯示。
-
如果我們從網路或磁碟上讀取了位元組流,那麼讀到的資料就是bytes。要把bytes變為str,就需要用decode()方法。
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
- 如果bytes中包含無法解碼的位元組,decode()方法會報錯。
>>> b'\xe4\xb8\xad\xff'.decode('utf-8')
Traceback (most recent call last):
...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3: invalid start byte
- 如果bytes中只有一小部分無效的位元組,可以傳入errors='ignore’忽略錯誤的位元組。
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'
- 要計算str包含多少個字元,可以用len()函式,len()函式計算的是str的字元數,如果換成bytes,len()函式就計算位元組數。
>>> len('ABC')
3
>>> len('中文')
2
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6
-
在操作字串時,我們經常遇到str和bytes的互相轉換。為了避免亂碼問題,應當始終堅持使用UTF-8編碼對str和bytes進行轉換。
-
由於Python原始碼也是一個文字檔案,所以,當你的原始碼中包含中文的時候,在儲存原始碼時,就需要務必指定儲存為UTF-8編碼。
- 當Python直譯器讀取原始碼時,為了讓它按UTF-8編碼讀取,我們通常在檔案開頭寫上這兩行:
- 第一行註釋是為了告訴Linux/OS X系統,這是一個Python可執行程式,Windows系統會忽略這個註釋;
- 第二行註釋是為了告訴Python直譯器,按照UTF-8編碼讀取原始碼,否則,你在原始碼中寫的中文輸出可能會有亂碼。
#!/usr/bin/env python3 # -*- coding: utf-8 -*-
格式化
- 在Python中,採用的格式化方式和C語言是一致的,用%實現,在字串內部,%s表示用字串替換,%d表示用整數替換,有幾個%?佔位符,後面就跟幾個變數或者值,順序要對應好。如果只有一個%?,括號可以省略。
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
-
常見的佔位符
- %d:整數。
- %f :浮點數。
- %s:字串。
- %x:十六進位制整數。
- 格式化整數和浮點數還可以指定是否補0和整數與小數的位數。
-
如果你不太確定應該用什麼,%s永遠起作用,它會把任何資料型別轉換為字串。
-
有些時候,字串裡面的%是一個普通字元怎麼辦?這個時候就需要轉義,用%%來表示一個%。