
3行程式碼,Python資料預處理提速6倍!

來源:towardsdatascience
作者:George Seif
編輯:肖琴

讓CPU核心物盡其用!本文介紹了僅需3行程式碼,將Python資料處理速度提升2~6倍的簡單方法。
Python是所有機器學習的首選程式語言。它易於使用,並擁有許多很棒的庫,可以輕鬆地處理資料。但是當我們需要處理大量資料時,事情就變得棘手了......
“大資料”這個詞通常指的是資料集,一個數據集裡的資料點如果沒有數百萬個,也有數十萬。在這樣的規模上,每個小的計算加起來,而且我們需要在編碼過程的每個步驟保持效率。在考慮機器學習系統的效率時,經常被忽視的一個關鍵步驟就是預處理階段,我們必須對所有資料點進行某種預處理操作。
預設情況下,Python程式使用單個CPU作為單個程序執行。大多數用於機器學習的計算機至少有2個CPU核心。這意味著,對於2個CPU核心的示例,在執行預處理時,50%或更多的計算機處理能力在預設情況下不會做任何事情!當你使用4核( Intel i5)或6核( Intel i7)時,就更浪費了。
但幸運的是,內建的Python庫中有一些隱藏的功能,可以讓我們充分利用所有CPU核心!感謝Python的concurrent.futures模組,只需3行程式碼就可以將一個普通程式轉換為一個可以跨CPU核心並行處理資料的程式。

標準方法
讓我們舉一個簡單的例子,我們在一個資料夾中有一個影象資料集; 或者我們甚至有成千上萬的影象!為了節省處理時間,我們在這裡使用1000張影象。我們希望在將所有影象在傳輸到深度神經網路之前將其大小調整為600x600。下面就是你經常在GitHub上看到的一些非常標準的Python程式碼。
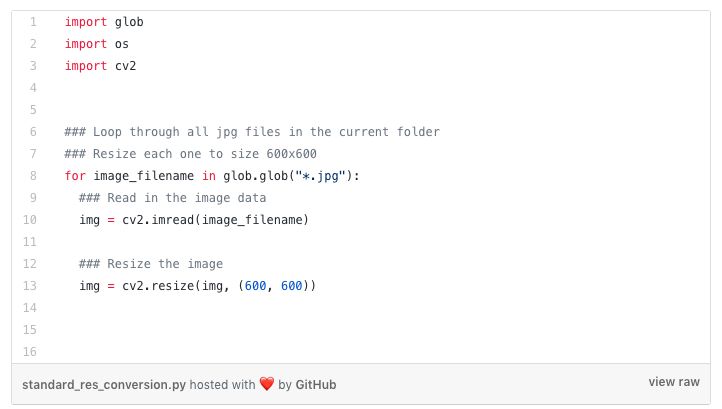
這個程式遵循在資料處理指令碼中經常看到的簡單模式:
- 首先是要處理的檔案(或其他資料)列表;
- 你可以使用for迴圈逐個處理每個資料片段,然後在每個迴圈迭代上執行預處理
讓我們在一個包含1000個jpeg檔案的資料夾上測試這個程式,看看執行需要多長時間:

在我的具有6個CPU核心的i7-8700k上,這個程式的執行時間是7.9864秒!對於這樣的高階CPU來說,似乎有點慢。讓我們看看我們可以做些什麼來加快速度。
快速方式
為了理解我們希望Python如何並行處理事物,直觀地思考並行處理本身是有幫助的。假設我們必須執行相同的任務,例如將釘子釘入一塊木頭,我們的桶中有1000個釘子。如果釘每個釘子需要1秒鐘,那麼1個人的話需要花1000秒完成工作。但是如果有4個人,我們會將整桶釘子平均分成4堆,然後每個人處理自己的一堆釘子。這樣,只需250秒即可完成任務!
在這個包含1000張影象的任務中,也可以這樣處理:
- 將jpg檔案列表分為4個較小的組。
- 執行Python直譯器的4個獨立例項。
- 讓每個Python例項處理4個較小資料組中的一個。
- 結合4個過程的結果,得到最終的結果列表。
這裡最重要的部分是Python為我們處理了所有艱苦的工作。我們只是告訴它我們想要執行哪個函式,以及使用多少Python例項,然後它完成了所有其他操作!我們只需修改3行程式碼。
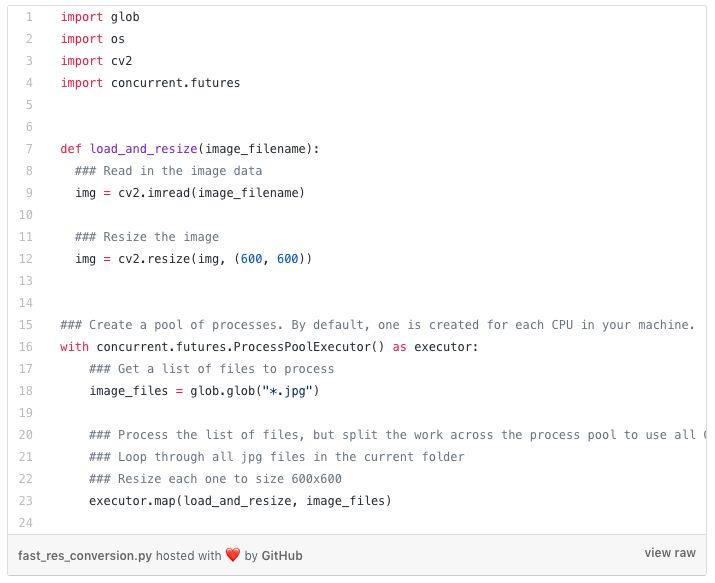
上面的程式碼中的:

你有多少CPU核心就啟動多少Python程序,在我的例子中是6個。實際的處理程式碼是這樣的:
executor.map()將你想要執行的函式和一個列表作為輸入,列表中的每個元素都是函式的單個輸入。由於我們有6個核心,我們將同時處理列表中的6個項!
再次執行程式看看:
執行時間是1.14265秒,幾乎加速了6倍!
注意:產生更多Python程序並在它們之間移動資料時,會產生一些開銷,因此不會總是得到這麼大的速度提升。 但總的來說,加速相當顯著。
是否總能大幅加速?
當你有要處理的資料列表並且要對每個資料點執行類似的計算時,使用Python並行池是一個很好的解決方案。但是,它並不總是完美的。並行池處理的資料不會以任何可預測的順序處理。如果你需要處理的結果按特定順序排列,那麼這種方法可能不適合。
你處理的資料還必須是Python知道如何“pickle”的型別。幸運的是,這些型別很常見。以下來自Python官方文件:
- None, True, 及 False
- 整數,浮點數,複數
- 字串,位元組,位元組陣列
- 僅包含可選物件的元組,列表,集合和詞典
- 在模組的頂層定義的函式(使用def,而不是lambda)
- 在模組頂層定義的內建函式
- 在模組頂層定義的類
- 這些類的例項,__dict__或呼叫__getstate __()的結果是可選擇的