
MySQL技術內幕 InnoDB儲存引擎:B+樹索引的使用
1、聯合索引
MySQL允許對錶上的多個列進行索引,聯合索引的建立方法與單個索引建立的方法一樣,不同之處僅在於有多個索引列。
CREATE TABLE t( a INT, b INT,
PRIMARY KEY(a),
KEY idx_a_b(a, b)
)ENGINE=InnoDB
多個鍵值的B+樹
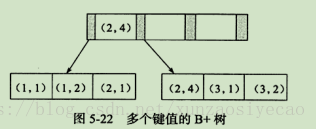
- 對於查詢SELECT*FROM TABLE WHERE a=xxx and b=xxx,顯然是可以使用(a, b)這個聯合索引的。
- 對於單個的a列查詢SELECT*FROM TABLE WHERE a=xxx,也可以使用這個(a, b)索引。
- 但對於b列的查詢SELECT*FROM TABLE WHERE b=xxx,則不可以使用這棵B+樹索引。
**聯合索引的第二個好處是已經對第二個鍵值進行了排序處理。**例如,在很多情況下應用程式都需要查詢某個使用者的購物情況,並按照時間進行排序,最後取出最近三次的購買記錄,這時使用聯合索引可以避免多一次的排序操作,因為索引本身在葉子節點已經排序了。
2、覆蓋索引(covering index)
即從輔助索引中就可以得到查詢的記錄, 而不需要查詢聚集索引中的記錄。 使用覆蓋索引的一個好處是輔助索引不包含整行記錄的所有資訊, 故其大小要遠小於聚集索引, 因此可以減少大量的 IO 操作。
對於InnoDB儲存引擎的輔助索引而言,由於其包含了主鍵資訊,因此其葉子節點存放的資料為(primary key1,priamey key2,…,key1,key2,…)。例如,下面語句都可僅使用一次輔助聯合索引來完成查詢
SELECT key2 FROM table WHERE key1=xxx;
SELECT primary key2,key2 FROM table key1=xxx;
SELECT primary key1,key2 FROM table key1=xxx;
SELECT primary key1,primary key2,key2 FROM table key1=xxx;
覆蓋索引的另一個好處是對某些統計問題而言,如上的buy_log,要進行如下查詢
CREATE TABLE buy_log( userid INT UNSIGNED NOT NULL, buy_date DATE )ENGINE=INNODB; INSERT INTO buy_log VALUES(1,‘2009-01-01‘); INSERT INTO buy_log VALUES(2,‘2009-01-01‘); INSERT INTO buy_log VALUES(3,‘2009-01-01‘); INSERT INTO buy_log VALUES(1,‘2009-02-01‘); INSERT INTO buy_log VALUES(3,‘2009-02-01‘); INSERT INTO buy_log VALUES(1,‘2009-03-01‘); INSERT INTO buy_log VALUES(1,‘2009-04-01‘); ALTER TABLE buy_log ADD KEY(userid); ALTER TABLE buy_log ADD KEY(userid,buy_date);
explain SELECT COUNT(*) FROM buy_log;
InnoDB儲存引擎並不會選擇通過查詢聚集索引來進行統計。由於buy_log還有輔助索引,而輔助索引遠小於聚集索引。選擇輔助索引可以減少IO操作。
如圖顯示。possible_keys是NULL,但是實際執行優化器卻選擇了userid,而列Extra的Using index就是代表優化器選擇了覆蓋索引的操作 。

3、索引提示
MySQL資料庫支援索引提示(INDEX HINT)顯式的高速優化器使用了哪個索引。以下是可能需要用到INDEX HINT的情況
- MySQL資料庫的優化器錯誤的選擇了某個索引,導致SQL執行很慢。這個在最新版的資料庫版本中非常少見。優化器在絕大部分情況下工作的非常有效和正確。
- 某些SQL語句可以選擇的索引非常多,這時優化器選擇執行計劃時間的開銷可能會大於SQL語句本身例如優化器分析Range查詢本身就是比較耗時的操作。這時DBA或開發人員分析最優的索引選擇,通過index hint來強制使優化器不進行各個路徑的成本分析直接選擇指定的索引來完成查詢
4、Multi-Range Read優化
MySQL 5.6開始支援Multi-Range Read(MRR)優化。目的是為了減少磁碟的隨機訪問,並且將隨機訪問轉化為較為順序的資料訪問,這對IO-bound型別的SQL查詢語句可帶來效能極大的提升。MRR優化可適用於rangeref,eq_ref型別的查詢
MRR優化的好處
-
MRR使資料訪問變得較為順序。在查詢輔助索引時,首先根據得到的查詢結果按照主鍵進行排序,並按照主鍵排序的順序進行書籤查詢
-
減少緩衝池中頁被替換的次數
-
批量處理對鍵值的查詢操作
對於InnoDB和MyISAM儲存引擎的範圍查詢和JOIN查詢操作,MRR工作方式如下
-
將查詢得到的輔助索引鍵值存放在一個快取中,這是快取中的資料是根據輔助索引鍵值排序的
-
將快取中的鍵值根據RowID進行排序
-
根據RowID的排序順序來訪問實際的資料檔案
此外,若InnoDB儲存引擎或者MyISAM儲存引擎的緩衝池不足夠大,即不能存放下一張表中的所有資料,此時頻繁的離散讀操作還會導致快取中的頁被替換出緩衝池,然後有不斷地被讀入緩衝池。
5、Index Condition Pushdown 優化
ICP原理通俗講就是,查詢過程中,直接在查詢引擎層的API獲取資料的時候實現"非直接索引"過濾條件的篩選,而不是查詢引擎層查詢出來之後在Server層篩選。
換句話說就是ICP在獲取資料的同時實現了where的次選條件中無法直接使用索引的情況下的篩選,避免了沒有ICP優化的時候分兩個步驟的實現(獲取資料的過程沒有做次選條件的過濾)
如果是非ICP優化查詢的話,是兩步:
- 獲取資料
- 獲取的資料進行條件篩選。
顯然,相比後者,前者可以一步實現索引的查詢Seek+filter,效率上更高。
適應的場景:
ICP的優化策略可用於range、ref、eq_ref、ref_or_null 型別的訪問資料方法
本文整理自:《MySQL技術內幕 InnoDB儲存引擎》
個人微信公眾號:

作者:jiankunking 出處:http://blog.csdn.net/jiankunking