Hbase特性介紹
1、什麼是Hbase。
是一個高可靠性、高效能、列儲存、可伸縮、實時讀寫的分散式資料庫系統。
適合於儲存非結構化資料,基於列的而不是基於行的模式
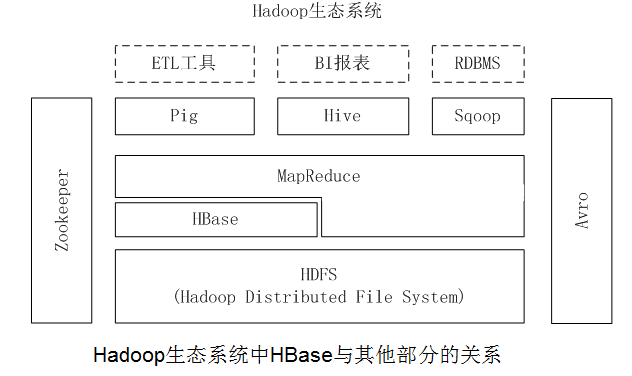
如圖:Hadoop生態中HBase與其他部分的關係。
2、關係資料庫已經流行很多年,並且Hadoop已經有了HDFS和MapReduce,為什麼需要HBase?
Hadoop可以很好地解決大規模資料的離線批量處理問題,但是,受限於HadoopMapReduce程式設計框架的高延遲資料處理機制,使得Hadoop無法滿足大規模資料實時處理應用的需求
HDFS面向批量訪問模式,不是隨機訪問模式
傳統的通用關係型資料庫無法應對在資料規模劇增時導致的系統擴充套件性和效能問題(分庫分表也不能很好解決)
傳統關係資料庫在資料結構變化時一般需要停機維護;空列浪費儲存空間
因此,業界出現了一類面向半結構化資料儲存和處理的高可擴充套件、低寫入/查詢延遲的系統,例如,鍵值資料庫、文件資料庫和列族資料庫(如BigTable和HBase等)
HBase已經成功應用於網際網路服務領域和傳統行業的眾多線上式資料分析處理系統中
3、HBase與傳統的關係資料庫的區別
(1)資料型別:關係資料庫採用關係模型,具有豐富的資料型別和儲存方式,HBase則採用了更加簡單的資料模型,它把資料儲存為未經解釋的字串
(2)資料操作:關係資料庫中包含了豐富的操作,其中會涉及複雜的多表連線。HBase操作則不存在複雜的表與表之間的關係,只有簡單的插入、查詢、刪除、清空等,因為HBase在設計上就避免了複雜的表和表之間的關係
(3)儲存模式:關係資料庫是基於行模式儲存的。HBase是基於列儲存的,每個列族都由幾個檔案儲存,不同列族的檔案是分離的
(4)資料索引:關係資料庫通常可以針對不同列構建複雜的多個索引,以提高資料訪問效能。HBase只有一個索引——行鍵,通過巧妙的設計,HBase中的所有訪問方法,或者通過行鍵訪問,或者通過行鍵掃描,從而使得整個系統不會慢下來
(5)資料維護:在關係資料庫中,更新操作會用最新的當前值去替換記錄中原來的舊值,舊值被覆蓋後就不會存在。而在HBase中執行更新操作時,並不會刪除資料舊的版本,而是生成一個新的版本,舊有的版本仍然保留
(6)可伸縮性:關係資料庫很難實現橫向擴充套件,縱向擴充套件的空間也比較有限。相反,HBase和BigTable這些分散式資料庫就是為了實現靈活的水平擴充套件而開發的,能夠輕易地通過在叢集中增加或者減少硬體數量來實現效能的伸縮
二、Hbase資料模型
1、模型概述
HBase是一個稀疏、多維度、排序的對映表,這張表的索引是行鍵、列族、列限定符和時間戳
每個值是一個未經解釋的字串,沒有資料型別
使用者在表中儲存資料,每一行都有一個可排序的行鍵和任意多的列
表在水平方向由一個或者多個列族組成,一個列族中可以包含任意多個列,同一個列族裡面的資料儲存在一起
列族支援動態擴充套件,可以很輕鬆地新增一個列族或列,無需預先定義列的數量以及型別,所有列均以字串形式儲存,使用者需要自行進行資料型別轉換
HBase中執行更新操作時,並不會刪除資料舊的版本,而是生成一個新的版本,舊有的版本仍然保留(這是和HDFS只允許追加不允許修改的特性相關的)
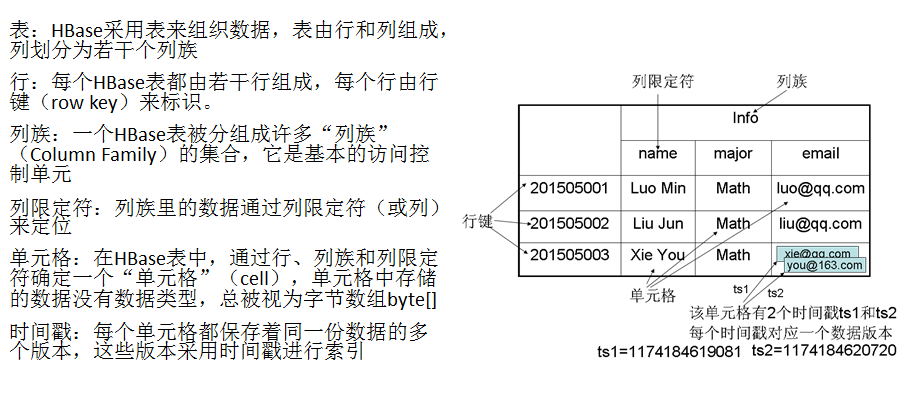
2、資料座標
HBase中需要根據行鍵、列族、列限定符和時間戳來確定一個單元格,因此,可以視為一個“四維座標”,即[行鍵,列族, 列限定符,時間戳]
| 鍵 |
值 |
| [“201505003”,“Info”,“email”, 1174184619081] |
|
| [“201505003”,“Info”,“email”, 1174184620720] |
|
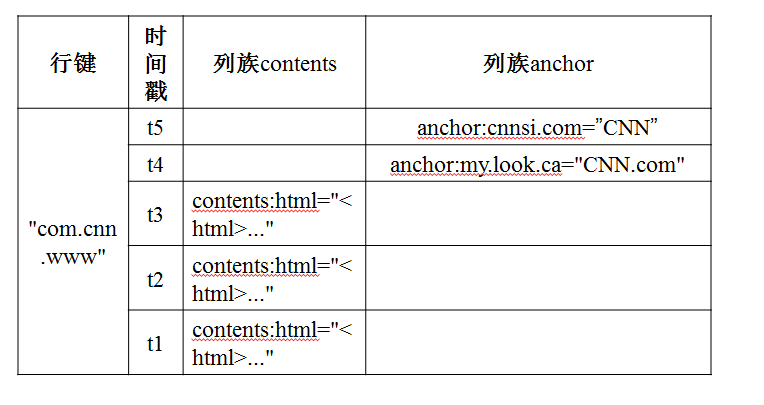
3、概念檢視

4、物理檢視