
從零開始製作人臉表情的資料集
一、背景
人臉表情識別網上已有很多教程,大多基於fer2013資料集展開的。現在的問題就在於fer2013資料集的數量太少,表情的區分度不夠明顯,大部分基於此資料集的模型,其識別精度僅有70%左右。
因此我想自己從零開始製作人臉表情,而且是非常誇張,有趣的人臉表情,用於後續的表情識別實驗。這一篇僅僅介紹如何在沒有任何資料的情況下,從零開始製作人臉表情資料集。
二、資料獲取
首先沒有任何資料的情況下,該如何開始資料的獲取呢?其實就兩種思路:一種是自己採集,例如用攝像頭抓幀,另一種是爬蟲爬取資料。實驗採用爬蟲爬取百度圖片中的資料。
然後自己設計自己需要的表情,我自己設定了10類。這裡以“吃驚”表情為例,在百度圖片搜尋中可以看到:
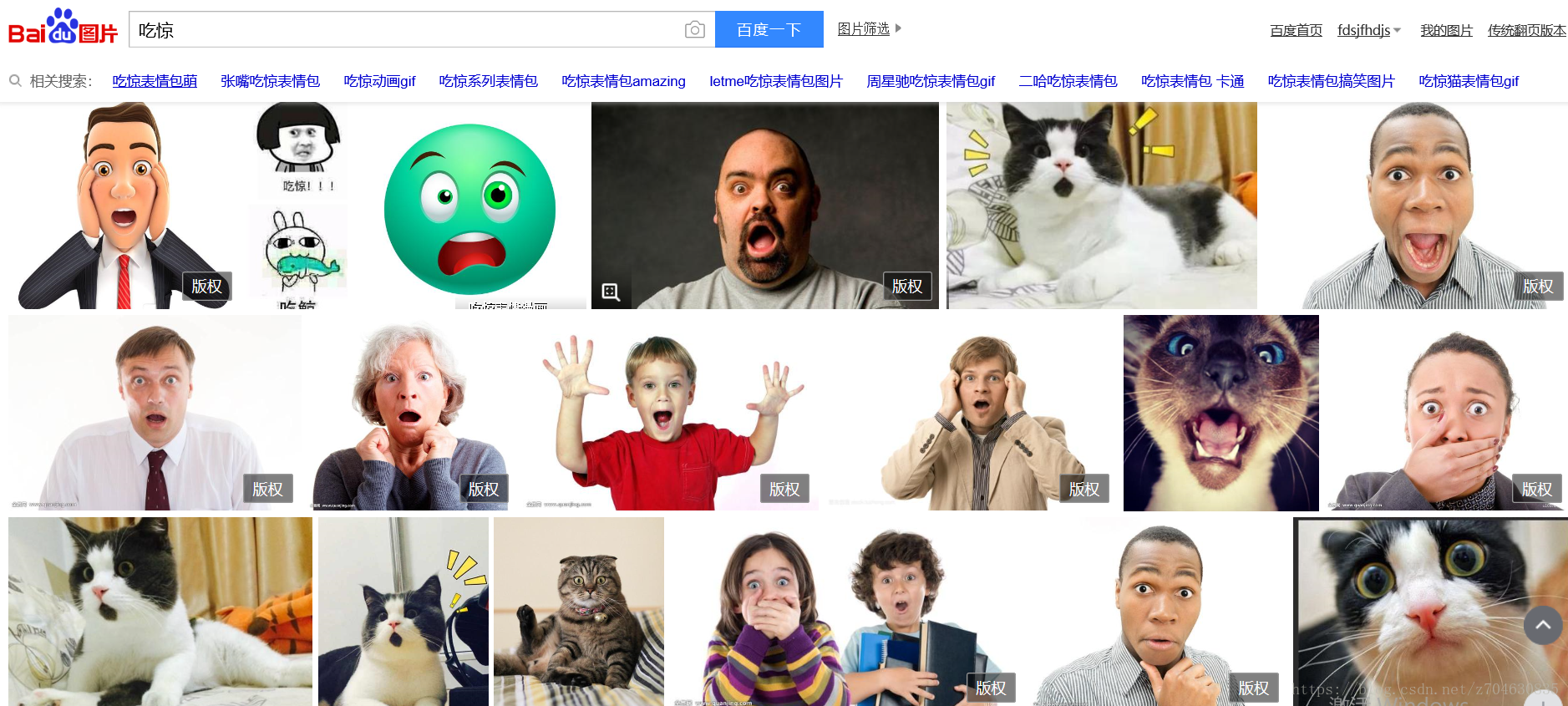
有一部分人臉資料,當然還有很多非人臉資料,這裡我們先不管那麼多,直接全部爬取下來,爬取的程式採用:
# 匯入需要的庫 import requests import os import json # 爬取百度圖片,解析頁面的函式 def getManyPages(keyword, pages): ''' 引數keyword:要下載的影像關鍵詞 引數pages:需要下載的頁面數 ''' params = [] for i in range(30, 30 * pages + 30, 30): params.append({ 'tn': 'resultjson_com', 'ipn': 'rj', 'ct': 201326592, 'is': '', 'fp': 'result', 'queryWord': keyword, 'cl': 2, 'lm': -1, 'ie': 'utf-8', 'oe': 'utf-8', 'adpicid': '', 'st': -1, 'z': '', 'ic': 0, 'word': keyword, 's': '', 'se': '', 'tab': '', 'width': '', 'height': '', 'face': 0, 'istype': 2, 'qc': '', 'nc': 1, 'fr': '', 'pn': i, 'rn': 30, 'gsm': '1e', '1488942260214': '' }) url = 'https://image.baidu.com/search/acjson' urls = [] for i in params: try: urls.append(requests.get(url, params=i).json().get('data')) except json.decoder.JSONDecodeError: print("解析出錯") return urls # 下載圖片並儲存 def getImg(dataList, localPath): ''' 引數datallist:下載圖片的地址集 引數localPath:儲存下載圖片的路徑 ''' if not os.path.exists(localPath): # 判斷是否存在儲存路徑,如果不存在就建立 os.mkdir(localPath) x = 0 for list in dataList: for i in list: if i.get('thumbURL') != None: print('正在下載:%s' % i.get('thumbURL')) ir = requests.get(i.get('thumbURL')) open(localPath + '%d.jpg' % x, 'wb').write(ir.content) x += 1 else: print('圖片連結不存在') # 根據關鍵詞來下載圖片 if __name__ == '__main__': dataList = getManyPages('吃驚', 20) # 引數1:關鍵字,引數2:要下載的頁數 getImg(dataList, './data/chijing/') # 引數2:指定儲存的路徑
之前我用這段程式爬取過皮卡丘影象,因此不再多做介紹,詳細可以參見:對抗神經網路學習(四)——WGAN+爬蟲生成皮卡丘影象(tensorflow實現)。這裡爬取好的影象直接儲存在根目錄下的'./data/chijing/'資料夾中。
同樣的思路,可以爬取其餘9種表情。
三、人臉裁剪及預處理
爬取完人臉表情之後,我們需要裁剪處影象中的人臉,這裡設定裁剪大小為128*128。裁剪過程需要用到opencv的人臉識別工具,即haarcascade_frontalface_alt.xml,關於該檔案,可從opencv庫的根目錄中查詢,具體查詢方法可以參見我之前的文章:深度學習(一)——deepNN模型實現攝像頭實時識別人臉表情(C++和python3.6混合程式設計)
import os
import cv2
# 讀取影象,然後將人臉識別並裁剪出來, 參考https://blog.csdn.net/wangkun1340378/article/details/72457975
def clip_image(input_dir, floder, output_dir):
images = os.listdir(input_dir + floder)
for imagename in images:
imagepath = os.path.join(input_dir + floder, imagename)
img = cv2.imread(imagepath)
path = "haarcascade_frontalface_alt.xml"
hc = cv2.CascadeClassifier(path)
faces = hc.detectMultiScale(img)
i = 1
image_save_name = output_dir + floder + imagename
for face in faces:
imgROI = img[face[1]:face[1] + face[3], face[0]:face[0] + face[2]]
imgROI = cv2.resize(imgROI, (128, 128), interpolation=cv2.INTER_AREA)
cv2.imwrite(image_save_name, imgROI)
i = i + 1
print("the {}th image has been processed".format(i))
def main():
input_dir = "data/"
floder = "chijing/"
output_dir = "output/"
if not os.path.exists(output_dir + floder):
os.makedirs(output_dir + floder)
clip_image(input_dir, floder, output_dir)
if __name__ == '__main__':
main()
如果要將該方法用於其餘9種表情,只需自己修改main函式中的相關路徑即可。這樣裁剪之後的影像中,難免混有一些非人臉影象,只需手動刪除即可。這樣處理之後的效果為:

四、資料增廣
經過以上三步,基本可以得到人臉資料集了,但是有的表情的資料量很少,進行模型訓練的時候必然會因為資料不足帶來影響,因此還需要進行資料增廣處理。
一般地,資料增廣處理的方法包括:旋轉,映象,隨機裁剪,噪聲,變形,顏色變化,對比度拉伸等方法。對於人臉來說,這裡所選擇的處理方法僅有:映象,即左右反轉;隨機裁剪,將128*128影響隨機裁剪為120*120,再將其resize成128*128;噪聲,新增少量的隨機噪聲。考慮到人臉資料集的特殊性,其他方法暫時沒有選擇。
這裡直接給出資料增廣的程式碼:
# 參考https://blog.csdn.net/qq_36219202/article/details/78339459
import os
from PIL import Image,ImageEnhance
import skimage
import random
import numpy as np
import cv2
# 隨機映象
def random_mirror(root_path, img_name):
img = Image.open(os.path.join(root_path, img_name))
filp_img = img.transpose(Image.FLIP_LEFT_RIGHT)
filp_img = np.asarray(filp_img, dtype="float32")
return filp_img
# 隨機平移
def random_move(root_path, img_name, off):
img = Image.open(os.path.join(root_path, img_name))
offset = img.offset(off, 0)
offset = np.asarray(offset, dtype="float32")
return offset
# # 隨機轉換
# def random_transform( image, rotation_range, zoom_range, shift_range, random_flip ):
# h,w = image.shape[0:2]
# rotation = numpy.random.uniform( -rotation_range, rotation_range )
# scale = numpy.random.uniform( 1 - zoom_range, 1 + zoom_range )
# tx = numpy.random.uniform( -shift_range, shift_range ) * w
# ty = numpy.random.uniform( -shift_range, shift_range ) * h
# mat = cv2.getRotationMatrix2D( (w//2,h//2), rotation, scale )
# mat[:,2] += (tx,ty)
# result = cv2.warpAffine( image, mat, (w,h), borderMode=cv2.BORDER_REPLICATE )
# if numpy.random.random() < random_flip:
# result = result[:,::-1]
# return result
# # 隨機變形
# def random_warp( image ):
# assert image.shape == (256,256,3)
# range_ = numpy.linspace( 128-80, 128+80, 5 )
# mapx = numpy.broadcast_to( range_, (5,5) )
# mapy = mapx.T
#
# mapx = mapx + numpy.random.normal( size=(5,5), scale=5 )
# mapy = mapy + numpy.random.normal( size=(5,5), scale=5 )
#
# interp_mapx = cv2.resize( mapx, (80,80) )[8:72,8:72].astype('float32')
# interp_mapy = cv2.resize( mapy, (80,80) )[8:72,8:72].astype('float32')
#
# warped_image = cv2.remap( image, interp_mapx, interp_mapy, cv2.INTER_LINEAR )
#
# src_points = numpy.stack( [ mapx.ravel(), mapy.ravel() ], axis=-1 )
# dst_points = numpy.mgrid[0:65:16,0:65:16].T.reshape(-1,2)
# mat = umeyama( src_points, dst_points, True )[0:2]
#
# target_image = cv2.warpAffine( image, mat, (64,64) )
#
# return warped_image, target_image
# 隨機旋轉
def random_rotate(root_path, img_name):
img = Image.open(os.path.join(root_path, img_name))
rotation_img = img.rotate(180)
rotation_img = np.asarray(rotation_img, dtype="float32")
return rotation_img
# 隨機裁剪
def random_clip(root_path, floder, imagename):
# 可以使用crop_img = tf.random_crop(img,[280,280,3])
img = cv2.imread(root_path + floder + imagename)
count = 1 # 隨機裁剪的數量
while 1:
y = random.randint(1, 8)
x = random.randint(1, 8)
cropImg = img[(y):(y + 120), (x):(x + 120)]
image_save_name = root_path + floder + 'clip' + str(count) + imagename
# BGR2RGB
# cropImg = cv2.cvtColor(cropImg, cv2.COLOR_BGR2RGB)
cropImg = cv2.resize(cropImg, (128, 128))
cv2.imwrite(image_save_name, cropImg)
count += 1
print(count)
if count > 3:
break
# 隨機噪聲
def random_noise(root_path, img_name):
image = Image.open(os.path.join(root_path, img_name))
im = np.array(image)
means = 0
sigma = 10
r = im[:, :, 0].flatten()
g = im[:, :, 1].flatten()
b = im[:, :, 2].flatten()
# 計算新的畫素值
for i in range(im.shape[0] * im.shape[1]):
pr = int(r[i]) + random.gauss(means, sigma)
pg = int(g[i]) + random.gauss(means, sigma)
pb = int(b[i]) + random.gauss(means, sigma)
if (pr < 0):
pr = 0
if (pr > 255):
pr = 255
if (pg < 0):
pg = 0
if (pg > 255):
pg = 255
if (pb < 0):
pb = 0
if (pb > 255):
pb = 255
r[i] = pr
g[i] = pg
b[i] = pb
im[:, :, 0] = r.reshape([im.shape[0], im.shape[1]])
im[:, :, 1] = g.reshape([im.shape[0], im.shape[1]])
im[:, :, 2] = b.reshape([im.shape[0], im.shape[1]])
gaussian_image = Image.fromarray(np.uint8(im))
return gaussian_image
# 隨機調整對比度
def random_adj(root_path, img_name):
image = skimage.io.imread(os.path.join(root_path, img_name))
gam = skimage.exposure.adjust_gamma(image, 0.5)
log = skimage.exposure.adjust_log(image)
gam = np.asarray(gam, dtype="float32")
log = np.asarray(log, dtype="float32")
return gam, log
# 執行
def main():
root_dir = "output/"
floder = "chijing/"
images = os.listdir(root_dir + floder)
for imagename in images:
mirror_img = random_mirror(root_dir + floder, imagename)
image_save_name = root_dir + floder + "mirror" + imagename
mirror_img = cv2.cvtColor(mirror_img, cv2.COLOR_BGR2RGB)
cv2.imwrite(image_save_name, mirror_img)
random_clip(root_dir, floder, imagename)
noise_img = random_noise(root_dir + floder, imagename)
noise_img = np.asarray(noise_img, dtype="float32")
image_save_name = root_dir + floder + "noise" + imagename
noise_img = cv2.cvtColor(noise_img, cv2.COLOR_BGR2RGB)
cv2.imwrite(image_save_name, noise_img)
print("image preprocessing")
if __name__ == '__main__':
main()很多處理方法都是參考網上的程式碼,只不過我將這些方法整合到了一起。對於其餘9種表情,需要設定的僅僅只是main函式種的路徑引數。
隨機裁剪3張、映象1張、隨機噪聲1張的處理結果如下:

最終的“吃驚”表情處理結果:

整個處理之後的資料量還是非常可觀的,當然了,如果自己覺得資料量還不夠,還可以再進行進一步處理,例如對映象影象進行隨機裁剪,不同程度的噪聲影像,以及對比度拉伸等方法。
以上僅僅是一種表情的資料集製作,同理製作其餘的表情資料集即可。準備好了資料集之後,即可開始進行模型的訓練了~