
JAVA JVM引數調優、以及回收器
[轉]JVM系列三:JVM引數設定、分析
不管是YGC還是Full GC,GC過程中都會對導致程式執行中中斷,正確的選擇不同的GC策略,調整JVM、GC的引數,可以極大的減少由於GC工作,而導致的程式執行中斷方面的問題,進而適當的提高Java程式的工作效率。但是調整GC是以個極為複雜的過程,由於各個程式具備不同的特點,如:web和GUI程式就有很大區別(Web可以適當的停頓,但GUI停頓是客戶無法接受的),而且由於跑在各個機器上的配置不同(主要cup個數,記憶體不同),所以使用的GC種類也會不同(如何選擇見GC種類及如何選擇)。本文將注重介紹JVM、GC的一些重要引數的設定來提高系統的效能。
JVM記憶體組成及GC相關內容請見之前的文章:JVM記憶體組成 GC策略&記憶體申請。
JVM引數的含義 例項見例項分析
| 引數名稱 | 含義 | 預設值 | |
| -Xms | 初始堆大小 | 實體記憶體的1/64(<1GB) | 預設(MinHeapFreeRatio引數可以調整)空餘堆記憶體小於40%時,JVM就會增大堆直到-Xmx的最大限制. |
| -Xmx | 最大堆大小 | 實體記憶體的1/4(<1GB) | 預設(MaxHeapFreeRatio引數可以調整)空餘堆記憶體大於70%時,JVM會減少堆直到 -Xms的最小限制 |
| -Xmn | 年輕代大小(1.4or lator) | 注意:此處的大小是(eden+ 2 survivor space).與jmap -heap中顯示的New gen是不同的。 整個堆大小=年輕代大小 + 年老代大小 + 持久代大小. 增大年輕代後,將會減小年老代大小.此值對系統性能影響較大,Sun官方推薦配置為整個堆的3/8 |
|
| -XX:NewSize | 設定年輕代大小(for 1.3/1.4) | ||
| -XX:MaxNewSize | 年輕代最大值(for 1.3/1.4) | ||
| -XX:PermSize | 設定持久代(perm gen)初始值 | 實體記憶體的1/64 | |
| -XX:MaxPermSize | 設定持久代最大值 | 實體記憶體的1/4 | |
| -Xss | 每個執行緒的堆疊大小 | JDK5.0以後每個執行緒堆疊大小為1M,以前每個執行緒堆疊大小為256K.更具應用的執行緒所需記憶體大小進行 調整.在相同實體記憶體下,減小這個值能生成更多的執行緒.但是作業系統對一個程序內的執行緒數還是有限制的,不能無限生成,經驗值在3000~5000左右 一般小的應用, 如果棧不是很深, 應該是128k夠用的 大的應用建議使用256k。這個選項對效能影響比較大,需要嚴格的測試。(校長) 和threadstacksize選項解釋很類似,官方文件似乎沒有解釋,在論壇中有這樣一句話:"” -Xss is translated in a VM flag named ThreadStackSize” 一般設定這個值就可以了。 |
|
| -XX:ThreadStackSize | Thread Stack Size | (0 means use default stack size) [Sparc: 512; Solaris x86: 320 (was 256 prior in 5.0 and earlier); Sparc 64 bit: 1024; Linux amd64: 1024 (was 0 in 5.0 and earlier); all others 0.] | |
| -XX:NewRatio | 年輕代(包括Eden和兩個Survivor區)與年老代的比值(除去持久代) | -XX:NewRatio=4表示年輕代與年老代所佔比值為1:4,年輕代佔整個堆疊的1/5 Xms=Xmx並且設定了Xmn的情況下,該引數不需要進行設定。 |
|
| -XX:SurvivorRatio | Eden區與Survivor區的大小比值 | 設定為8,則兩個Survivor區與一個Eden區的比值為2:8,一個Survivor區佔整個年輕代的1/10 | |
| -XX:LargePageSizeInBytes | 記憶體頁的大小不可設定過大, 會影響Perm的大小 | =128m | |
| -XX:+UseFastAccessorMethods | 原始型別的快速優化 | ||
| -XX:+DisableExplicitGC | 關閉System.gc() | 這個引數需要嚴格的測試 | |
| -XX:MaxTenuringThreshold | 垃圾最大年齡 | 如果設定為0的話,則年輕代物件不經過Survivor區,直接進入年老代. 對於年老代比較多的應用,可以提高效率.如果將此值設定為一個較大值,則年輕代物件會在Survivor區進行多次複製,這樣可以增加物件再年輕代的存活 時間,增加在年輕代即被回收的概率 該引數只有在序列GC時才有效. |
|
| -XX:+AggressiveOpts | 加快編譯 | ||
| -XX:+UseBiasedLocking | 鎖機制的效能改善 | ||
| -Xnoclassgc | 禁用垃圾回收 | ||
| -XX:SoftRefLRUPolicyMSPerMB | 每兆堆空閒空間中SoftReference的存活時間 | 1s | softly reachable objects will remain alive for some amount of time after the last time they were referenced. The default value is one second of lifetime per free megabyte in the heap |
| -XX:PretenureSizeThreshold | 物件超過多大是直接在舊生代分配 | 0 | 單位位元組 新生代採用Parallel Scavenge GC時無效 另一種直接在舊生代分配的情況是大的陣列物件,且陣列中無外部引用物件. |
| -XX:TLABWasteTargetPercent | TLAB佔eden區的百分比 | 1% | |
| -XX:+CollectGen0First | FullGC時是否先YGC | false |
並行收集器相關引數
| -XX:+UseParallelGC | Full GC採用parallel MSC (此項待驗證) |
選擇垃圾收集器為並行收集器.此配置僅對年輕代有效.即上述配置下,年輕代使用併發收集,而年老代仍舊使用序列收集.(此項待驗證) |
|
| -XX:+UseParNewGC | 設定年輕代為並行收集 | 可與CMS收集同時使用 JDK5.0以上,JVM會根據系統配置自行設定,所以無需再設定此值 |
|
| -XX:ParallelGCThreads | 並行收集器的執行緒數 | 此值最好配置與處理器數目相等 同樣適用於CMS | |
| -XX:+UseParallelOldGC | 年老代垃圾收集方式為並行收集(Parallel Compacting) | 這個是JAVA 6出現的引數選項 | |
| -XX:MaxGCPauseMillis | 每次年輕代垃圾回收的最長時間(最大暫停時間) | 如果無法滿足此時間,JVM會自動調整年輕代大小,以滿足此值. | |
| -XX:+UseAdaptiveSizePolicy | 自動選擇年輕代區大小和相應的Survivor區比例 | 設定此選項後,並行收集器會自動選擇年輕代區大小和相應的Survivor區比例,以達到目標系統規定的最低相應時間或者收集頻率等,此值建議使用並行收集器時,一直開啟. | |
| -XX:GCTimeRatio | 設定垃圾回收時間佔程式執行時間的百分比 | 公式為1/(1+n) | |
| -XX:+ScavengeBeforeFullGC | Full GC前呼叫YGC | true | Do young generation GC prior to a full GC. (Introduced in 1.4.1.) |
CMS相關引數
| -XX:+UseConcMarkSweepGC | 使用CMS記憶體收集 | 測試中配置這個以後,-XX:NewRatio=4的配置失效了,原因不明.所以,此時年輕代大小最好用-Xmn設定.??? | |
| -XX:+AggressiveHeap | 試圖是使用大量的實體記憶體 長時間大記憶體使用的優化,能檢查計算資源(記憶體, 處理器數量) 至少需要256MB記憶體 大量的CPU/記憶體, (在1.4.1在4CPU的機器上已經顯示有提升) |
||
| -XX:CMSFullGCsBeforeCompaction | 多少次後進行記憶體壓縮 | 由於併發收集器不對記憶體空間進行壓縮,整理,所以執行一段時間以後會產生"碎片",使得執行效率降低.此值設定執行多少次GC以後對記憶體空間進行壓縮,整理. | |
| -XX:+CMSParallelRemarkEnabled | 降低標記停頓 | ||
| -XX+UseCMSCompactAtFullCollection | 在FULL GC的時候, 對年老代的壓縮 | CMS是不會移動記憶體的, 因此, 這個非常容易產生碎片, 導致記憶體不夠用, 因此, 記憶體的壓縮這個時候就會被啟用。 增加這個引數是個好習慣。 可能會影響效能,但是可以消除碎片 |
|
| -XX:+UseCMSInitiatingOccupancyOnly | 使用手動定義初始化定義開始CMS收集 | 禁止hostspot自行觸發CMS GC | |
| -XX:CMSInitiatingOccupancyFraction=70 | 使用cms作為垃圾回收 使用70%後開始CMS收集 |
92 | 為了保證不出現promotion failed(見下面介紹)錯誤,該值的設定需要滿足以下公式CMSInitiatingOccupancyFraction計算公式 |
| -XX:CMSInitiatingPermOccupancyFraction | 設定Perm Gen使用到達多少比率時觸發 | 92 | |
| -XX:+CMSIncrementalMode | 設定為增量模式 | 用於單CPU情況 | |
| -XX:+CMSClassUnloadingEnabled |
輔助資訊
| -XX:+PrintGC | 輸出形式: [GC 118250K->113543K(130112K), 0.0094143 secs] |
||
| -XX:+PrintGCDetails | 輸出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] |
||
| -XX:+PrintGCTimeStamps | |||
| -XX:+PrintGC:PrintGCTimeStamps | 可與-XX:+PrintGC -XX:+PrintGCDetails混合使用 輸出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs] |
||
| -XX:+PrintGCApplicationStoppedTime | 列印垃圾回收期間程式暫停的時間.可與上面混合使用 | 輸出形式:Total time for which application threads were stopped: 0.0468229 seconds | |
| -XX:+PrintGCApplicationConcurrentTime | 列印每次垃圾回收前,程式未中斷的執行時間.可與上面混合使用 | 輸出形式:Application time: 0.5291524 seconds | |
| -XX:+PrintHeapAtGC | 列印GC前後的詳細堆疊資訊 | ||
| -Xloggc:filename | 把相關日誌資訊記錄到檔案以便分析. 與上面幾個配合使用 |
||
| -XX:+PrintClassHistogram |
garbage collects before printing the histogram. | ||
| -XX:+PrintTLAB | 檢視TLAB空間的使用情況 | ||
| XX:+PrintTenuringDistribution | 檢視每次minor GC後新的存活週期的閾值 | Desired survivor size 1048576 bytes, new threshold 7 (max 15) |
GC效能方面的考慮
對於GC的效能主要有2個方面的指標:吞吐量throughput(工作時間不算gc的時間佔總的時間比)和暫停pause(gc發生時app對外顯示的無法響應)。
1. Total Heap
預設情況下,vm會增加/減少heap大小以維持free space在整個vm中佔的比例,這個比例由MinHeapFreeRatio和MaxHeapFreeRatio指定。
一般而言,server端的app會有以下規則:
- 對vm分配儘可能多的memory;
- 將Xms和Xmx設為一樣的值。如果虛擬機器啟動時設定使用的記憶體比較小,這個時候又需要初始化很多物件,虛擬機器就必須重複地增加記憶體。
- 處理器核數增加,記憶體也跟著增大。
2. The Young Generation
另外一個對於app流暢性執行影響的因素是young generation的大小。young generation越大,minor collection越少;但是在固定heap size情況下,更大的young generation就意味著小的tenured generation,就意味著更多的major collection(major collection會引發minor collection)。
NewRatio反映的是young和tenured generation的大小比例。NewSize和MaxNewSize反映的是young generation大小的下限和上限,將這兩個值設為一樣就固定了young generation的大小(同Xms和Xmx設為一樣)。
如果希望,SurvivorRatio也可以優化survivor的大小,不過這對於效能的影響不是很大。SurvivorRatio是eden和survior大小比例。
一般而言,server端的app會有以下規則:
- 首先決定能分配給vm的最大的heap size,然後設定最佳的young generation的大小;
- 如果heap size固定後,增加young generation的大小意味著減小tenured generation大小。讓tenured generation在任何時候夠大,能夠容納所有live的data(留10%-20%的空餘)。
經驗&&規則
- 年輕代大小選擇
- 響應時間優先的應用:儘可能設大,直到接近系統的最低響應時間限制(根據實際情況選擇).在此種情況下,年輕代收集發生的頻率也是最小的.同時,減少到達年老代的物件.
- 吞吐量優先的應用:儘可能的設定大,可能到達Gbit的程度.因為對響應時間沒有要求,垃圾收集可以並行進行,一般適合8CPU以上的應用.
- 避免設定過小.當新生代設定過小時會導致:1.YGC次數更加頻繁 2.可能導致YGC物件直接進入舊生代,如果此時舊生代滿了,會觸發FGC.
- 年老代大小選擇
- 響應時間優先的應用:年老代使用併發收集器,所以其大小需要小心設定,一般要考慮併發會話率和會話持續時間等一些引數.如果堆設定小了,可以會造成記憶體碎 片,高回收頻率以及應用暫停而使用傳統的標記清除方式;如果堆大了,則需要較長的收集時間.最優化的方案,一般需要參考以下資料獲得:
併發垃圾收集資訊、持久代併發收集次數、傳統GC資訊、花在年輕代和年老代回收上的時間比例。 - 吞吐量優先的應用:一般吞吐量優先的應用都有一個很大的年輕代和一個較小的年老代.原因是,這樣可以儘可能回收掉大部分短期物件,減少中期的物件,而年老代盡存放長期存活物件.
- 響應時間優先的應用:年老代使用併發收集器,所以其大小需要小心設定,一般要考慮併發會話率和會話持續時間等一些引數.如果堆設定小了,可以會造成記憶體碎 片,高回收頻率以及應用暫停而使用傳統的標記清除方式;如果堆大了,則需要較長的收集時間.最優化的方案,一般需要參考以下資料獲得:
- 較小堆引起的碎片問題
因為年老代的併發收集器使用標記,清除演算法,所以不會對堆進行壓縮.當收集器回收時,他會把相鄰的空間進行合併,這樣可以分配給較大的物件.但是,當堆空間較小時,執行一段時間以後,就會出現"碎片",如果併發收集器找不到足夠的空間,那麼併發收集器將會停止,然後使用傳統的標記,清除方式進行回收.如果出現"碎片",可能需要進行如下配置:
-XX:+UseCMSCompactAtFullCollection:使用併發收集器時,開啟對年老代的壓縮.
-XX:CMSFullGCsBeforeCompaction=0:上面配置開啟的情況下,這裡設定多少次Full GC後,對年老代進行壓縮 - 用64位作業系統,Linux下64位的jdk比32位jdk要慢一些,但是吃得記憶體更多,吞吐量更大
- XMX和XMS設定一樣大,MaxPermSize和MinPermSize設定一樣大,這樣可以減輕伸縮堆大小帶來的壓力
- 使用CMS的好處是用盡量少的新生代,經驗值是128M-256M, 然後老生代利用CMS並行收集, 這樣能保證系統低延遲的吞吐效率。 實際上cms的收集停頓時間非常的短,2G的記憶體, 大約20-80ms的應用程式停頓時間
- 系統停頓的時候可能是GC的問題也可能是程式的問題,多用jmap和jstack檢視,或者killall -3 java,然後檢視java控制檯日誌,能看出很多問題。(相關工具的使用方法將在後面的blog中介紹)
- 仔細瞭解自己的應用,如果用了快取,那麼年老代應該大一些,快取的HashMap不應該無限制長,建議採用LRU演算法的Map做快取,LRUMap的最大長度也要根據實際情況設定。
- 採用併發回收時,年輕代小一點,年老代要大,因為年老大用的是併發回收,即使時間長點也不會影響其他程式繼續執行,網站不會停頓
- JVM引數的設定(特別是 –Xmx –Xms –Xmn -XX:SurvivorRatio -XX:MaxTenuringThreshold等引數的設定沒有一個固定的公式,需要根據PV old區實際資料 YGC次數等多方面來衡量。為了避免promotion faild可能會導致xmn設定偏小,也意味著YGC的次數會增多,處理併發訪問的能力下降等問題。每個引數的調整都需要經過詳細的效能測試,才能找到特定應用的最佳配置。
promotion failed:
垃圾回收時promotion failed是個很頭痛的問題,一般可能是兩種原因產生,第一個原因是救助空間不夠,救助空間裡的物件還不應該被移動到年老代,但年輕代又有很多物件需要放入救助空間;第二個原因是年老代沒有足夠的空間接納來自年輕代的物件;這兩種情況都會轉向Full GC,網站停頓時間較長。
解決方方案一:
第一個原因我的最終解決辦法是去掉救助空間,設定-XX:SurvivorRatio=65536 -XX:MaxTenuringThreshold=0即可,第二個原因我的解決辦法是設定CMSInitiatingOccupancyFraction為某個值(假設70),這樣年老代空間到70%時就開始執行CMS,年老代有足夠的空間接納來自年輕代的物件。
解決方案一的改進方案:
又有改進了,上面方法不太好,因為沒有用到救助空間,所以年老代容易滿,CMS執行會比較頻繁。我改善了一下,還是用救助空間,但是把救助空間加大,這樣也不會有promotion failed。具體操作上,32位Linux和64位Linux好像不一樣,64位系統似乎只要配置MaxTenuringThreshold引數,CMS還是有暫停。為了解決暫停問題和promotion failed問題,最後我設定-XX:SurvivorRatio=1 ,並把MaxTenuringThreshold去掉,這樣即沒有暫停又不會有promotoin failed,而且更重要的是,年老代和永久代上升非常慢(因為好多物件到不了年老代就被回收了),所以CMS執行頻率非常低,好幾個小時才執行一次,這樣,伺服器都不用重啟了。
-Xmx4000M -Xms4000M -Xmn600M -XX:PermSize=500M -XX:MaxPermSize=500M -Xss256K -XX:+DisableExplicitGC -XX:SurvivorRatio=1 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:LargePageSizeInBytes=128M -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:log/gc.log
CMSInitiatingOccupancyFraction值與Xmn的關係公式
上面介紹了promontion faild產生的原因是EDEN空間不足的情況下將EDEN與From survivor中的存活物件存入To survivor區時,To survivor區的空間不足,再次晉升到old gen區,而old gen區記憶體也不夠的情況下產生了promontion faild從而導致full gc.那可以推斷出:eden+from survivor < old gen區剩餘記憶體時,不會出現promontion faild的情況,即:
(Xmx-Xmn)*(1-CMSInitiatingOccupancyFraction/100)>=(Xmn-Xmn/(SurvivorRatior+2)) 進而推斷出:
CMSInitiatingOccupancyFraction <=((Xmx-Xmn)-(Xmn-Xmn/(SurvivorRatior+2)))/(Xmx-Xmn)*100
例如:
當xmx=128 xmn=36 SurvivorRatior=1時 CMSInitiatingOccupancyFraction<=((128.0-36)-(36-36/(1+2)))/(128-36)*100 =73.913
當xmx=128 xmn=24 SurvivorRatior=1時 CMSInitiatingOccupancyFraction<=((128.0-24)-(24-24/(1+2)))/(128-24)*100=84.615…
當xmx=3000 xmn=600 SurvivorRatior=1時 CMSInitiatingOccupancyFraction<=((3000.0-600)-(600-600/(1+2)))/(3000-600)*100=83.33
CMSInitiatingOccupancyFraction低於70% 需要調整xmn或SurvivorRatior值。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
垃圾收集器
垃圾收集器就是上面講的理論知識的具體實現了。不同虛擬機器所提供的垃圾收集器可能會有很大差別,我們使用的是HotSpot,HotSpot這個虛擬機器所包含的所有收集器如圖:

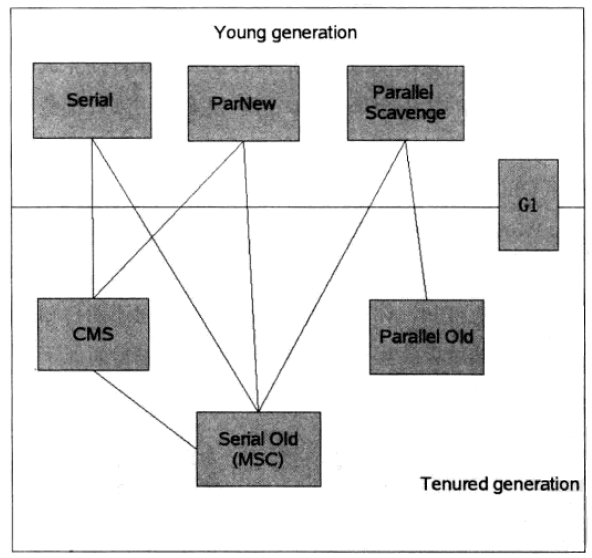
上圖展示了7種作用於不同分代的收集器,如果兩個收集器之間存在連線,那說明它們可以搭配使用。虛擬機器所處的區域說明它是屬於新生代收集器還是老年代收集器。多說一句,我們必須要明白一個道理:沒有最好的垃圾收集器,更加沒有萬能的收集器,只能選擇對具體應用最合適的收集器。這也是HotSpot為什麼要實現這麼多收集器的原因。OK,下面一個一個看一下收集器:
1、Serial收集器
最基本、發展歷史最久的收集器,這個收集器是一個採用複製演算法的單執行緒的收集器,單執行緒一方面意味著它只會使用一個CPU或一條執行緒去完成垃圾收集工作,另一方面也意味著它進行垃圾收集時必須暫停其他執行緒的所有工作,直到它收集結束為止。後者意味著,在使用者不可見的情況下要把使用者正常工作的執行緒全部停掉,這對很多應用是難以接受的。不過實際上到目前為止,Serial收集器依然是虛擬機器執行在Client模式下的預設新生代收集器,因為它簡單而高效。使用者桌面應用場景中,分配給虛擬機器管理的記憶體一般來說不會很大,收集幾十兆甚至一兩百兆的新生代停頓時間在幾十毫秒最多一百毫秒,只要不是頻繁發生,這點停頓是完全可以接受的。
2、ParNew收集器
ParNew收集器其實就是Serial收集器的多執行緒版本,除了使用多條執行緒進行垃圾收集外,其餘行為和Serial收集器完全一樣,包括使用的也是複製演算法。ParNew收集器除了多執行緒以外和Serial收集器並沒有太多創新的地方,但是它卻是Server模式下的虛擬機器首選的新生代收集器,其中有一個很重要的和效能無關的原因是,除了Serial收集器外,目前只有它能與CMS收集器配合工作(看圖)。CMS收集器是一款幾乎可以認為有劃時代意義的垃圾收集器,因為它第一次實現了讓垃圾收集執行緒與使用者執行緒基本上同時工作。ParNew收集器在單CPU的環境中絕對不會有比Serial收集器更好的效果,甚至由於執行緒互動的開銷,該收集器在兩個CPU的環境中都不能百分之百保證可以超越Serial收集器。當然,隨著可用CPU數量的增加,它對於GC時系統資源的有效利用還是很有好處的。它預設開啟的收集執行緒數與CPU數量相同,在CPU數量非常多的情況下,可以使用-XX:ParallelGCThreads引數來限制垃圾收集的執行緒數。
3、Parallel收集器
Parallel收集器也是一個新生代收集器,也是用複製演算法的收集器,也是並行的多執行緒收集器,但是它的特點是它的關注點和其他收集器不同。介紹這個收集器主要還是介紹吞吐量的概念。CMS等收集器的關注點是儘可能縮短垃圾收集時使用者執行緒的停頓時間,而Parallel收集器的目標則是打到一個可控制的吞吐量。所謂吞吐量的意思就是CPU用於執行使用者程式碼時間與CPU總消耗時間的比值,即吞吐量=執行使用者程式碼時間/(執行使用者程式碼時間+垃圾收集時間),虛擬機器總執行100分鐘,垃圾收集1分鐘,那吞吐量就是99%。另外,Parallel收集器是虛擬機器執行在Server模式下的預設垃圾收集器。
停頓時間短適合需要與使用者互動的程式,良好的響應速度能提升使用者體驗;高吞吐量則可以高效率利用CPU時間,儘快完成運算任務,主要適合在後臺運算而不需要太多互動的任務。
虛擬機器提供了-XX:MaxGCPauseMillis和-XX:GCTimeRatio兩個引數來精確控制最大垃圾收集停頓時間和吞吐量大小。不過不要以為前者越小越好,GC停頓時間的縮短是以犧牲吞吐量和新生代空間換取的。由於與吞吐量關係密切,Parallel收集器也被稱為“吞吐量優先收集器”。Parallel收集器有一個-XX:+UseAdaptiveSizePolicy引數,這是一個開關引數,這個引數開啟之後,就不需要手動指定新生代大小、Eden區和Survivor引數等細節引數了,虛擬機器會根據當親系統的執行情況手機效能監控資訊,動態調整這些引數以提供最合適的停頓時間或者最大的吞吐量。如果對於垃圾收集器運作原理不太瞭解,以至於在優化比較困難的時候,使用Parallel收集器配合自適應調節策略,把記憶體管理的調優任務交給虛擬機器去完成將是一個不錯的選擇。
4、Serial Old收集器
Serial收集器的老年代版本,同樣是一個單執行緒收集器,使用“標記-整理演算法”,這個收集器的主要意義也是在於給Client模式下的虛擬機器使用。
5、Parallel Old收集器
Parallel收集器的老年代版本,使用多執行緒和“標記-整理”演算法。這個收集器在JDK 1.6之後的出現,“吞吐量優先收集器”終於有了比較名副其實的應用組合,在注重吞吐量以及CPU資源敏感的場合,都可以優先考慮Parallel收集器+Parallel Old收集器的組合。
6、CMS收集器
CMS收集器是一種以獲取最短回收停頓時間為目標的老年代收集器。目前很大一部分Java應用集中在網際網路站或者B/S系統的服務端上,這類應用尤其注重服務的響應速度,希望系統停頓時間最短,以給使用者帶來較好的體驗,CMS收集器就非常符合這類應用的需求。CMS收集器從名字就能看出是基於“標記-清除”演算法實現的。
7、G1收集器
G1(Garbage-First)收集器是當今收集器技術發展的最前沿成果之一,JDK 7 Update 4後開始進入商用。在G1收集器之前的其他收集器進行收集的範圍都是整個新生代或者老年代,而G1收集器不再是這樣,使用G1收集器時,Java堆的記憶體佈局就與其他收集器有很大差別,它將整個Java堆分為多個大小相等的獨立區域(Region),雖然還保留有新生代和老年代的概念,但新生代和老年代不再是物理隔離的了,它們都是一部分Region的集合。G1收集器跟蹤各個Region裡面的垃圾堆積的價值大小,在後臺維護一個優先列表,每次根據允許的收集時間,優先回收價值最大的Region(這也是Garbage-First名稱的由來)。這種使用Region劃分記憶體空間以及有優先順序的區域回收方式,保證了G1收集器在有限的時間內可以獲取儘可能高的收集效率。
垃圾收集器總結
來看一下對垃圾收集器的總結,列了一張表
| GC組合 | Minor GC | Full GC | 描述 |
| -XX:+UseSerialGC | Serial收集器序列回收 | Serial Old收集器序列回收 | 該選項可以手動指定Serial收集器+Serial Old收集器組合執行記憶體回收 |
| -XX:+UseParNewGC | ParNew收集器並行回收 | Serial Old收集器序列回收 | 該選項可以手動指定ParNew收集器+Serilal Old組合執行記憶體回收 |
| -XX:+UseParallelGC | Parallel收集器並行回收 | Serial Old收集器序列回收 | 該選項可以手動指定Parallel收集器+Serial Old收集器組合執行記憶體回收 |
| -XX:+UseParallelOldGC | Parallel收集器並行回收 | Parallel Old收集器並行回收 | 該選項可以手動指定Parallel收集器+Parallel Old收集器組合執行記憶體回收 |
| -XX:+UseConcMarkSweepGC | ParNew收集器並行回收 | 預設使用CMS收集器併發回收,備用採用Serial Old收集器序列回收 | 該選項可以手動指定ParNew收集器+CMS收集器+Serial Old收集器組合執行記憶體回收。優先使用ParNew收集器+CMS收集器的組合,當出現ConcurrentMode Fail或者Promotion Failed時,則採用ParNew收集器+Serial Old收集器的組合 |
| -XX:+UseConcMarkSweepGC-XX:-UseParNewGC | Serial收集器序列回收 | ||
| -XX:+UseG1GC | G1收集器併發、並行執行記憶體回收 | 暫無 | |
GC日誌
每種收集器的日誌形式都是由它們自身的實現所決定的,換言之,每種收集器的日誌格式都可以不一樣。不過虛擬機器為了方便使用者閱讀,將各個收集器的日誌都維持了一定的共性,就以最前面的物件間相互引用的那個類ReferenceCountingGC的程式碼為例:
虛擬機器引數為“-XX:+PrintGCDetails -XX:+UseSerialGC”,使用Serial+Serial Old組合進行垃圾回收的日誌
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
虛擬機器引數為“-XX:+PrintGCDetails -XX:+UseParNewGC”,使用ParNew+Serial Old組合進行垃圾回收的日誌
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
虛擬機器引數為“-XX:+PrintGCDetails -XX:+UseParallelGC”,使用Parallel+Serial Old組合進行垃圾回收的日誌
| 1 2 3 4 5 6 7 8 9 10 11 |
|
虛擬機器引數為“-XX:+PrintGCDetails -XX:+UseConcMarkSweepGC”,使用ParNew+CMS+Serial Old組合進行垃圾回收的日誌
| 1 2 3 4 5 6 7 8 |
|
這四段GC日誌中提煉出一些共性:
1、日誌的開頭“GC”、“Full GC”表示這次垃圾收集的停頓型別,而不是用來區分新生代GC還是老年代GC的。如果有Full,則說明本次GC停止了其他所有工作執行緒。看到Full GC的寫法是“Full GC(System)”,這說明是呼叫System.gc()方法所觸發的GC。
2、“GC”中接下來的“DefNew”、“ParNew”、“PSYoungGen”、“CMS”表示的是老年代垃圾收集器的名稱,“PSYoungGen”中的“PS”指的是“Parallel Scavenge”,它是Parallel收集器的全稱。
3、以第一個為例,方括號內部的“320K->194K(2368K)”、“2242K->0K(2368K)”,指的是該區域已使用的容量->GC後該記憶體區域已使用的容量(該記憶體區總容量)。方括號外面的“310K->194K(7680K)”、“2242K->2241K(7680K)”則指的是GC前Java堆已使用的容量->GC後Java堆已使用的容量(Java堆總容量)。
4、還以第一個為例,再往後“0.0269163 secs”表示該記憶體區域GC所佔用的時間,單位是秒。最後的“[Times: user=0.00 sys=0.00 real=0.03 secs]”則更具體了,user表示使用者態消耗的CPU時間、核心態消耗的CPU時間、操作從開始到結束經過的鐘牆時間。後面兩個的區別是,鍾牆時間包括各種非運算的等待消耗,比如等待磁碟I/O、等待執行緒阻塞,而CPU時間不包括這些耗時,但當系統有多CPU或者多核的話,多執行緒操作會疊加這些CPU時間所以如果user或sys超過real是完全正常的。
5、“Heap”後面就列舉出堆記憶體目前各個年代的區域的記憶體情況
觸發GC的時機
最後總結一下什麼時候會觸發一次GC,個人經驗看,有三種場景會觸發GC:
1、第一種場景應該很明顯,當年輕代或者老年代滿了,Java虛擬機器無法再為新的物件分配記憶體空間了,那麼Java虛擬機器就會觸發一次GC去回收掉那些已經不會再被使用到的物件
2、手動呼叫System.gc()方法,通常這樣會觸發一次的Full GC以及至少一次的Minor GC
3、程式執行的時候有一條低優先順序的GC執行緒,它是一條守護執行緒,當這條執行緒處於執行狀態的時候,自然就觸發了一次GC了。這點也很好證明,不過要用到WeakReference的知識,後面寫WeakReference的時候會專門講到這個。