
JAVA架構師大型分散式高併發電商專案實戰,效能優化,叢集,億級高併發,web安全,快取架構實戰
現任58到家技術委員會主席,高階技術總監,負責企業,支付,營銷、客戶關係等多個後端業務部門。本質,技術人一枚。網際網路架構技術專家,“架構師之路”公眾號作者。曾任百度高階工程師,58同城高階架構師,58同城技術委員會主席,58同城C2C技術部負責人。
內容介紹
1.大資料量時,資料庫架構設計原則
2.資料庫水平切分架構設計方向
3.使用者中心,帖子中心,好友中心,訂單中心水平切分架構實踐
下面是58沈劍老師的演講實錄
大家好,我是58沈劍,架構師之路的小編,後端程式設計師一枚,平時比較喜歡寫寫文字。今天和大家分享,資料量很大的情況下,如何進行資料庫架構設計(主要是水平切分)會舉使用者中心,帖子中心,訂單中心的一些例子,希望大家有收穫。
首先,介紹資料庫架構設計中的一些基本概念,常見問題以及對應解決方案,為了便於讀者理解,將以“使用者中心”資料庫為例,講解資料庫架構設計的常見玩法。
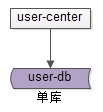
第一個概念是“單庫”。
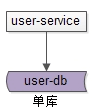
user-service:使用者中心服務,對呼叫者提供友好的RPC介面,user-db:單庫(就是一個庫)進行資料儲存。
第二個概念是“分組”。
什麼是分組?分組架構是最常見的一主多從,主從同步,讀寫分離資料庫架構
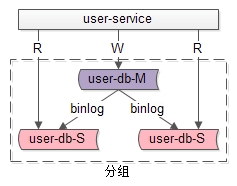
user-service:依舊是使用者中心服務
user-db-M(master):主庫,提供資料庫寫服務
user-db-S(slave):從庫,提供資料庫讀服務
主和從構成的資料庫叢集稱為“組”。分組解決的是“資料庫讀寫高併發量高”問題。
第三個概念是“分片”。
分片架構是大夥常說的水平切分(sharding)資料庫架構。
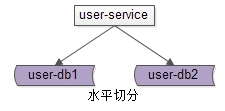
user-db1:水平切分成2份中的第一份,user-db2:水平切分成2份中的第二份,分片後,多個數據庫例項也會構成一個數據庫叢集。一旦分片,就涉及分片演算法。常見的水平切分演算法有“範圍法”和“雜湊法”
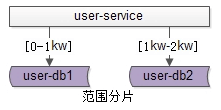
範圍法如上圖:以使用者中心的業務主鍵uid為劃分依據,將資料水平切分到兩個資料庫例項上去。
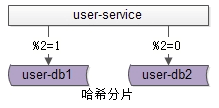
雜湊法如上圖
user-db1:儲存uid取模得1的uid資料,user-db2:儲存uid取模得0的uid資料。這兩種分片演算法,在網際網路都有使用,其中雜湊法使用較為廣泛。
分片解決的是“資料庫資料量大”問題,也就是今天資料庫架構分享的主題。
場景一、使用者中心
第一個案例,先以“使用者中心”為例,介紹“單KEY”類業務,隨著資料量的逐步增大,資料庫效能顯著降低,資料庫水平切分相關的架構實踐。
使用者中心是一個非常常見的業務,主要提供使用者註冊、登入、資訊查詢與修改的服務。其核心元資料為:
User(uid, login_name, passwd, sex, age, nickname, …); uid為使用者ID,主鍵。login_name, passwd, sex, age, nickname, …等使用者屬性。資料庫設計上,一般來說在業務初期,單庫單表就能夠搞定這個需求。
當資料量越來越大時,需要多使用者中心進行水平切分,上文提到了“範圍法”與“雜湊法”。使用uid來進行水平切分之後,整個使用者中心的業務訪問會遇到什麼問題呢?對於uid屬性上的查詢可以直接路由到庫,對於非uid屬性上的查詢,例如login_name屬性上的查詢,就悲劇了。
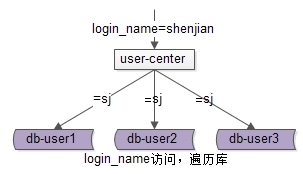
例如,按照uid分為3個庫,使用login_name=shenjian來查詢,就不知道資料分佈在哪個庫上了。一種方法,是遍歷所有庫,當分庫數量多起來,效能會顯著降低。
常見的解決方案,有這麼四種方法:
第一種方法,索引表法
思路:uid能直接定位到庫,login_name不能直接定位到庫,如果通過login_name能查詢到uid,問題解決。
細緻的步驟為:
(1)建立一個索引表記錄login_name->uid的對映關係;
(2)用login_name來訪問時,先通過索引表查詢到uid,再定位相應的庫;
(3)索引表屬性較少,只有兩列,可以容納非常多資料,一般不需要分庫
(4)如果資料量過大,可以通過login_name來分庫;
潛在的不足是:多一次資料庫查詢,效能會有所下降。
第二種方法,快取對映法
思路:訪問索引表效能較低,把對映關係放在快取裡效能更佳
細緻的步驟為:
(1)login_name查詢先到cache中查詢uid,再根據uid定位資料庫;
(2)假設cache miss,採用掃全庫法獲取login_name對應的uid,放入cache;
(3)login_name到uid的對映關係不會變化,對映關係一旦放入快取,不會更改,無需淘汰,快取命中率超高;
(4)如果資料量過大,可以通過login_name進行cache水平切分;
潛在的不足是:多了一次cache查詢。
第三種方法,login_name生成uid法
思路:不進行額外查詢,能由login_name直接生成uid麼?
細緻的步驟為:
(1)在使用者註冊時,設計函式login_name生成uid,uid=f(login_name),按uid分庫插入資料;
(2)用login_name來訪問時,先通過函式計算出uid,即uid=f(login_name)再來一遍,由uid路由到對應庫;
潛在的不足是:該函式設計需要非常講究技巧,有uid生成衝突風險
第四種方法,基因法(這個方法網上沒有,在“架構是之路”公眾號裡有說明過)
思路:不用login_name生成uid,可以從login_name抽取“基因”,融入uid中。
方法圖示如下(這個圖很重要):
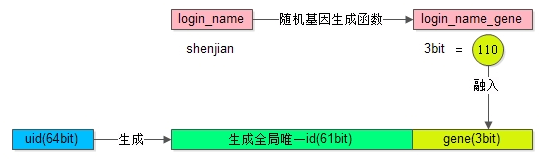
假設分8庫,採用uid%8路由。潛臺詞是,uid的最後3個bit決定這條資料落在哪個庫上,這3個bit就是所謂的“基因”。
細緻的步驟為:
(1)在使用者註冊時,設計函式login_name生成3bit基因,login_name_gene=f(login_name),如上圖粉色部分;【畫外音,一定要步驟和圖對著看】
(2)同時,生成61bit的全域性唯一id,作為使用者的標識,如上圖綠色部分;
(3)接著把3bit的login_name_gene也作為uid的一部分,如上圖屎黃色部分;
(4)生成64bit的uid,由id和login_name_gene拼裝而成,並按照uid分庫插入資料;
(5)用login_name來訪問時,先通過函式由login_name再次復原3bit基因,login_name_gene=f(login_name),通過login_name_gene%8直接定位到庫。如此這般,uid可以直接定位到庫,login_name可以生成基因,也可以定位到庫。
好,使用者中心是第一個場景。
場景二、帖子中心
第二個場景,將以“帖子中心”為例,介紹“1對多”類業務,隨著資料量的逐步增大,資料庫效能顯著降低,資料庫水平切分相關的架構實踐。使用者中心,是一個但key場景,而帖子中心,是一個1對多的場景。
什麼是1對多場景?
一個使用者可以發多條微博,一條微博只有一個傳送者;一個uid對應多個msg_id,一個msg_id只對應一個uid;這些是1對多的關係。
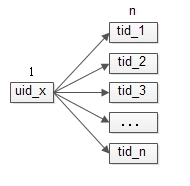
一個使用者可以釋出多個帖子,一個帖子只對應一個釋出者。帖子中心,是一個提供帖子釋出,修改,刪除,檢視,搜尋的服務。
讀操作:通過tid查詢帖子實體,單行查詢;通過uid查詢使用者釋出過的帖子,列表查詢。帖子檢索,例如通過時間、標題、內容搜尋符合條件的帖子。
寫操作:釋出(insert)帖子;修改(update)帖子;刪除(delete)帖子。
在資料量較大,併發量較大的時候,通常通過元資料與索引資料分離的架構來滿足實時查詢,以及帖子檢索的入球。
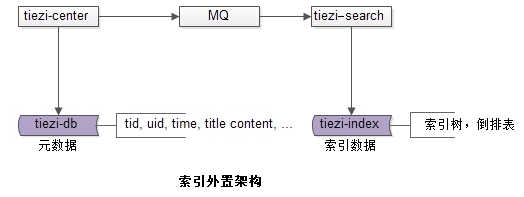
架構中的幾個關鍵點
(1)tiezi-center服務;
(2)tiezi-db:提供元資料儲存;
(3)tiezi-search搜尋服務;
(4)tiezi-index:提供索引資料儲存;
(5)MQ:tiezi-center與tiezi-search通訊媒介,一般不直接使用RPC呼叫,而是通過MQ對兩個子系統解耦;
【畫外音:12345對著圖細看一下】
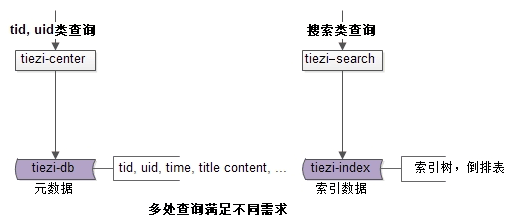
如上圖所示:tid和uid上的查詢需求,可以由tiezi-center從元資料讀取並返回,其他檢索需求,可以由tiezi-search從索引資料檢索並返回,tiezi-search可以使用Solr,ES等開源架構實現,這一塊不是今天的重點,今天將重點描述帖子中心元資料這一塊的水平切分設計。在業務初期,單庫就能滿足元資料儲存要求。
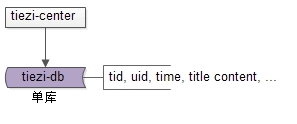
在相關欄位上建立索引,就能滿足相關業務需求,帖子記錄查詢,通過tid查詢,約佔讀請求量的90% 。select * from t_tiezi where tid=$tid 帖子列表查詢,通過uid查詢其釋出的所有帖子,約佔讀請求量的10% ,select * from t_tiezi where uid=$uid。當資料量越來越大時,需要對帖子資料的儲存進行線性擴充套件,既然是帖子中心,並且帖子記錄查詢量佔了總請求的90%,很容易想到通過tid欄位取模來進行水平切分。
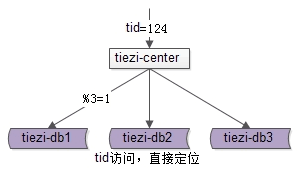
這個方法簡單直接。但缺點是:一個使用者釋出的所有帖子可能會落到不同的庫上,10%的請求通過uid來查詢會比較麻煩。
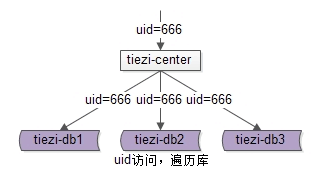
一個uid查詢帖子列表,需要遍歷所有庫。有沒有一種切分方法,確保同一個使用者釋出的所有帖子都落在同一個庫上,而在查詢一個使用者釋出的所有帖子時,不需要去遍歷所有的庫呢?
使用uid來分庫可以解決這個問題。
新增一個索引庫:t_mapping(tid, uid)
(1)這個庫只有兩列,可以承載很多資料;
(2)即使資料量過大,索引庫可以利用tid水平切分;
(3)這類kv形式的索引結構,可以很好的利用cache優化查詢效能;
(4)一旦帖子釋出,tid和uid的對映關係就不會發生變化,cache的命中率會非常高;
如此這般,可以保證一個uid的所有tid都在一個庫上,使用tid查詢時,先通過mapping庫查詢到uid,再定位庫,這就是帖子中心場景,使用uid來進行分庫的好處。
mapping表法,和使用者中心的索引表很像,那是不是也能使用“基因法”呢?答案是肯定的,如果login_name生成基因打入uid一樣,可以在uid上取基因,打入tid。
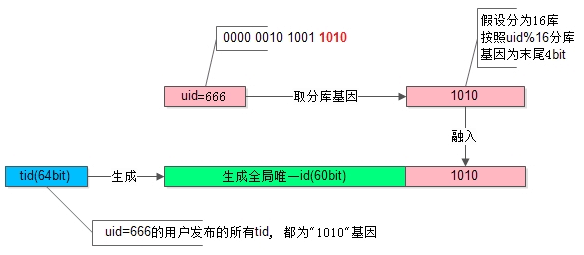
如上圖所示,假設分為16庫,用uid%16分庫,假設uid=666的使用者釋出了一條帖子
(1)使用uid%16分庫,決定這行資料要插入到哪個庫中;
(2)%16,即分庫基因是uid的最後4個bit,即1010;
(3)在生成tid時,先使用一種分散式ID生成演算法生成前60bit(上圖中綠色部分);
(4)將分庫基因加入到tid的最後4個bit(上圖中粉色部分),拼裝成最終的64bit帖子tid(上圖中藍色部分);
【畫外音,對照上圖看1234】
通過這種方法保證,同一個使用者釋出的所有帖子的tid,都落在同一個庫上,tid的最後4個bit都相同
於是,通過uid%16能夠定位到庫,通過tid%16也能定位到庫,基因法很有意思,網上幾乎沒有文章介紹,更詳細的基因法介紹,可以掃下列二維碼查閱。

沒錯,就是架構師之路,基因法,哈哈。
場景三、好友中心
第三個場景,是好友中心,好友中心,是一個多對多的場景。
什麼是多對多關係?
所謂的“多對多”,來自資料庫設計中的“實體-關係”ER模型,用來描述實體之間的關聯關係。一個學生可以選修多個課程,一個課程可以被多個學生選修,這裡學生與課程時間的關係,就是多對多關係。
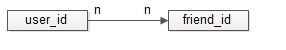
好友中心是一個典型的多對多業務,一個使用者可以關注多個好友,也可以被多個好友關注。
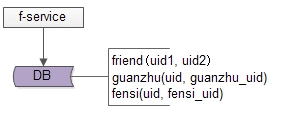
friend-service:好友中心服務,對呼叫者提供友好的RPC介面,guanzhu表,使用者記錄uid所有關注使用者guanzhu_uid。fensi表,用來記錄uid所有粉絲使用者fensi_uid。一條好友關係的產生,會產生兩條記錄,一條關注記錄,一條粉絲記錄。資料量大時,如何進行水平切分呢?關注表,使用uid分庫,儲存的是關注的人。粉絲表,也使用uid分庫,儲存的是粉絲。由於一條好友關係的產生,會產生兩條記錄,分庫的時候要注意,需要保證資料的一致性,關注庫,粉絲庫,可能儲存在不同的資料例項上,資料的插入難以保證原子性。
這是一個很難的“分散式事務”的問題。具體的資料冗餘方式,常見的有這麼兩種:
第一種,同步冗餘。
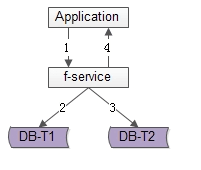
顧名思義,由好友中心服務同步寫冗餘資料。如上圖1-4流程
(1)業務方呼叫服務,新增好友關係資料;
(2)服務先插入T1資料;
(3)服務再插入T2資料;
(4)服務返回業務方新增資料成功;
第二種,非同步冗餘
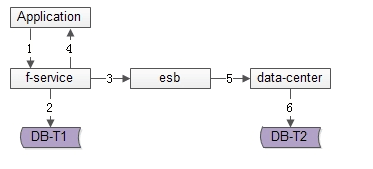
服務層非同步發出一個訊息,通過訊息匯流排傳送給一個專門的資料複製服務來寫入冗餘資料。如上圖1-6流程
(1)業務方呼叫服務,新增資料;
(2)服務先插入T1資料;
(3)服務向訊息匯流排傳送一個非同步訊息(發出即可,非同步不用等返回,通常很快就能完成);
(4)服務返回業務方新增資料成功;
(5)訊息匯流排將訊息投遞給資料同步中心;
(6)資料同步中心插入T2資料;
這是兩種很常見的冗餘資料的方式。資料的一致性如何保證?如果插入T1資料,T2資料插入失敗呢?需要有一個校驗機制。這裡多提一句,為了保證一致性,架構設計的思路有兩種:
(1)分散式事務,保證強一致;
(2)新增非同步校驗機制;
第一個方向,很難,是業界沒有解決的難題。或者說,即使有理論上可行的方案,演算法效率也非常非常低,不適合網際網路高併發場景。此時的架構優化方向,並不是完全保證資料的一致,而是儘早的發現不一致,並修復不一致。校驗機制,又有兩種常見的方法。
一種是非同步掃描校驗
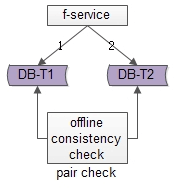
線下啟動一個離線的掃描工具,不停的比對正表T1和反表T2,如果發現數據不一致,就進行補償修復,這個方法是最容易想到的。
一種是實時訊息掃描校驗
(1)寫入正表T1;
(2)第一步成功後,傳送訊息msg1;
(3)寫入反表T2;
(4)第二步成功後,傳送訊息msg2;
正常情況下,msg1和msg2的接收時間應該在3s以內,如果檢測服務在收到msg1後沒有收到msg2,就嘗試檢測資料的一致性,不一致時進行補償修復。第一個方案比較容易,但時效性差,第二個方案比較複雜,但時效好。這裡再強調一下,分散式事務一致性,是我被詢問最多的問題。 無數網友在公眾號下方留言問,分散式事務一致性的問題。
這裡再強調一下方法論。高吞吐網際網路業務,要想完全保證事務一致性很難,常見的實踐是最終一致性 。最終一致性的常見實踐是,儘快找到不一致,並修復資料。
場景四、訂單中心
第四個場景,也是最後一個場景,是最複雜的,訂單中心的分庫。這是一個多key的場景。
Order(oid, buyer_uid, seller_uid, time, money, detail…);為啥叫多key呢
(1)oid為訂單ID,主鍵;
(2)buyer_uid為買家uid;
(3)seller_uid為賣家uid;
看到了吧,訪問模式有多個。隨著訂單量的越來越大,資料庫需要進行水平切分,由於存在多個key上的查詢需求,用哪個欄位進行切分,成了需要解決的關鍵技術問題。
如果用oid來切分,buyer_uid和seller_uid上的查詢則需要遍歷多庫,如果用buyer_uid或seller_uid來切分,其他屬性上的查詢則需要遍歷多庫。
思路為,多個維度的查詢較為複雜,對於複雜系統設計,可以逐步簡化。假設沒有seller_uid,訂單中心,假設沒有seller_uid上的查詢需求,而只有oid和buyer_uid上的查詢需求,應該怎麼分庫?
沒錯,沒有seller_uid,就蛻化為一個“1對多”的業務場景,對於“1對多”的業務,水平切分應該使用“基因法”。
再次回顧一下,什麼是分庫基因?通過buyer_uid分庫,假設分為16個庫,採用buyer_uid%16的方式來進行資料庫路由,所謂的模16,其本質是buyer_uid的最後4個bit決定這行資料落在哪個庫上,這4個bit,就是分庫基因。在訂單資料oid生成時,oid末端加入分庫基因,讓同一個buyer_uid下的所有訂單都含有相同基因,落在同一個分庫上。
再次假設,這個場景如果沒有訂單ID的oid呢?假設沒有oid上的查詢需求,而只有buyer_uid和seller_uid上的查詢需求,就蛻化為一個“多對多”的業務場景。對於“多對多”的業務,就和好友中心一樣,水平切分應該使用“資料冗餘法”(上面提到的關注庫,粉絲庫)。
訂單中心,該怎麼弄呢?任何複雜難題的解決,都是一個化繁為簡,逐步擊破的過程。對於像訂單中心一樣複雜的“多key”類業務,在資料量較大,需要對資料庫進行水平切分時:
(1)使用“基因法”,解決“1對多”分庫需求:使用buyer_uid分庫,在oid中加入分庫基因,同時滿足oid和buyer_uid上的查詢需求;
(2)使用“資料冗餘法”,解決“多對多”分庫需求:使用buyer_uid和seller_uid來分別分庫,冗餘資料,滿足buyer_uid和seller_uid上的查詢需求;
(3)訂單中心,oid/buyer_uid/seller_uid同時存在,可以使用上述兩種方案的綜合方案,來解決“多key”業務的資料庫水平切分難題;
今天的分享差不多就到這裡,最後做一個小結
水平切分方式;
範圍法;
雜湊法;
使用者側,“建立非uid屬性到uid的對映關係”最佳實踐。索引表法:資料庫中記錄login_name->uid的對映關係。快取對映法:快取中記錄login_name->uid的對映關係。生成法:login_name生成uid;基因法:login_name基因融入uid;
帖子側,帖子服務,元資料滿足uid和tid的查詢需求。搜尋服務,索引資料滿足複雜搜尋尋求。uid切分法,按照uid分庫,同一個使用者釋出的帖子落在同一個庫上,需要通過索引表或者快取來記錄tid與uid的對映關係,通過tid來查詢時,先查到uid,再通過uid定位庫。基因法,按照uid分庫,在生成tid里加入uid上的分庫基因,保證通過uid和tid都能直接定位到庫。
好友側,資料冗餘是一個常見的多對多業務資料水平切分實踐。冗餘資料的常見方案有兩種:服務同步冗餘,服務非同步冗餘(通過MQ發訊息)。資料冗餘會帶來一致性問題,高吞吐網際網路業務,要想完全保證事務一致性很難,常見的實踐是最終一致性。最終一致性的常見實踐是,儘快找到不一致,並修復資料,常見方案有:線下掃描法,實時訊息法。
訂單側,任何複雜難題的解決,都是一個化繁為簡,逐步擊破的過程。將“多key”類業務,分解為“1對多”類業務和“多對多”類業務分別解決。使用“基因法”,解決“1對多”分庫需求:使用buyer_uid分庫,在oid中加入分庫基因,同時滿足oid和buyer_uid上的查詢需求。使用“資料冗餘法”,解決“多對多”分庫需求:使用buyer_uid和seller_uid來分別分庫,冗餘資料,滿足buyer_uid和seller_uid上的查詢需求。oid/buyer_uid/seller_uid同時存在,可以使用上述兩種方案的綜合方案,來解決“多key”業務的資料庫水平切分難題。
最後再多說一句,任何脫離業務的架構設計都是耍流氓,共勉。
今天,僅僅只是展開描述了“水平切分”這一個話題,在資料庫架構設計過程中,除了水平切分,至少還會遇到這樣一些問題:
(1)可用性:不管是主庫例項,還是從庫例項,如果資料庫例項掛了,如何不影響資料的讀和寫;
(2)讀效能:網際網路業務大多是讀多寫少的業務,如果提升資料庫的讀效能是架構設計中必須考慮的問題;(3)一致性:資料一旦冗餘,就可能出現一致性問題,如何解決主庫與從庫之間的不一致,如何解決資料庫與快取之間的不一致,也是需要重點設計的;
(4)擴充套件性:如何在不停服務的情況下擴充資料表的屬性,實施資料遷移,實施儲存引擎的切換,架構設計上都是十分有講究的;
(5)分散式SQL語句:單庫情況下,所有SQL語句的執行都沒問題問題,一旦實施了水平切分,如何實現SQL的集函式,分頁,非patition key上的查詢都成了大問題;
上面這些問題,由於時間的關係,今天不能再展開。要想了解細節,你懂的,掃描上面的二維碼,微信關注“架構師之路”,有你想要的答案。對於“資料庫水平切分”,希望大家有收穫,希望下次還有機會在51CTO群裡分享。
以下問題是來自51CTO開發者社群小夥伴們的提問和分享
Q:Java-風-阿里:老師分散式事務玩過TCC嗎?
A:58沈劍老師:高併發的場景,基本不玩分散式事務,1秒幾十萬次的併發,分散式事務扛不住的。
Q:後端-陳醫生-北京:說的基因法和資料冗餘法,不是非常懂,尤其訂單那塊的基因法。請教一個對於分庫演算法的問題,在分庫演算法都有什麼?
A:58沈劍老師:今天介紹了,範圍法,hash法。hash法,最常見的是取模,網上討論最多的是一致性hash。強烈建議前者 ,取模就行。
閱讀更多