
Jmeter入門16 資料構造之隨機數Random Variable & __Random函式
介面測試有時引數使用隨機數構造。jmeter新增隨機數兩種方式
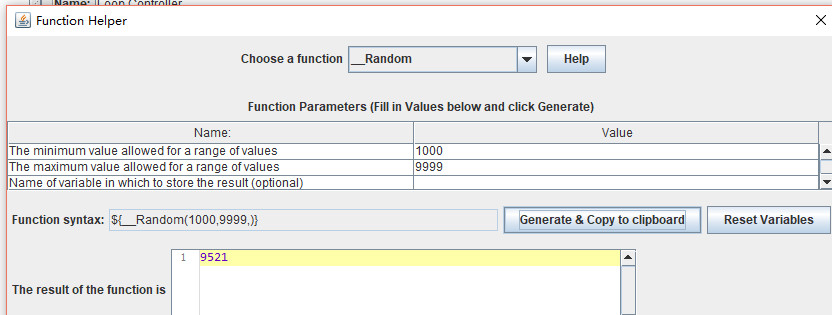
1 新增配置 》 Random Variable
2 __Random函式 ${__Random(1000,9999)}
方式一 Random Variable
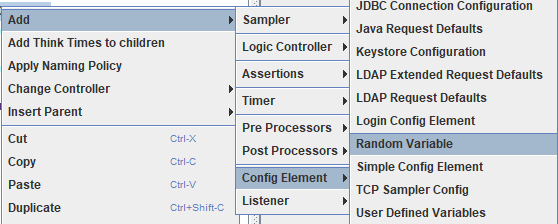

方式二 __Random()函式
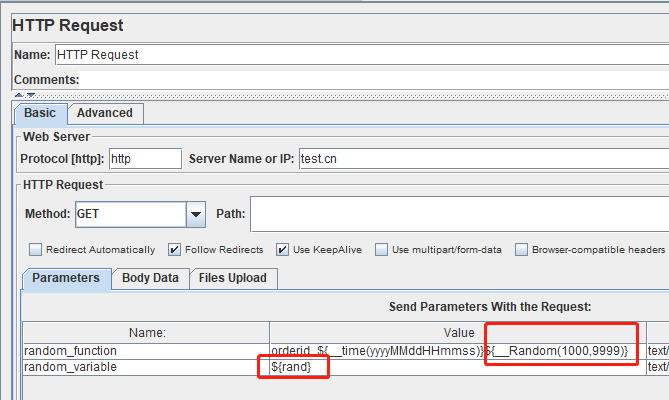
新增http請求,2個引數:訂單號,使用者分別是兩種方式生成的。
訂單號 = 日期+__Random函式生成隨機數
使用者名稱= 隨機變數輸出的固定格式隨機數
random_function orderid_${__time(yyyyMMddHHmmss)}${__Random(1000,9999)}
random_variable ${rand}
新增結果樹,多執行幾次,檢視生成的訂單號和使用者名稱



the end!
相關推薦
Jmeter入門16 資料構造之隨機數Random Variable & __Random函式
介面測試有時引數使用隨機數構造。jmeter新增隨機數兩種方式 1 新增配置 》 Random Variable 2 __Random函式 ${__Random(1000,9999)}
大資料學習之路89-sparkSQL自定義函式計算ip歸屬地
使用sparkSQL當遇到業務邏輯相關的時候,就有可能會搞不定。因為業務l邏輯需要寫很多程式碼,呼叫很多介面。這個時候sql就搞不定了。那麼這個時候我們就會想能不能將業務邏輯嵌入到sql中? 這種就類似於我們在hive中使用過的自定義函式UDF(user define function使用者
資料結構之佇列的定義及建構函式
資料結構之佇列 佇列的定義 佇列是一種特殊的線性表,只允許在表的頭部進行刪除操作,在表的尾部進行插入操作的線性資料結構,這種結構就叫做佇列;另外其還有先進先出,後進後出的特徵。 說到線性結構,得先了解一下資料的邏輯結構,資料的邏輯結構分為線性結構、集合結構、樹形結構和圖形結構,如下圖所示,棧是一種特殊的線
C語言入門學習(02)——HelloWorld程式分析&printf函式的用法
接著上一篇 C語言入門學習(01)——C程式設計環境的搭建及HelloWorld程式 繼續 //本文不是最終版本,該教程還在編寫整理中。 目錄 Part_2.1:HelloWorld程式的解釋 Part_2.2:printf函式的用法 P
隨機數之Math.random
imp 輸入 and spa 方法 turn art 鍵盤輸入 兩種 隨機數產生的兩種方式,暫時只會一種,這種方法產生的隨機數是偽隨機數 1 import java.util.Scanner; 2 3 //從鍵盤輸入一個範圍[start,end],獲取該範圍內的隨
Jmeter入門13 jmeter傳送application/octet-stream二進位制流資料
http介面請求header裡面 content-type: application/octet-stream (二進位制流資料),如何用jmeter傳送請求? 1 新增http請求頭 2 http請求 files u
資料結構之演算法入門經典
輸入 輸入完畢先按enter,再按ctrl+z,最後按enter,即可結束輸入。 int x; while(scanf("%d",&x)==1) { //程式 } 使用檔案輸入: freopen("input.txt","r",st
原創 | 入門資料分析--資料儲存之常用資料庫及區別
獲取資料,除了通過外部獲得,內部獲取,也是一個主要獲取資料的方式。內部資料主要是通過資料庫儲存的方式,將資料存下來,便於各個需求方再去提取應用。那麼,企業常用的儲存資料的資料庫都有哪些呢?不同的資料庫的儲存區別又有哪些? 目前市場上的資料庫主要可以分為關係型資料庫和非關係型資料庫,關係型資料庫通過外來鍵關聯
資料分析之pandas入門
概念 Python Data Analysis Library 或 pandas 是基於NumPy 的一種工具,該工具是為了解決資料分析任務而建立的。Pandas 納入了大量庫和一些標準的資料模型,提供了高效地操作大型資料集所需的工具。pandas提供了大量能使我們快速便捷地處理資料的
零基礎入門大資料之spark中rdd部分運算元詳解
先前文章介紹過一些spark相關知識,本文繼續補充一些細節。 我們知道,spark中一個重要的資料結構是rdd,這是一種並行集合的資料格式,大多數操作都是圍繞著rdd來的,rdd裡面擁有眾多的方法可以呼叫從而實現各種各樣的功能,那麼通常情況下我們讀入的資料來源並非rdd格式的,如何轉
零基礎入門大資料之spark中的幾種key-value操作
今天記錄一下spark裡面的一些key-value對的相關運算元。 key-value對可以簡單理解為是一種認為構造的資料結構方式,比如一個字串"hello",單看"hello"的話,它是一個字串型別,現在假設我想把它在一個文字中出現的次數n作為一個值和"hello"一起操作,那麼可
零基礎入門大資料探勘之spark中的幾種map
今天再來說一下spark裡面的幾種map方法。前面的文章介紹過單純的map,但是spark還有幾種map值得對比一下,主要是下面幾種: map:普通的map flatMap:在普通map的基礎上多了一個操作,扁平化操作; mapPartitions:相對於分割槽P
零基礎入門大資料探勘之spark的rdd
本節簡單介紹一下spark下的基本資料結構RDD,方便理解後續的更多操作。 那麼第一個問題,什麼是rdd。我們知道,大資料一般儲存在分散式叢集裡面,那麼你在對其進行處理的時候總得把它讀出來吧,讀出來後總得把它存成某種格式的檔案吧,就好比程式語言裡面的,這個資料是陣列,那麼你可以以陣列
零基礎入門大資料探勘之reduce方法
上節介紹過大資料裡面(以spark為例)最為基礎典型的操作:map方法,map方法直白的理解就是一個分散式接受處理函式的方法,形式如map(fun),map方法本身不做處理,沒有map方法,裡面的函式fun就是一個單機的處理函式,有了map,相當於就把這個函式複製到多臺機器上,每臺機器同
前端入門8-JavaScript語法之資料型別和變數
宣告 本系列文章內容全部梳理自以下幾個來源: 《JavaScript權威指南》 MDN web docs Github:smyhvae/web Github:goddyZhao/Translation/JavaScript 作為一個前端小白,入門跟著這幾個來源學習,感謝作者的分享,
大資料學習之Hadoop快速入門
1、Hadoop生態概況 Hadoop是一個由Apache基金會所開發的分散式系統整合架構,使用者可以在不瞭解分散式底層細節情況下,開發分散式程式,充分利用叢集的威力來進行高速運算與儲存,具有可靠、高效、可伸縮的特點。 大資料學習資料分享群119599574 Hadoop
【Kibana6.3.0】Kibana6入門小白教程之下載安裝與資料準備
1. Kibana簡介及下載安裝 Kibana是專門用來為ElasticSearch設計開發的,可以提供資料查詢,資料視覺化等功能。 下載地址為:https://www.elastic.co/downloads/kibana#ga-release,請選擇適合當前es版本的K
Python資料分析之路| 入門起航篇
資料分析準備工作 1.資料分析工具 工欲善其事,必先利其器,網上有很多關於資料分析的文章,相信大家一定聽過R語言和Python之爭,而且各有千秋,R語言在學術界更流行,但是在做專案上面我個人比較喜歡Python,Python更通用,更簡潔,文件也很多,而且有大量的庫特別是Google,Fac
大資料入門必學技術之Hadoop
Hadoop是一個能夠對大量資料進行分散式處理的軟體框架。使用者可以輕鬆地在Hadoop上開發和執行處理海量資料的應用程式,在大資料領域應用比較多。本文就和大家一起認識一下Hadoop技術: 1 Hadoop歷史 雛形開始於2002年的Apache的N
入門大資料領域需要哪些技能|大資料工程師學習之路
入門大資料領域需要哪些技能?大資料學習之路。 大資料是當時時代下一門炙熱的IT學科,行情十分火爆,不論是阿里巴巴、百度這樣的大公司,還是中小企業都很重視,甚至是第一個納入國家戰略的技術,政府扶持力度大,支援甚多!面對這樣的大環境下,大資料相關崗位薪水高,就業前景好。因此也吸引了一大批有志之士,想學習並從