
強化學習(十二) Dueling DQN 強化學習(十一) Prioritized Replay DQN
在強化學習(十一) Prioritized Replay DQN中,我們討論了對DQN的經驗回放池按權重取樣來優化DQN演算法的方法,本文討論另一種優化方法,Dueling DQN。本章內容主要參考了ICML 2016的deep RL tutorial和Dueling DQN的論文<Dueling Network Architectures for Deep Reinforcement Learning>(ICML 2016)。
1. Dueling DQN的優化點考慮
在前面講到的DDQN中,我們通過優化目標Q值的計算來優化演算法,在Prioritized Replay DQN中,我們通過優化經驗回放池按權重取樣來優化演算法。而在Dueling DQN中,我們嘗試通過優化神經網路的結構來優化演算法。
具體如何優化網路結構呢?Dueling DQN考慮將Q網路分成兩部分,第一部分是僅僅與狀態$S$有關,與具體要採用的動作$A$無關,這部分我們叫做價值函式部分,記做$V(S,w,\alpha)$,第二部分同時與狀態狀態$S$和動作$A$有關,這部分叫做優勢函式(Advantage Function)部分,記為$A(S,A,w,\beta)$,那麼最終我們的價值函式可以重新表示為:$$Q(S,A, w, \alpha, \beta) = V(S,w,\alpha) + A(S,A,w,\beta)$$
其中,$w$是公共部分的網路引數,而$\alpha$是價值函式獨有部分的網路引數,而$\beta$是優勢函式獨有部分的網路引數。
2. Dueling DQN網路結構
由於Q網路的價值函式被分為兩部分,因此Dueling DQN的網路結構也和之前的DQN不同。為了簡化演算法描述,這裡不使用原論文的CNN網路結構,而是使用前面文中用到的最簡單的三層神經網路來描述。是否使用CNN對Dueling DQN演算法本身無影響。
在前面講到的DDQN等DQN演算法中,我使用了一個簡單的三層神經網路:一個輸入層,一個隱藏層和一個輸出層。如下左圖所示:
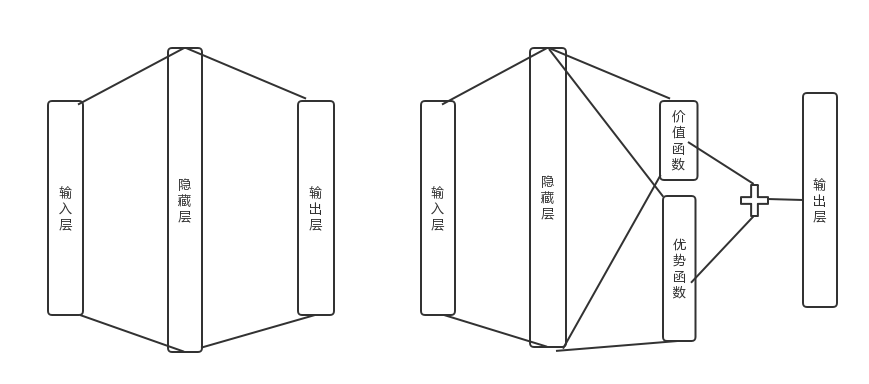
而在Dueling DQN中,我們在後面加了兩個子網路結構,分別對應上面上到價格函式網路部分和優勢函式網路部分。對應上面右圖所示。最終Q網路的輸出由價格函式網路的輸出和優勢函式網路的輸出線性組合得到。
我們可以直接使用上一節的價值函式的組合公式得到我們的動作價值,但是這個式子無法辨識最終輸出裡面$V(S,w,\alpha)$和$A(S,A,w,\beta)$各自的作用,為了可以體現這種可辨識性(identifiability),實際使用的組合公式如下:$$Q(S,A, w, \alpha, \beta) = V(S,w,\alpha) + (A(S,A,w,\beta) - \frac{1}{\mathcal{A}}\sum\limits_{a' \in \mathcal{A}}A(S,a', w,\beta))$$
其實就是對優勢函式部分做了中心化的處理。以上就是Duel DQN的主要演算法思路。由於它僅僅涉及神經網路的中間結構的改進,現有的DQN演算法可以在使用Duel DQN網路結構的基礎上繼續使用現有的演算法。由於演算法主流程和其他演算法沒有差異,這裡就單獨講Duel DQN的演算法流程了。
3. Dueling DQN例項
下面我們用一個具體的例子來演示Dueling DQN的應用。仍然使用了OpenAI Gym中的CartPole-v0遊戲來作為我們演算法應用。CartPole-v0遊戲的介紹參見這裡。它比較簡單,基本要求就是控制下面的cart移動使連線在上面的pole保持垂直不倒。這個任務只有兩個離散動作,要麼向左用力,要麼向右用力。而state狀態就是這個cart的位置和速度, pole的角度和角速度,4維的特徵。堅持到200分的獎勵則為過關。
這個例項代基於Nature DQN,並將網路結構改為上圖中右邊的Dueling DQN網路結構,完整的程式碼參見我的github: https://github.com/ljpzzz/machinelearning/blob/master/reinforcement-learning/duel_dqn.py
這裡我們重點關注Dueling DQN和Nature DQN的程式碼的不同之處。也就是網路結構定義部分,主要的程式碼如下,一共有兩個相同結構的Q網路,每個Q網路都有狀態函式和優勢函式的定義,以及組合後的Q網路輸出,如程式碼紅色部分:
def create_Q_network(self): # input layer self.state_input = tf.placeholder("float", [None, self.state_dim]) # network weights with tf.variable_scope('current_net'): W1 = self.weight_variable([self.state_dim,20]) b1 = self.bias_variable([20]) # hidden layer 1 h_layer_1 = tf.nn.relu(tf.matmul(self.state_input,W1) + b1) # hidden layer for state value with tf.variable_scope('Value'): W21= self.weight_variable([20,1]) b21 = self.bias_variable([1]) self.V = tf.matmul(h_layer_1, W21) + b21 # hidden layer for action value with tf.variable_scope('Advantage'): W22 = self.weight_variable([20,self.action_dim]) b22 = self.bias_variable([self.action_dim]) self.A = tf.matmul(h_layer_1, W22) + b22 # Q Value layer self.Q_value = self.V + (self.A - tf.reduce_mean(self.A, axis=1, keep_dims=True)) with tf.variable_scope('target_net'): W1t = self.weight_variable([self.state_dim,20]) b1t = self.bias_variable([20]) # hidden layer 1 h_layer_1t = tf.nn.relu(tf.matmul(self.state_input,W1t) + b1t) # hidden layer for state value with tf.variable_scope('Value'): W2v = self.weight_variable([20,1]) b2v = self.bias_variable([1]) self.VT = tf.matmul(h_layer_1t, W2v) + b2v # hidden layer for action value with tf.variable_scope('Advantage'): W2a = self.weight_variable([20,self.action_dim]) b2a = self.bias_variable([self.action_dim]) self.AT = tf.matmul(h_layer_1t, W2a) + b2a # Q Value layer self.target_Q_value = self.VT + (self.AT - tf.reduce_mean(self.AT, axis=1, keep_dims=True))
其餘部分程式碼和Nature DQN基本相同。當然,我們可以也在前面DDQN,Prioritized Replay DQN程式碼的基礎上,把網路結構改成上面的定義,這樣Dueling DQN也可以起作用。
4. DQN總結
DQN系列我花了5篇來講解,一共5個前後有關聯的演算法:DQN(NIPS2013), Nature DQN, DDQN, Prioritized Replay DQN和Dueling DQN。目前使用的比較主流的是後面三種演算法思路,這三種演算法思路也是可以混著一起使用的,相互並不排斥。
當然DQN家族的演算法遠遠不止這些,還有一些其他的DQN演算法我沒有詳細介紹,比如使用一些較複雜的CNN和RNN網路來提高DQN的表達能力,又比如改進探索狀態空間的方法等,主要是在DQN的基礎上持續優化。
DQN算是深度強化學習的中的主流流派,代表了Value-Based這一大類深度強化學習演算法。但是它也有自己的一些問題,就是絕大多數DQN只能處理離散的動作集合,不能處理連續的動作集合。雖然NAF DQN可以解決這個問題,但是方法過於複雜了。而深度強化學習的另一個主流流派Policy-Based而可以較好的解決這個問題,從下一篇我們開始討論Policy-Based深度強化學習。
(歡迎轉載,轉載請註明出處。歡迎溝通交流: [email protected])