
MapReduce的Map Size Join以及Distributed Cache
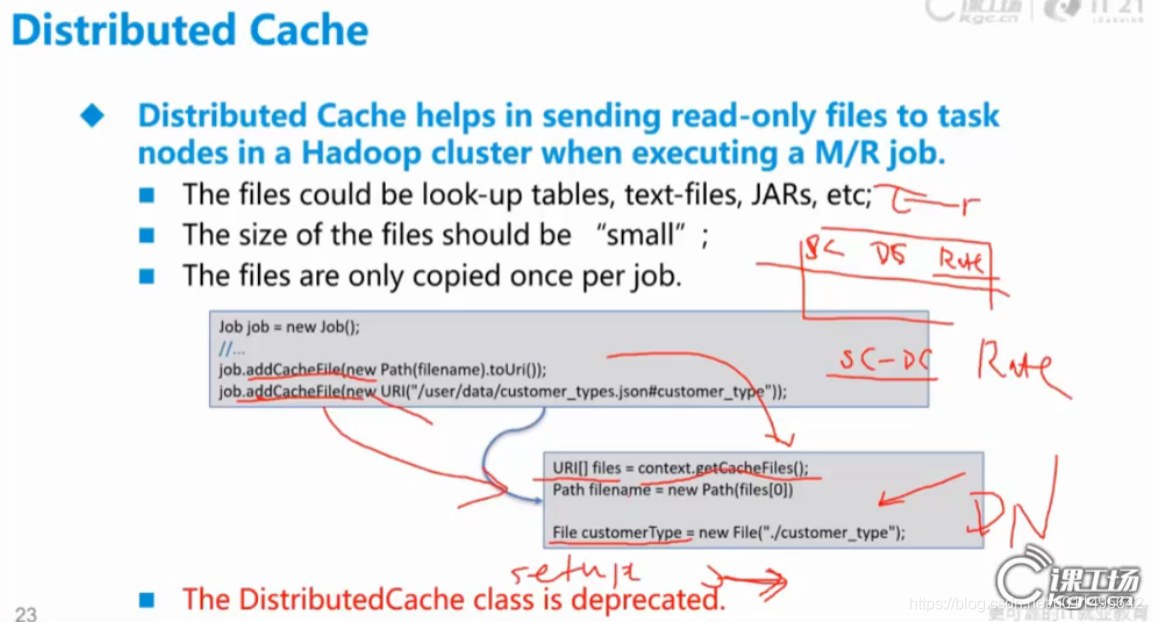
首先介紹Distributed Cache(分散式快取),主要功能是把DataNode(客戶端)一些小的檔案送到DataNode上。
1. 通過job.addCacheFile(new Path(filename).toUri)
2.通過job.addCacheFile(new URI("xx/xxx/xxx/xx.json#customer_type"))
通過1和2來傳過去(都是URI 就是方便你知道在客戶端上這些檔案的位置 )
如果知道檔案路徑的話,new File正好幫你建立一個。
如果不知道檔案路徑,可以通過context一口氣獲取所有快取的檔案,放到一個列表裡,這樣想拿誰都可以。
客戶端某個檔案的內容會被拿到DataNode,但不會修改這些內容,拿過來預設是和原來的檔案一樣的名字。#號可以重新起名。
Map-Side Join就是這樣,在mapper的setup方法裡,把這些小表拿過來
erFile:File = new File("./er.csv")
變成其他格式 比如Hashtable
然後和大表對照做Join

相關推薦
MapReduce的Map Size Join以及Distributed Cache
首先介紹Distributed Cache(分散式快取),主要功能是把DataNode(客戶端)一些小的檔案送到DataNode上。 1. 通過job.addCacheFile(new Path(filename).toUri) 2.通過job.addCacheFile(n
小結left join以及中間表查詢
.com 百度 com log images where 過程 例子 -s 直接上例子: a表 b表 ab表 一、left join 過程(以 select * from a left join ab on a.a_id = ab.a_id): 用a中的記錄根
Flink分散式快取Distributed Cache應用案例實戰-Flink牛刀小試
版權宣告:本套技術專欄是作者(秦凱新)平時工作的總結和昇華,通過從真實商業環境抽取案例進行總結和分享,並給出商業應用的調優建議和叢集環境容量規劃等內容,請持續關注本套部落格。版權宣告:禁止轉載,歡迎學習。QQ郵箱地址:[email protected],如有任何問題,可隨時聯絡。 1 分散式快取
簡述 left join、right join 以及inner join 的區別
left join(左聯接) 返回包括左表中的所有記錄和右表中聯結欄位相等的記錄 right join(右聯接) 返回包括右表中的所有記錄和左表中聯結欄位相等的記錄 inner join(等值連線) 只返回兩個表中聯結欄位相等的行
spark JVM調優之原理概述以及降低cache操作的記憶體佔比
每一次放物件的時候,都是放入eden區域,和其中一個survivor區域;另外一個survivor區域是空閒的。 當eden區域和一個survivor區域放滿了以後(spark執行過程中,產生的物件實在太多了),就會觸發minor gc,小型垃圾回收。把不再使用的物件,從記憶體中清空,給後面新建立
MySQL left join,right join,inner join 以及where和on的區別
Left join,Right join,Inner join 首先Join的前提是兩個有相同的變數作為連線紐帶,left join 和 right join如下圖所示,inner join則是兩圓交集舉個例子,user表和group表通過gid欄位連線,有交集,有補集Rig
08JVM調優之原理概述以及降低cache操作的記憶體佔比
效能調優分類常規效能調優:分配資源、並行度等等方式。JVM 調優(Java虛擬機器):JVM相關的引數。通常情況下,如果你的硬體配置、基礎的 JVM 的配置都 ok 的話,JVM 通常不會造成太嚴重的效能問題,反而更多的是在 troubleshooting 中 JVM 佔了很
Sql 基礎語法join以及多張表join
SQL join 用於根據兩個或多個表中的列之間的關係,從這些表中查詢資料。 有時為了得到完整的結果,我們需要從兩個或更多的表中獲取結果。我們就需要執行 join。 資料庫中的表可通過鍵將彼此聯絡起來。主鍵(Primary Key)是一個列,在這個列中的每一行的值都是唯一的
安裝spark//python中os.path.abspath及os.path.join以及正態分佈PPF
命令: vim ~/.bashrc source ~/.bashrc ps aux | grep spark pkill -f "spark" sudo chown -R sc:sc spark-2.3.1-bin-hadoop2.7/ sudo mv /ho
網頁端報表note:查詢結果拼接join以及setParameterList避坑寫法
需求: 會員名稱 會員手機號 消費次數 跨店消費 最多消費門店 總消費額(元) 最近消費時間 註冊時間 註冊門店 資料庫表: 1 總店和分店的關係表,僅存放兩者的id 2 訂單表,門店code(唯一),消費金額,顧客id,
Flink Distributed Cache 分散式快取
Flink提供了一個分散式快取,類似於hadoop,可以使使用者在並行函式中很方便的讀取本地檔案。此功能可用於共享檔案,包含靜態的外部資料,例如字典或者machine-learned迴歸模型。 此快取的工作機制如下:程式註冊一個檔案或者目錄(本地或者遠端檔案系統,例如hdf
SQL語句中left join、right join 以及inner join的區別
在SQL語句中使用的連線通常有以下三種連線: left join(左聯接) 返回包括左表中的所有記錄和右表中聯結欄位相等的記錄 right join(右聯接) 返回包括右表中的所有記錄和左表中聯結欄位相等的記錄 inner join(等值連線) 只返回兩個
Microsoft Distributed Cache Velocity 分散式快取
微軟分散式快取,工程程式碼為“Velocity”。這是一個分散式記憶體物件快取系統。最新版本為CTP3。下載 跟memcached一樣,“Velocity”維護一張大的雜湊表,這張表可以跨越多個伺服器,你可以通過新增或者減少伺服器來平衡系統壓力。 安裝“
Distributed Cache(分散式快取)-SqlServer
分散式快取是由多個應用伺服器共享的快取,通常作為外部服務儲存在單個應用伺服器上,常用的有SqlServer,Redis,NCache。 分散式快取可以提高ASP.NET Core應用程式的效能和可伸縮性,尤其是應用程式由雲服務或伺服器場託管時。 分散式快取的特點: 跨多個伺服器請求,保證一致性。
consider increasing the maximum size of the cache
inf unable text trap red ima 安裝 web-inf ffi 下午打了一個小盹,等醒來的時候,啟動Tomcat,Tomcat報了滿屏的警告。。。 [2017-06-20 07:53:20,948] Artifact cms:war explode
Process join方法 以及其他屬性
運行 目的 == imp 便是 2個 join 次數 走了 Process join方法 以及其他屬性 在主進程運行過程中如果想並發地執行其他的任務,我們可以開啟子進程,此時主進程的任務與子進程的任務分兩種情況 情況一:在主進程的任務與子進程的任務彼此獨立的情況下,主
ElasticSearch最佳入門實踐(二十七)總結以及什麼是distributed document store
1、總結 快速入門了一下,最基本的原理,最基本的操作 在入門之後,對ES的分散式的基本原理,進行了相對深入一些的剖析 圍繞著document這個東西,進行操作,進行講解和分析 2、什麼是distributed document s
29. 使用join查詢方式找出沒有分類的電影id以及名稱
題目描述 film表 欄位 說明 film_id 電影id title 電影名稱 description 電影描述資訊
執行緒的幾種狀態以及sleep,wait,yield,join的區別
今天第一次寫部落格,因個人能力有限,不到位的地方請大家多多包涵 1.執行緒通常有五種狀態,建立,就緒,執行、阻塞和死亡狀態。 2.阻塞的情況又分為三種: (1)、等待阻塞:執行的執行緒執行wait()方法,該執行緒會釋放佔用的所有資源,JVM會把該執行緒
CACHE 的使用以及比較
好記憶不如爛筆頭,能記下點什麼,就記下點什麼,方便後期的檢視. 一、快取使用的層級 通過下圖,來分析一下各個層級使用快取的情況: 當然,要是使用資料庫的快取,這個就不做過多介紹,一般是使用mybatis 的一,二級快取實現db快取。 二、快取的分類 通過下圖可以看到快取