
字元和字串處理(1)
2.1 字符集及字元編碼(字符集——字元的集合,不同的字符集,收錄的字元可能不同)
2.1.1多位元組字符集及ANSI編碼標準
(1)單位元組編碼:ASCII字符集及擴充套件——滿足英語及西歐語言的需要
(2)雙位元組編碼:——滿足亞洲等國家語言文字的需要,如:
| 字元編碼及 內碼表 |
第1位元組 (前導位元組Lead Byte及最高位) |
第2位元組 尾隨位元組Trailing Byte及最高位 |
字元數 |
說明 |
| GB2312 (1980) |
A1…F7(1) |
A1…FE(0) |
7445 |
簡體字符集(基於區位碼設計,高低位元組各加了0xA0) |
| Big5 (1984,CP950) |
81…FE(1) |
40..7E(0) A1…FE(1) |
13461 |
繁體字符集(港、澳、臺等地) |
| GBK1.0 (1993,CP936) |
81…FE(1) 共126張碼錶 |
40…FE(0) 80…FE(1) |
21886 |
相容GB2312,支援Unicode1.1中定義的CJK(中、日、韓語) |
| GB18030 (2000,CP54936) |
|
|
27484 |
相容GBK1.0支援Unicode3.1有單位元組、雙位元組和四位元組3種 |
①內碼表(Code Page, CP):實際上是Windows為不同的字元編碼方案所分配的一個數字編號。 對Windows 使用者而言,總共會使用兩個內碼表。使用 Windows 圖形使用者介面的應用程式使用 Windows 內碼表。Windows 內碼表與 ISO 字符集相容,也與 ANSI 字符集相容。它們通常稱為 ANSI 內碼表。Windows 中的字元模式的應用程式(使用命令提示符視窗的應用程式)使用過去在 DOS 中使用的內碼表。由於歷史原因,這些內碼表稱為 OEM(原始裝置製造商)內碼表(注意:內碼表是相對於ANSI編碼而言的)
②CP936對GBK字符集的編解碼。
在解析位元組流的時候,如果遇到位元組的最高位是0的話,那麼就使用936內碼表中的第1張碼錶進行解碼,這就和單位元組字符集的編解碼方式一致了。當位元組的高位是1的時候,確切的說,當第1個位元組位於0x81–0xFE之間時,根據第1個位元組不同找到內碼表中的相應的碼錶。如編碼“BA BA D7 D6 41 42 43”在簡體中文環境下(GBK,CP936)下被對映成“漢字ABC”。其對應的碼錶分別為第BA張、第D7張、第1張(ASCII碼錶),見下圖(其中41、42、43即ASCII表的ABC,為簡便,此處省略ACII碼錶)

同樣的編碼,在繁體中文 (Big5, CP950),它就變成了“犖趼ABC”。如果選擇ISO8859-1內碼表的話,那我們會看到“ooó?ABC”。
(3)ANSI編碼的特點——本地化編碼
由於每個國家便針對本國的字符集指定了相應的字元編碼標準,如GB2312、BIG5、JIS等僅適用於本國字符集的編碼標準。這些字元編碼標準統稱為ANSI編碼標準,他們有一些共同的特點:
①每種ANSI字符集只規定自己國家或地區使用的語言所需的“字元”;比如簡體中文編碼標準GB-2312的字符集中就不會包含韓國人的文字。
②ANSI字符集的空間都比ASCII要大很多,一個位元組已經不夠,絕大多數ANSI編碼標準都使用多個位元組來表示一個字元。這樣的編碼系統通常用簡單的查表,也就是通過內碼表就可以直接將字元對映為儲存裝置上的位元組流了。(如“我”的GBK編碼為0xCED2,儲存時也是0xCED2這樣的位元組流(這裡暫時不慮大小端))
③ANSI編碼標準一般都會相容ASCII碼。
④我們現在通常說到ANSI編碼,通常指的是平臺的預設編碼,例如對於英文檔案是ASCII編碼,對於簡體中文檔案是GB2312編碼(只針對Windows簡體中文版,如果是繁體中文版會採用Big5碼),在日文作業系統下,ANSI 編碼代表 JIS 編碼,其他語言的系統的情況類似。
⑤無法解決在一份文件中顯示所有字元的問題,因為每次只能以一種編碼開啟一份檔案。
2.1.2 Unicode字符集及UTF-X等編碼——國際化編碼
(1)Unicode簡介
①Unicode字符集涵蓋了目前人類使用的所有字元,併為每個字元進行統一編號,分配唯一的字元碼(Code Point),也稱為Unicode碼。Unicode字符集將所有字元按照使用上的頻繁度劃分為17個層面(Plane),每個層面上有216=65536個字元碼空間。

②BMP(平面 0)的 Unicode 編碼的佈局

注意:中日韓文(CJK)字元的範圍一般從U+4E00…U+9FA5,具體如下圖所示
| UNICODE碼 |
GB18030-2005 |
| 0x4E00-0x9FA5 |
CJK統一漢字的20902漢字 |
| 0x3400-0x4DB5 |
CJK統一漢字擴充A的6582漢字 |
| 0x20000-0x2A6D6 |
CJK統一漢字擴充B的42711漢字 |
| 2E81, 2E84, 2E88, 2E8B, 2E8C, 2E97, 2EA7, 2EAA, 2EAE, 2EB3, 2EB6, 2EB7, 2EBB, 2ECA |
CJK部首補充區的14個部首 |
| F92C, F979, F995, F9E7, F9F1, FA0C, FA0D, FA0E, FA0F, FA11, FA13, FA14, FA18, FA1F, FA20, FA21, FA23, FA24, FA27, FA28, FA29 |
CJK相容漢字區的21個漢字 |
| 0x9FB4-0x9FBB |
CJK統一漢字區新增了這8個字元 |
③雖然每個字元在Unicode字符集中都能找到唯一確定的編號(字元碼,又稱Unicode碼),他是字元和數字之間的對映,即每個字元對映到唯一的一個Unicode碼,一般採用16進位制加上字首U+來表示, 如:A的碼位是U+0041。但是決定最終位元組流的卻是具體的字元編碼(這一點與ANSI編碼是不同的!)。例如同樣是對Unicode字元“A”進行編碼,UTF-8字元編碼得到的位元組流是0x41,而UTF-16(大端模式)得到的是0x00 0x41。
(2)常見的Unicode編碼
①UTF-8編碼——變長編碼,是以位元組為編碼單元,沒有位元組序的問題
| Unicode碼 (CodePoint)範圍 |
UTF-8編碼(二進位制) |
備註 |
| U+0000 – U+007F |
0xxxxxxx |
首位元組前置1的數目代表正確解析所需要的位元組數,剩餘位元組的高2位始終是10。例如首位元組是1110yyyy,前置有3個1,說明正確解析總共需要3個位元組,需要和後面2個以10開頭的位元組結合才能正確解析得到字元。 |
| U+0080 – U+07FF |
110xxxxx 10xxxxxx |
|
| U+0800 – U+FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
|
| U+10000 - U+1FFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
★“漢”字U+6C49用二進位制表示是:0110 1100 0100 1001,對應U+0800 – U+0FFFF區間,將這些二進位制位放入對應的位置後就變成了:11100110 10110001 10001001,再將其轉換成十六進位制是E6 B1 89。
★由上分析可見ASCII字母繼續使用1位元組儲存,重音文字、希臘字母或西裡爾字母等使用2位元組來儲存,而常用的漢字就要使用3位元組。輔助平面字元則使用4位元組。
②UTF-16編碼方式——在WindowsVista以上的版本上,每個Unicode都是採用這種編碼
UTF-16是Unicode字符集的一種轉換方式,即把Unicode的碼位轉換為16位元長的碼元序列,以用於資料儲存或傳遞。
A、從U+0000至U+D7FF以及從U+E000至U+FFFF的碼位
第一個Unicode平面(BMP),碼位從U+0000至U+FFFF(除去代理區),包含了最常用的字元。UTF-16與其CodePoint(Unicode碼)在數值是等價的。
B、從U+D800到U+DFFF的碼位(代理區)
因為Unicode字符集的編碼值範圍為0-0x10FFFF,而大於等於0x10000的輔助平面區的編碼值無法用2個位元組來表示,所以Unicode標準規定:基本多語言平面內,U+D800..U+DFFF的值不對應於任何字元,為代理區。因此,UTF-16利用保留下來的0xD800-0xDFFF區段的碼位來對輔助平面的字元的碼位進行編碼。
C、從U+10000到U+10FFFF的碼位——(不常用,略)
③UTF-32:又稱為UCS-4,它固定使用32 bits(四個位元組)來表示一個字元。
(3)位元組序及BOM——不同編碼下將字串"漢字ABC"儲存到Text檔案後在記憶體中的表示
| 編碼形式 |
編碼結果(含BOM)(記憶體從低到高地址) |
| UTF-8 |
EF BB BF E6 B1 89 E8 AF AD 41 42 43 |
| UTF-16 LE |
FF FE 49 6C 57 5B 41 00 42 00 43 00 (低位元組低地址,高位元組高地址) |
| UTF-16 BE |
FE FF 6C 49 5B 57 00 41 00 42 00 43 |
| UTF-32 LE |
FF FE 00 00 49 6C 00 00 57 5B 00 00 41 00 00 00 42 00 00 00 43 00 00 00 |
| UTF-32 BE |
00 00 FE FF 00 00 6C 49 00 00 5B 57 00 00 00 41 00 00 00 42 00 00 00 43 |
(說明:“漢”—U+0x6C49,“字”-U+0x5B57)
2.1.3 Locale和ANSI內碼表
(1)Locale和LCID
Locale是指特定於某個國家或地區的一組設定,包括字符集,數字、貨幣、時間和日期的格式等。在Windows中,每個Locale可以用一個32位數字表示,記作LCID。在winnt.h中可以看到LCID的組成。它的高16位表示字元的排序方法,一般為0。在它的低16位中,低10位是primary language的ID,高4位指定sublanguage。sublanguage被用來區分同一種語言的不同編碼。下面是部分primary language和sublanguage的常數定義:
#define LANG_CHINESE 0x04
#define LANG_ENGLISH 0x09
#define LANG_FRENCH 0x0c
#define LANG_GERMAN 0x07
#define SUBLANG_CHINESE_TRADITIONAL 0x01 // Chinese (Taiwan Region)
#define SUBLANG_CHINESE_SIMPLIFIED 0x02 // Chinese (PR China)
#define SUBLANG_ENGLISH_US 0x01 // English (USA)
#define SUBLANG_ENGLISH_UK 0x02 // English (UK)
好,現在我們可以計算簡體中文的LCID了,將sublanguage的常數左移10位,即乘上1024,再加上primary language的常數:2*1024+4=2052,16進位制是0804。美國英語是:1*1024+9=1033,16進位制是0409。。繁體中文是1*1024+4=1028,16進位制是0404。
(2)系統locale和使用者locale
在Windows中,通過控制面板可以為系統和使用者分別設定Locale。系統Locale決定內碼表,使用者Locale決定數字、貨幣、時間和日期的格式。使用GetSystemDefaultLCID函式和GetUserDefaultLCID函式分別得到系統和使用者的LCID。使用者程式預設使用的內碼表是當前系統Locale的ANSI內碼表,可以稱作ANSI編碼,對於一個未指定編碼方式的文字檔案,Windows會按照ANSI編碼解釋。
每個Locale都聯絡著很多資訊,可以通過GetLocaleInfo函式讀取。其中最重要的資訊就是字元集了,即Locale對應的語言文字的編碼。Windows將字符集稱作內碼表。
每個Locale可以對應一個ANSI內碼表和一個OEM內碼表。Win32 API使用ANSI內碼表,底層裝置使用OEM內碼表,兩者可以相互對映。
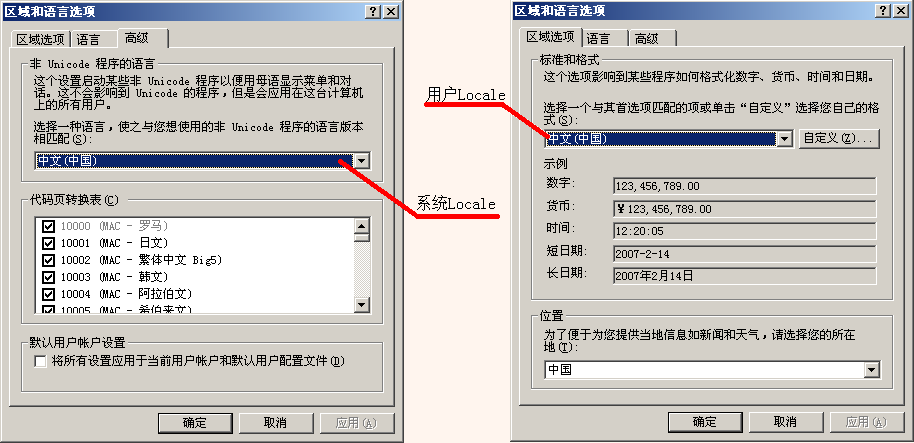
★呼叫GetSystemDefaultLCID和GetUserDefaultLCID函式可以獲得區域資訊識別符號
要獲得本地語言識別符號可以呼叫GetSystemDefaultLangID和GetUserDefaultLangID
2.2 ANSI字元和Unicode字元與字串資料型別
|
|
ANSI |
Unicode |
通用 |
| C\C++ |
char |
wchar_t |
_TCHAR |
| Windows |
CHAR |
WCHAR |
TCHAR |
| 舉例 |
char c='A' char szBuffer[100]= "A String" |
wchar_t c=L'A' WCHAR szBuffer[100]= L"A String" |
TCHAR c=TEXT('A') TCHAR szBuffer[100]= TEXT("A String") |
2.3 Windows中的Unicode函式和ANSI函式——函式名後帶W或A的
★Windows從NT核心版本開始所有平臺均完全基於UNICODE打造,Windows內部其實僅提供了UNICODE版的API,非UNICODE版的API在內部先將引數轉換成UNICODE串,然後再呼叫UNICODE版的API,如果返回結果仍然是UNICODE,那麼就再進行反向轉換。可見在Ansi版函式的效率比較低、開銷記憶體更多。為了效率和相容性,建議應用程式使用Unicode來開發。
2.4 Unicode和ANSI字串函式
(1)常用字串函式
| 功能 |
ANSI(標準C/Win) |
Unicode(標準C/Win) |
通用版本(標準C/Win) |
| 合併字串 |
strcat/lstrcatA |
wcscat/lstrcatW |
_tcscat/lstrcat |
| 比較字串 |
strcmp/lstrcmpA |
wcscmp/lstrcmpW |
_wcscmp/lstrcmp |
| 字串長度 |
strcpy/lstrcpyA 返回位元組數) |
wcslen/lstrlenA |
_tclen/lstrlen 返回字元個數 |
| 列印字串 |
printf/ |
wprintf/ |
_tprintf/ |
注意:
①使用標準c版時一般要選setlocale(或_tsetlocale),否則可能亂碼。此外,C函式一般帶“_t”,要選包含tchar.h檔案)
②Windows版—WinBase.h或WinUser.h
(2)Windows版本的UNICODE字串函式
| 函式 |
描述 |
| CharLower CharLowerBuff |
將字元或字串轉成小寫(C函式為tolower,但Windows版的可作用於字符集中的任何字元(包非英文字元)注意,會改變原字串! |
| CharUpper CharUpperBuff |
將字元或字串轉成大寫 |
| CharNext |
移到字串中的下一個字元 |
| CharPrev |
移動到字串中的前一個字元 |
| IsCharAlpha |
字元是否是字母 |
| IsCharAlphaNumber |
字元是否字母數字 |
| IsCharLower |
字元是否小寫 |
| IsCharUpper |
字元是否大寫 |
| CompareString(Ex) |
字串比較函式(要考慮區域設定) |
| CompareStringOrdinal |
字串比較,只做Unicode的CodePoint比較,不考慮區域設定,速度快。 |
【UpperAndLower程式】大小寫轉換
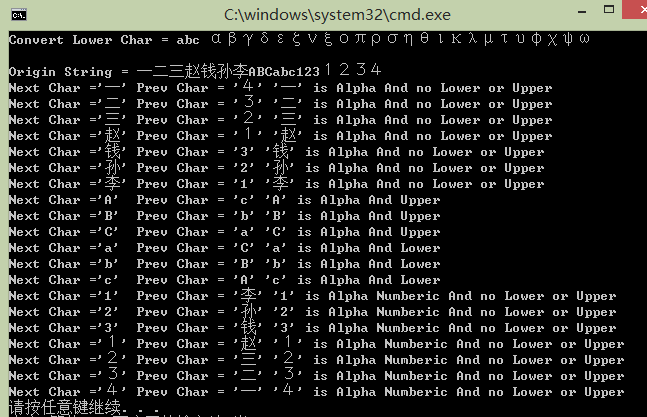
/*----------------------------------------------------------------------------------------------
大小寫轉換測試程式
-----------------------------------------------------------------------------------------------*/
#include <windows.h>
#include <tchar.h>
#include <locale.h>
int _tmain()
{
_tsetlocale(LC_ALL, _T("chs")); //呼叫C庫Unicode函式,須寫這行,否則會亂碼
//大小寫轉換
TCHAR chLower[] = _T("abc αβγδεζνξοπρσηθικλμτυφχψω");
TCHAR *chUpper = NULL;
_tprintf(_T("Lower Char = %s\n"), chLower);
chUpper = CharUpper(chLower); //轉換為大寫
_tprintf(_T("Upper Char = %s\n"), chUpper);
_tprintf(_T("Upper Char Address = 0x%08X,\nLower Char Address = 0x%08X\n"), chUpper, chLower);
CharLower(chUpper);
_tprintf(_T("Convert Lower Char = %s\n"), chLower);
TCHAR pString[] = _T("一二三趙錢孫李ABCabc1231234");//注意,含有全形,CharUpper都可以轉換!
int iLen = lstrlen(pString); //字元個數
TCHAR* pNext = pString; //指向第1個字元
TCHAR* pPrev = pString + sizeof(pString) / sizeof(pString[0]) - 1; //指向最後一個字元,即\0
_tprintf(_T("\nOrigin String = %s\n"), pString);
for (int i = 0; i < iLen;i++)
{
pPrev = CharPrev(pString, pPrev);
_tprintf(_T("Next Char ='%c'\tPrev Char = '%c' "), *pNext, *pPrev);
if (IsCharAlpha(*pNext))
{
_tprintf(_T("'%c' is Alpha"),*pNext);
}
else if (IsCharAlphaNumeric(*pNext))
{
_tprintf(_T("'%c' is Alpha Numberic"),*pNext);
}
else
{
_tprintf(_T("'%c'is Unkown Type"), *pNext);
}
if (IsCharLower(*pNext))
{
_tprintf(_T(" And Lower\n"));
}
else if (IsCharUpper(*pNext))
{
_tprintf(_T(" And Upper\n"));
}
else
{
_tprintf(_T(" And no Lower or Upper\n"));
}
pNext = CharNext(pNext);
}
}