Spark學習筆記(三) Ubuntu搭建Hadoop分散式叢集
阿新 • • 發佈:2018-11-08
Ubuntu搭建Hadoop分散式叢集
- 執行環境
- 配置目標
- 搭建Hadoop分散式叢集步驟
- 1 搭建master
- 2 搭建node
- 2.1 從master克隆出node
- 2.2 設定master和node之間SSH通訊
- 2.2.1 在master上修改hostsname
- 2.2.2 在node1和node2上修改hostsname
- 2.2.3 修改host檔案
- 2.2.4 在master上生成ssh祕鑰
- 2.2.5 在node1和node2上生成ssh祕鑰
- 2.2.6 將所有node節點上的公鑰id_rsa.pub傳送到master上
- 2.2.7 在master上將node的公鑰放入authorized_keys檔案裡
- 2.2.8 將master上的authorized_keys 拷貝到node1和node2上
- 2.2.9 驗證master和node直接的免密碼登入
- 2.3 在master上修改Hadoop配置
- 2.3.1 core-site.xml
- 2.3.2 hdfs-site.xml
- 2.3.3 yarn-site.xml
- 2.3.4 mapred-site.xml
- 2.3.5 slaves檔案
- 2.3.6 hadoop-env.sh檔案
- 2.4 將master上的hadoop配置檔案同步到node
- 3 啟動Hadoop叢集
推薦一個好的翻譯官方文件網站 ( http://cwiki.apachecn.org/
執行環境
因為是為了學習,且只有一臺PC,只能在虛擬機器裡安裝Hadoop
| 軟體配置 | 版本 |
|---|---|
| 主機 | Win7,記憶體8G |
| 虛擬機器 | VMware 14 |
| Linux | ubuntu-14.04.5-desktop (使用ubuntu-18或16的話,電腦會比較卡) |
| Hadoop | 2.9.1 |
| JDK | 1.8 |
配置目標
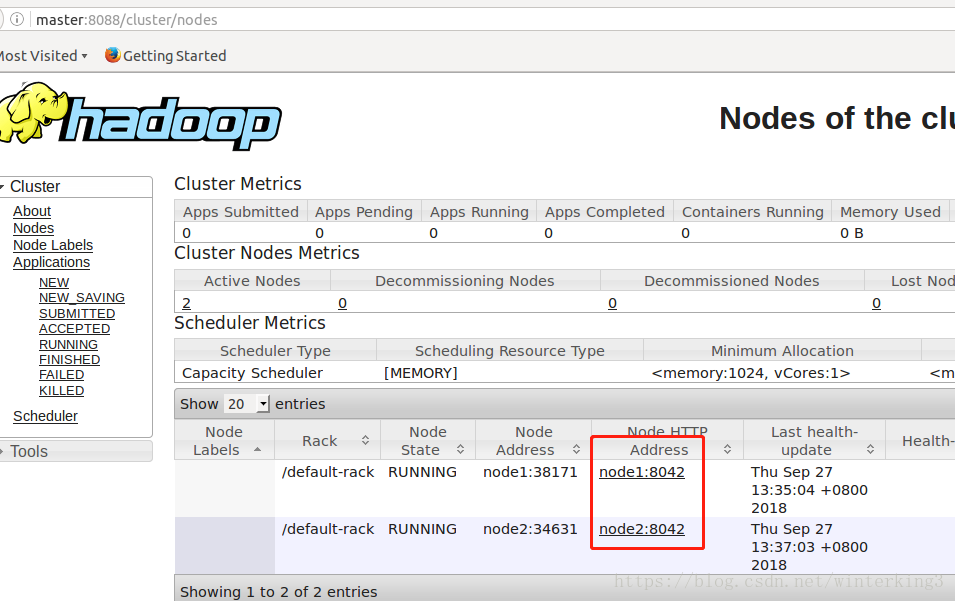
搭建一臺NameNode名稱為master,兩臺DataNode名稱分別為node1和node2。
搭建Hadoop分散式叢集步驟
1 搭建master
新建一個Ubuntu虛擬機器,命名為ubuntu_14_master。
如何在VMware裡安裝Ubuntu?,網上教程很多。
1.1 安裝JDK
安裝JDK的步驟參考之前的部落格Hadoop學習筆記(一) Ubuntu安裝JDK和ssh
1.2 安裝SSH
SSH的工作原理自行百度吧
#檢視ssh的狀態判斷是否已經安裝了ssh,如果返回ssh: unrecognized service,說明沒有安裝ssh
$ sudo service ssh status
#或者如下命令檢視是否有ssh的程序
$ sudo ps -e | grep ssh
#如果沒有安裝ssh,輸入如下2個命令安裝
# 1.下載最新的軟體列表
$ sudo apt-get update
# 2.Ubuntu預設沒有安裝SSH Server,安裝如下
$ sudo apt-get install openssh-server
#如果ssh沒有啟動,輸入下面命令啟動
$ sudo service ssh start
#Ubuntu14沒有在當前目錄開啟終端的選項,這個外掛裝下
$ sudo apt-get install nautilus-open-terminal
這時暫不生成祕鑰,等搭建好node後再生成
1.3 安裝Hadoop
安裝Hadoop參考之前的部落格Hadoop學習筆記(二) 安裝Hadoop單節點叢集
但是隻要操作到第2點配置.bashrc檔案就行,第3點修改Hadoop配置檔案的不用看
2 搭建node
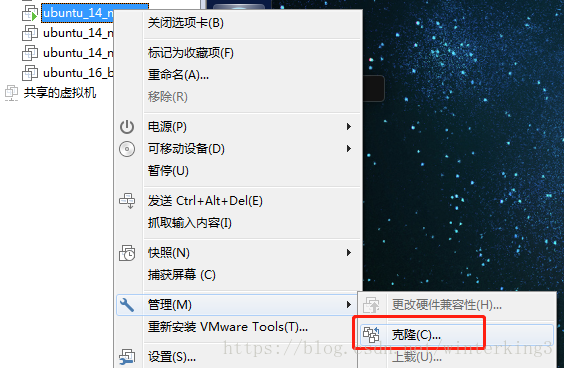
2.1 從master克隆出node
把master虛擬機器關機後,右擊master,選擇管理>克隆,並在下一步後選擇完整克隆
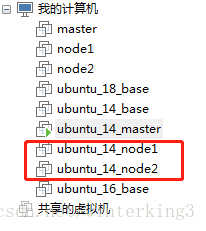
克隆出2個node虛擬機器,命名如下
2.2 設定master和node之間SSH通訊
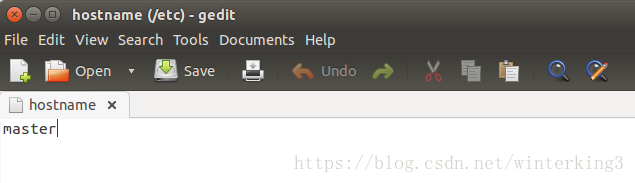
2.2.1 在master上修改hostsname
#在master上修改hostname,儲存為master
[email protected]:~$ sudo gedit /etc/hostname
2.2.2 在node1和node2上修改hostsname
node1和node2上修改hostname分別為node1和node2,步驟和上面master的一樣
2.2.3 修改host檔案
#檢視ip地址,下圖中紅框是ip
$ ifconfig
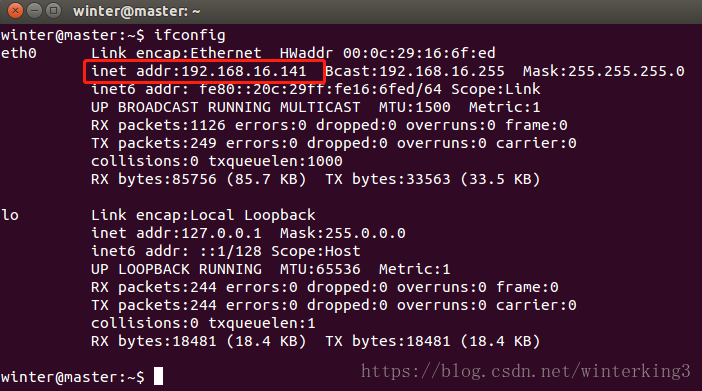
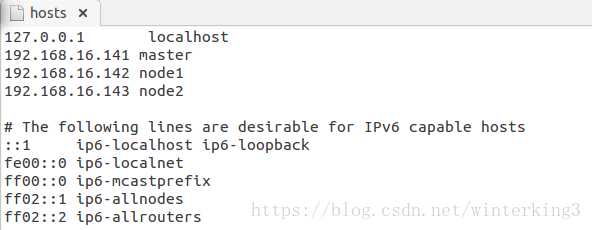
#3臺機器的ip都查詢好後,在3臺機器上都修改host檔案
$ sudo gedit /etc/hosts
2.2.4 在master上生成ssh祕鑰
#此操作是在master上,沒有.ssh資料夾就執行ssh localhost
# 1.產生SSH Key
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 2.將產生的SSH Key放到許可證檔案中
$ cat id_rsa.pub >> authorized_keys
# 3.驗證連線訪問自己,輸入密碼登入,輸入exit登出
$ ssh localhost
可以看出.ssh下面生成了幾個檔案
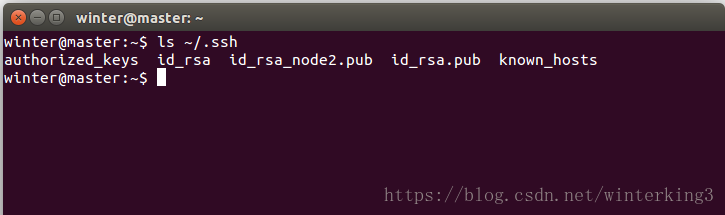
2.2.5 在node1和node2上生成ssh祕鑰
# 1.產生SSH Key,這個是在node上操作
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
2.2.6 將所有node節點上的公鑰id_rsa.pub傳送到master上
# 在node1上將公鑰拷貝到master上
[email protected]:~/.ssh$ scp id_rsa.pub [email protected]:~/.ssh/id_rsa_node1.pub
# 在node2上將公鑰拷貝到master上
[email protected]:~/.ssh$ scp id_rsa.pub [email protected]:~/.ssh/id_rsa_node2.pub
2.2.7 在master上將node的公鑰放入authorized_keys檔案裡
[email protected]:~/.ssh$ cat id_rsa_node1.pub >> authorized_keys
[email protected]:~/.ssh$ cat id_rsa_node2.pub >> authorized_keys
#之後要刪掉id_rsa_node1.pub和id_rsa_node2.pub
$ rm -rf id_rsa_node1.pub
$ rm -rf id_rsa_node2.pub
2.2.8 將master上的authorized_keys 拷貝到node1和node2上
# 在master上操作,winter是我的使用者名稱
$ scp authorized_keys [email protected]:~/.ssh/authorized_keys
$ scp authorized_keys [email protected]:~/.ssh/authorized_keys
2.2.9 驗證master和node直接的免密碼登入
登入後如果不用輸入密碼說明配置成功,登入別的機器後要輸入exit退出
#在master上
$ ssh node1
$ ssh node2
#在node1上
$ ssh master
$ ssh node2
#在node2上
$ ssh node1
$ ssh master
2.3 在master上修改Hadoop配置
2.3.1 core-site.xml
在hadoop目錄下新建tmp目錄,存放臨時檔案
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
2.3.2 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
2.3.3 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
2.3.4 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.3.5 slaves檔案
node1
node2
2.3.6 hadoop-env.sh檔案
# The java implementation to use.
export JAVA_HOME=/usr/lib/jdk/jdk1.8
2.4 將master上的hadoop配置檔案同步到node
以下是在master上操作
#在master上新建namenode
$ sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
$ sudo chown winter:winter -R /usr/local/hadoop
#在master上登入node1
[email protected]:~$ ssh node1
#新建datanode目錄
$ sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
# 將hadoop目錄的許可權給winter這個使用者
[email protected]:~$ sudo chown winter:winter -R /usr/local/hadoop
#退出node1
[email protected]:~$ exit
#拷貝配置檔案到node1
[email protected]:~$ scp -r /usr/local/hadoop/etc/hadoop/* [email protected]:/usr/local/hadoop/etc/hadoop
#node2和node1一樣操作
3 啟動Hadoop叢集
3.1格式化namenode
#格式化namenode目錄,就執行一次,以後啟動不要執行這條語句
[email protected]:~$ hadoop namenode -format
如果datanode程序沒有起來,報All specified directories are failed to load
參考 解決方法
3.2 啟動叢集
#啟動HDFS
$ start-dfs.sh
#啟動MapReduce框架 YARN
$ start-yarn.sh
3.3 關閉hadoop
#關閉程序
$ stop-dfs.sh
$ stop-yarn.sh
使用jps檢視程序,以上程序都已關閉