
java中的垃圾處理機制
目錄
一、出現的問題
在之前的章節中,已經提到,我們建立的物件在使用完之後不用擔心清理工作,因為java的垃圾回收機制已經自動幫助我們完成了。但是情況並不總是這樣,比如自己建立的物件獲得了一塊特殊的記憶體區域,由於垃圾回收機制只知道回收哪些由new關鍵字建立的物件,而不能釋放這個特殊物件該怎麼辦呢?舉個例子就是我們在輸入輸出操作的時候,打開了一個檔案,開啟檔案的這個物件就是特殊物件,java的垃圾回收器是不能將其回收的,那麼接下來該怎麼辦呢?
二、解決的方法。
為了解決上面的問題,java提供了一個finalize()方法,其工作原理是這樣的:一旦垃圾回收器要釋放物件所佔用的儲存空間時,首先呼叫finalize()方法,在下一次回收垃圾時才會回收這個物件佔用的記憶體。
注意:1、java的finalize()方法不等於C++的解構函式。
2、物件可能不被垃圾回收
3、垃圾回收並不等於析構
4、垃圾回收只與記憶體有關。
現在可以這樣說,只要程式沒有面臨著儲存空間被用完的那一刻,物件所佔用的空間就永遠不會得到釋放,那麼垃圾回收機制就一直沒有執行。java虛擬機器是不會浪費時間實質性垃圾回收以恢復記憶體的。
無論物件是誰建立的,垃圾回收器都只負責釋放物件佔據的所有記憶體。這句話說明finalize()呼叫的情況,只適合於特殊物件的清理,比如說打開了某一個檔案。
三、普通物件的垃圾回收機制是如何工作的?
下面的內容是在微信上找的,發現別人總結的已經很全面,自己看懂就好了。
在c/c++中,需要手動去釋放記憶體,這是一件很麻煩的事,很容易就出現記憶體洩露等問題了。在Java中,由JVM提供了垃圾回收機制,因此我們可以只關注物件的建立即可,無需關心物件不用時的回收問題。但是,由於我們寫程式碼時的不規範等,同樣也會造成記憶體洩露。因此,我們可以通過了解垃圾回收機制的原理來揭開記憶體洩露的原因。
1. 判斷哪些物件是垃圾
垃圾收集器在進行回收之前,需要判斷哪些物件是無用的,能夠進行回收的。判斷無用物件有兩種演算法:一種是引用計數演算法,另一種是可達性分析演算法。
1.1 引用計數演算法
引用計數演算法實際很簡單:給物件中新增一個引用計數器,每當有一個地方引用它時,計數器值加1;當引用失效時,計數器減1;任何時刻計數器都為0的物件就是不可能再被使用的。
但是,引用計數演算法有一個缺陷,就是無法解決物件之間相互迴圈引用的問題。比如:物件objA和objB都有欄位instance,賦值令objA.instance=objB及objB.instance=objA,除此之外這兩個物件再無任何引用,實際上這兩個物件都已經不能再被訪問,但是它們因為相互引用著對方,所以它們的引用計數都不為0,於是如果是使用引用計數演算法的話GC收集器就不會回收它們。程式碼如下所示:
public class ReferenceCountingGC {
private ReferenceCountingGC instance = null;
public static void main(String[] args) {
ReferenceCountingGC objA = new ReferenceCountingGC();
ReferenceCountingGC objB = new ReferenceCountingGC();
objA.instance = objB;
objB.instance = objA;
objA = null;
objB = null;
System.gc();
}
}
所以,主流的Java虛擬機器都不使用引用計數演算法來管理記憶體。
1.2 可達性分析演算法
這個演算法的基本思路就是通過一系列的稱為GC Roots的物件作為起始點,從這些節點開始向下搜尋,搜尋所走過的路徑稱為引用鏈(Reference Chain),當一個物件到GC Roots沒有任何引用鏈相連(用圖論的話來說,就是從GC Roots到這個物件不可達)時,則證明此物件是不可用的。如下圖所示,物件object 5、object 6、object 7雖然互相有關聯,但是它們到GC Roots是不可達的,所以它們將會被判定為是可回收的物件。
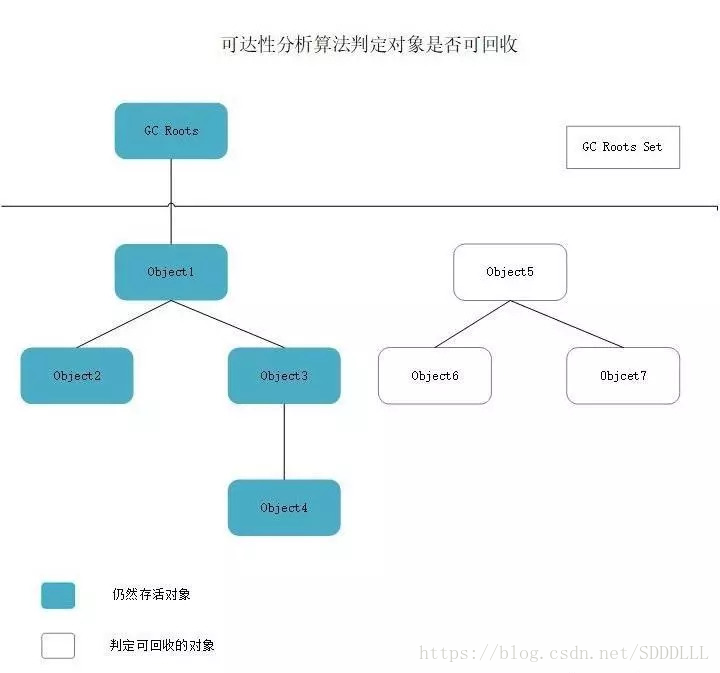
可達性分析演算法.jpg
在Java語言中,可作為GC Roots的物件包括下面幾種:
1.虛擬機器棧(棧幀中的本地變量表)中引用的物件。
2.方法區中類靜態屬性引用的物件。
3.方法區中常量引用的物件。
4.本地方法棧中JNI(即一般說的Native方法)引用的物件。
記憶體洩露就是無用的物件給其他地方意外的持有,導致其是可達的,因此判定它不是可回收的物件。
2. JVM堆模型/分代
JVM將堆分成了二個大區新生代(Young)和老年代(Old),新生代又被進一步劃分為Eden和Survivor區,而Survivor由FromSpace和ToSpace組成,也有些人把FromSpace和ToSpace叫成Survivor1和Survivor2。
如下圖所示:

堆空間.png
為什麼新生代還要分成三塊呢?這是因為新生代中98%的物件都是朝生夕死,所以將記憶體分為一塊較大的Eden和兩塊較小的Survivor1、Survivor2,JVM預設分配是8:1:1,每次使用Eden和其中的Survivor1(FromSpace),當發生回收的時候,將Eden和Survivor1(FromSpace)存活的物件複製到Survivor2(ToSpace),然後直接清理掉Eden和Survivor1的空間。
-
新生代
新建立的物件都是在新生代分配記憶體,Eden空間不足時,觸發Minor GC,這時會把存活的物件轉移進Survivor區。 -
老年代
老年代用於存放經過多次Minor GC之後依然存活的物件。 -
新生代的GC(
Minor GC)
新生代通常存活時間較短,其基於複製演算法進行回收。複製演算法就是掃描出存活的物件,然後複製到一塊新的完全未使用的空間中,對應於新生代,就是在Eden和FromSpace或ToSpace之間複製。新生代採用空閒指標的方式來控制GC觸發,指標保持最後一個分配的物件在新生代區間的位置,當有新的物件要分配記憶體時,用於檢查空間是否足夠,不夠就觸發GC。當連續分配物件時,物件會逐漸從Eden到Survivor,最後到老年代。 -
老年代的GC(
Major GC/Full GC)
老年代與新生代不同,老年代物件存活的時間比較長、比較穩定,因此採用標記(Mark)演算法來進行回收,所謂標記就是掃描出存活的物件,然後再進行回收未被標記的物件,回收後對用空出的空間要麼進行合併、要麼標記出來便於下次進行分配,總之目的就是要減少記憶體碎片帶來的效率損耗。
3. 垃圾收集演算法
這裡只介紹幾種演算法的思想,不涉及具體的演算法實現。
3.1 標記-清除演算法
標記-清除演算法分為“標記”和“清除”兩個階段:首先標記出所有需要回收的物件,在標記完成後統一回收所有被標記的物件。
標記-清除演算法是最基礎的收集演算法,其他的收集演算法都是基於這種思路並對其不足進行改進而得到的。
-
標記-清除演算法的不足
一個是效率問題,標記和清除兩個過程的效率都不高;另一個是空間問題,標記清除之後會產生大量不連續的記憶體碎片,空間碎片太多可能會導致以後在程式執行過程中需要分配較大物件時,無法找到足夠的連續記憶體而不得不提前觸發另一次垃圾收集動作。
標記-清除演算法執行過程如下圖所示:

標記-清除演算法.png
3.2 複製演算法
將可用記憶體按容量劃分為大小相等的兩塊,每次只使用其中的一塊。當這一塊的記憶體用完了,就將還存活著的物件複製到另外一塊上面,然後再把已使用過的記憶體空間一次清理掉。
這樣使得每次都是對整個半區進行記憶體回收,記憶體分配時也就不用考慮記憶體碎片等複雜情況,只要移動堆頂指標,按順序分配記憶體即可,實現簡單,執行高效。
只是這種演算法的代價是將記憶體縮小為了原來的一半,未免太高了一點。
複雜演算法的執行過程如下:
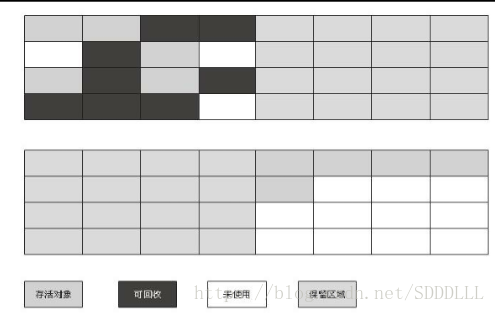
複製演算法.png
新生代的回收都是基於複製演算法來實現,只是會進行優化,具體可以看下前面 新生代的GC 這一塊的內容。
3.3 標記-整理演算法
標記過程仍然與“標記-清除”演算法一樣,但後續步驟不是直接對可回收物件進行清理,而是讓所有存活的物件都向一端移動,然後直接清理掉端邊界以外的記憶體。如下圖所示:

標記-整理演算法.png
3.4 分代收集演算法
目前商業虛擬機器的垃圾收集都採用“分代收集”(Generational Collection)演算法,根據物件存活週期的不同將記憶體劃分為幾塊。
把Java堆分為新生代和老年代,這樣就可以根據各個年代的特點採用最適當的收集演算法。
在新生代中,每次垃圾收集時都發現有大批物件死去,只有少量存活,那就選用複製演算法,只需要付出少量存活物件的複製成本就可以完成收集。
而老年代中因為物件存活率高、沒有額外空間對它進行分配擔保,就必須使用“標記—清理”或者“標記—整理”演算法來進行回收。