
python3之lxml、css和xpath
文章目錄
頁面解析lxml
lxml是python的一個解析庫,支援HTML和XML的解析,支援XPath解析方式,而且解析效率非常高
XPath,全稱XML Path Language,即XML路徑語言,它是一門在XML文件中查詢資訊的語言,它最初是用來搜尋XML文件的,但是它同樣適用於HTML文件的搜尋。
XPath的選擇功能十分強大,它提供了非常簡明的路徑選擇表示式,另外,它還提供了超過100個內建函式,用於字串、數值、時間的匹配以及節點、序列的處理等,幾乎所有我們想要定位的節點,都可以用XPath來選擇。
XPath於1999年11月16日成為W3C標準,它被設計為供XSLT、XPointer以及其他XML解析軟體使用,更多的文件可以訪問其官方網站:
lxml自動修復標籤屬性兩側缺失的引號,並閉合標籤。
處理非標準的html
import lxml.html
broben_html = "<ul class=country> <li>Area <li id=aa>Population</ul>"
tree = lxml.html.fromstring(broben_html)
print('tree type:', type(tree))
# pretty_print: 優化輸出,輸出換行符
# fixed_html = lxml.html.tostring(tree, pretty_print=True) '''
lxml提供如下方式輸入文字:
fromstring():解析字串
HTML():解析HTML物件
XML():解析XML物件
parse():解析檔案型別物件
'''
# 輸出就是前面講的tostring()方法:
>>> root = etree.XML('<root><a><b/></a></root>')
>>> etree.tostring(root)
'<root><a><b/></a></root>'
>>> etree.tostring(root,xml_declaration=True)
"<?xml version='1.0' encoding='ASCII'?>\n<root><a><b/></a></root>"
>>> etree.tostring(root,xml_declaration=True,encoding='utf-8')
"<?xml version='1.0' encoding='utf-8'?>\n<root><a><b/></a></root>"
css
解析完輸入內容之後,進入選擇元素的步驟,此時lxml有幾種不同的方法,比如 XPath 選擇器和類似 Beautiful Soup 的find()方法 。我們將會使用 css 選擇器 , 因為它更加簡沽。
安裝cssselect:pip install cssselect
常用的選擇器示例
選擇所有標籤 :*
選擇<a>標籤:a
選擇所有 class="link"的元素: .link
選擇class="link" 的 <a>標籤: a.link
選擇 id= "home" 的 <a>標籤: a#home
選擇父元素為 <a>標籤的所有 <span>子標籤: a > span
選擇<a>標籤內部的所有 <span>標籤: a span
選擇 title 屬性為 "Home" 的所有<a>標籤: a[title=Home]

栗子
import lxml.html
import requests
from fake_useragent import UserAgent
ua = UserAgent()
header = {
"User-Agent": ua.random
}
html = requests.get("http://www.baidu.com/", headers=header)
html = html.content.decode("utf8")
print(html)
tree = lxml.html.fromstring(html)
mnav = tree.cssselect('div#head .mnav')
# 輸出文字內容
# area = td.text_content()
for i in mnav:
print(i.text)
結果如下:
新聞
hao123
地圖
視訊
貼吧
學術
ps: 不知為何使用html.text輸出的是亂碼。
xpath
常用規則
| 表示式 | 描述 |
|---|---|
| nodename | 選取此節點的所有子節點 |
| / | 從當前節點選取直接子節點 |
| // | 從當前節點選取子孫節點 |
| . | 選取當前節點 |
| … | 選取當前節點的父節點 |
| @ | @用來選取屬性 |
| * | 萬用字元,匹配元素節點 |
| @* | 匹配任何屬性節點 |
| [@attrib] | 選取具有給定屬性的所有節點 |
| [@attrib=‘value’] | 選取具有給定值屬性的所有節點 |
謂語
謂語用來查詢某個特定的節點或者包含某個指定的值的節點。謂語被嵌在方括號中。
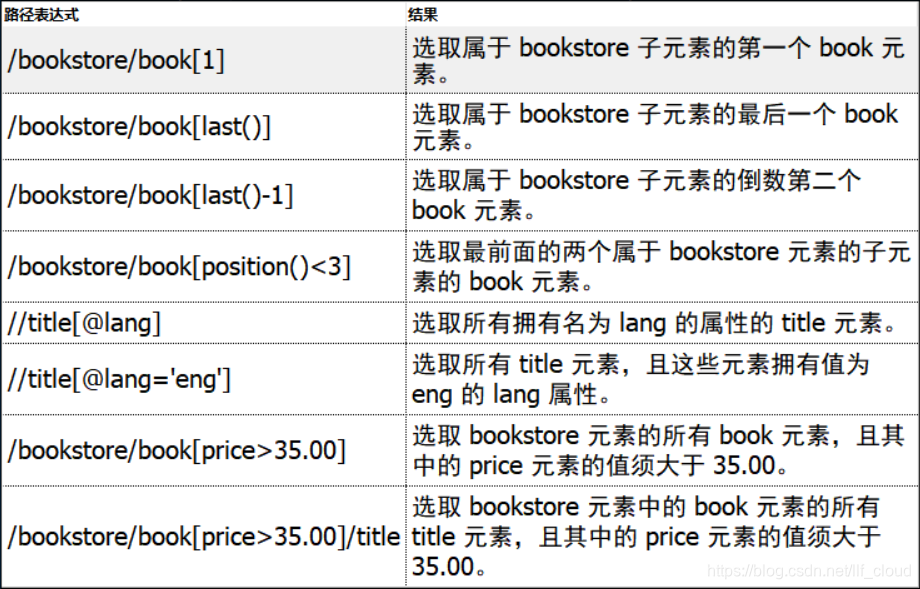
運算子

常用函式

栗子
- 解析字串型別的html
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
result = etree.tostring(html)
print(result)
# 最後一個li標籤不完整,會自動補全
- 解析檔案型別的html,獲取所有的 li標籤
from lxml import etree
from lxml.etree import HTMLParser
html=etree.parse(‘test.html’, etree.HTMLParser()) # 指定解析器HTMLParser會根據檔案修復HTML檔案中缺失的如宣告資訊
result=etree.tostring(html) # 解析成位元組
result=etree.tostringlist(html) # 解析成列表
from lxml import etree
html = etree.parse('hello.html')
print type(html)
result = html.xpath('//li')
print result
print len(result)
print type(result)
print type(result[0])
# 解釋:etree.parse 的型別是 ElementTree,通過呼叫 xpath 以後,
# 得到了一個列表,包含了 5 個 <li> 元素,每個元素都是 Element 型別
- 獲取標籤名
# 獲取 class 為 bold 的標籤名
result = html.xpath('//*[@class="bold"]')
print(result[0].tag)
- 獲取標籤的屬性
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/@class')
print(result) # 返回li標籤的class屬性的值
- 獲取li標籤下 href屬性 為 link1.html 的a標籤
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/a[@href="link1.html"]')
print(result)
- 獲取標籤下的子標籤或子孫標籤
from lxml import etree
html = etree.parse('hello.html')
# 注意這麼寫是不對的,因為 / 是用來獲取子元素的,而 <span> 並不是 <li> 的子元素,所以,要用雙斜槓
# result = html.xpath('//li/span') # 獲取li標籤下為span的子節點
result = html.xpath('//li//span') # 獲取li標籤下為span的子孫節點
print(result)
- 提取文字內容
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li//span/text()') # 獲取span標籤的內容
print(result)
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
nodeList = html.xpath('//a[contains(text(), "first")]/text()')
print(nodeList)
擴充套件:
#方法1:過濾標籤,返回全部文字
>>> root.xpath('string()')
'child1 testchild2 test'
#方法2:以標籤為間隔,返回list
>>> root.xpath('//text()')
['child1 test', 'child2 test', '123']