
大資料概論 作業2
作業2 2220172205 10.18
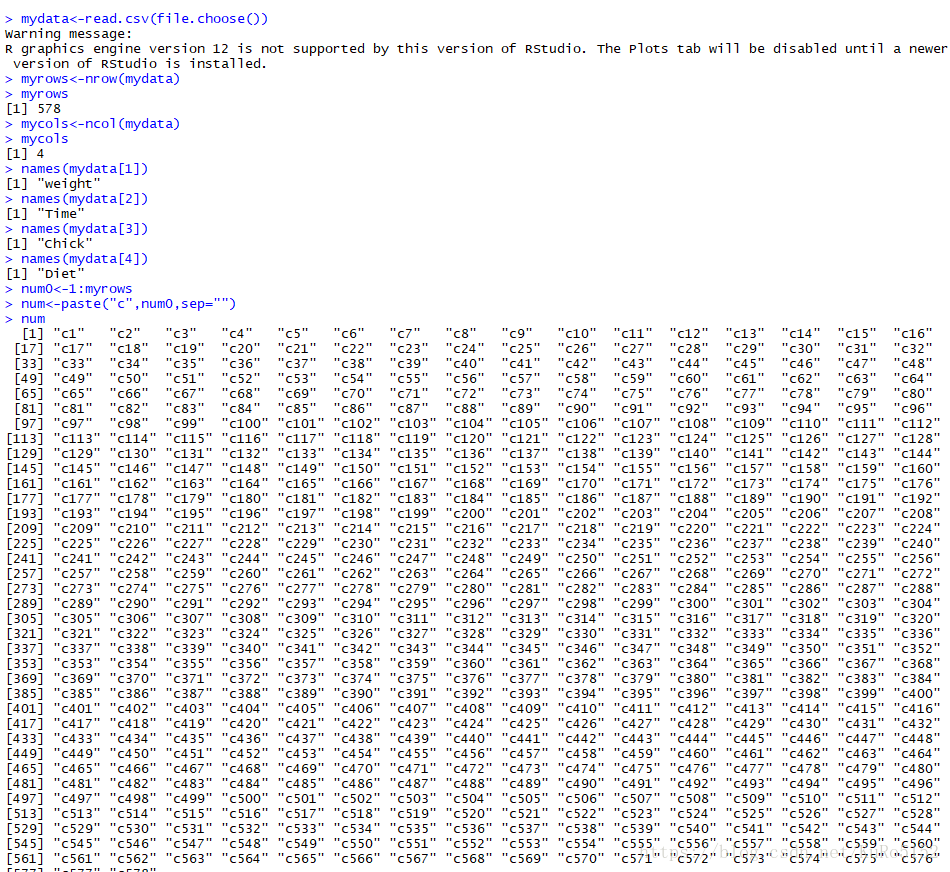
1.開啟R studio 用mydata<-read.csv(file.choose())選擇檔案forclass.csv
2.用myrows<-nrow(mydata) 記錄資料行數,用mycols<-ncol(mydata) 記錄資料列數
3.用names(mydata[n]) 讀取第n列的列名
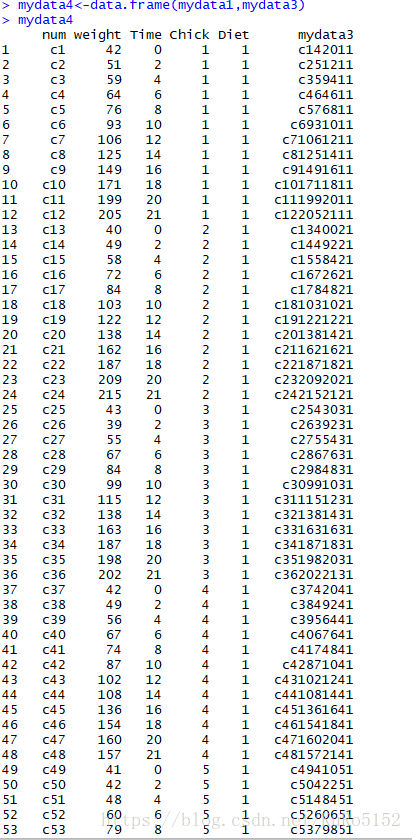
4.建立編號 num0<-1:myrows ,用num<-paste(“c”,num0,sep="") 將編號與字元c組合成c1~~cn,並加入sep="“使其中間預設空格符消去,再用mydata1<-data.frame(num,mydata)將編號放置在資料左側。
5.用mydata2<-as.character(mydata1) 把所有數值變成字元,再用mydata3<-paste(mydata2[,1],mydata2[,2],mydata2[,3],mydata2[,4],mydata2[,5],sep=”"),之後用mydata4<-data.frame(mydata1,mydata3) 得到最終資料。
6.關於增加一行用rbind出現NA的問題,資料解釋是由於變數中含有factor型別的變數,需現將變數改為character型別即可。
相關推薦
大資料概論 作業2
作業2 2220172205 10.18 1.開啟R studio 用mydata<-read.csv(file.choose())選擇檔案forclass.csv 2.用myrows<-nrow(mydata) 記錄資料行數,用mycols<-ncol(mydata) 記
hadoop 大資料實戰(2)mongodb安裝
mongodb-win32-x86_64-2008plus-ssl-4.0.3.zip 1、下載地址: https://www.mongodb.com/download-center 2、配置 1.建立路徑,C:\mongodb 2.在C:\mongodb下減壓下載的zip檔案,然後在C
大資料入門(2)安裝linux的jdk
1、上傳檔案到linux alt+p 進入ftp傳檔案 sftp> put E:\soft\jdk-7u71-linux-x64.tar.gz 2、建立資料夾解壓檔案(root使用者許可權) mkdir /usr/java tar -zxvf jdk-7u71-
大資料之(2)修改Hadoop叢集日誌目錄,資料存放目錄
Hadoop有時會有unhealthy Node不健康的非Active節點存產生,具體錯誤內容如下。 一、錯誤內容 -== log-dirs usable space is below configured utilization percentage/no more usabl
【大資料技術】2.協調服務zookeeper
本文主要按以下六個部分進行描述:一、概念與作用 二、資料模型與特徵 三、角色 四、工作原理 五、選舉機制 六、zookeeper實戰操作(shell命令與API) 一、概念與作用 zookeeper主要是為分散式應用提供一致性服務 主要提供:維護配置資訊、名字服務、分散式同步、組服務 其結構
資料結構作業2
const int MaxSize=100; template class SeqList { public: SeqList(); SeqList(T a[],int n); ~SeqList(); int Length(){return length;} T Get(int i); in
Hadoop系列001-大資料概論
本人微信公眾號,歡迎掃碼關注! 大資料概論 1、大資料概念 大資料(big data),指無法在一定時間範圍內用常規軟體工具進行捕捉、管理和處理的資料集合,是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的資訊資產。
大資料基礎Hadoop 2.x入門
hadoop概述 儲存和分析網路資料 三大元件 MapReduce 對海量資料的處理 思想: 分而治之 每個資料集進行邏輯業務處理map 合併統計資料結果reduce
大資料學習第2天----------------linux 安裝mysql 出現安裝依賴問題解決(centos7)
問題:安裝mysql過程中出現的依賴 [[email protected] mysql-5.7.16]# rpm -ivh mysql-community-devel-5.7.16-1.el7.x86_64.rpm warning: mysql-community
大資料 hadoop2.5.2偽分散式搭建
1.準備Linux環境 1.0點選VMware快捷方式,右鍵開啟檔案所在位置 -> 雙擊vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip 設定網段:192.168.8.0 子網掩碼:255.255.255.0 -> apply -&g
大資料 學習旅途2——tar的解壓方式
1、解壓方法 壓縮 tar –cvf jpg.tar *.jpg //將目錄裡所有jpg檔案打包成tar.jpg tar –czf jpg.tar.gz *.jpg //將目錄裡所有jpg檔案打包成jpg.tar後,並且將其用gzip壓縮,生成一個gzip壓縮過
大資料系列3-第一章-大資料概論
1.大資料概論 行動硬碟-tb級別 資料分析的場景: 金融行業-資訊密集;;股票市場預測;;小額貸款;;支付寶信用:給使用者打標籤,銀行貸款;; 網際網路需求更大(更多的是一個媒體):精準營銷,流量運營,通過流量做營收,流量變現,ctr預測,;; 電信-移動網際網路
spark快速大資料分析(2)
spark下載與入門spark shell其他shell工具只能使用單機的硬碟和記憶體來操作資料,而spark shell可以用來與分散式儲存在許多機器的記憶體或者硬碟上的資料進行互動,並且處理過程的分發由spark自動控制完成。spark支援許多語言版本,此處互動式shel
[大資料學習研究]2.利用VirtualBox模擬Linux叢集
1. 在主機Macbook上設定HOST 前文書已經把虛擬機器的靜態IP地址設定好,以後可以通過ip地址登入了。不過為了方便,還是設定一下,首先在Mac下修改hosts檔案,這樣在ssh時就不用輸入ip地址了。 sudo vim /etc/hosts 或者 sudo v
大資料學習-scala作業(2)
package com.jn.spark.lesson1 import scala.collection.mutable.ArrayBuffer /** * 作業1:移除一個數組中第一個負數後的所有負數,(第一個負數要保留,其餘的負數都刪除) * @author 江
福大軟工1816 · 第五次作業 - 結對作業2
同名 [] 分享 and rds 規範 fir 分鐘 begin 一、結對同學的博客鏈接、本作業博客的鏈接、Fork的同名倉庫的Github項目地址 結對同學的博客鏈接,本作業博客鏈接,github項目地址 二、具體分工: 基本功能部分:鄭孔宇 測試及附加題部分:俞凱欣 三
Atittit HDFS hadoop 大資料檔案系統java使用總結 目錄 1. 作業系統,進行操作 1 2. Hdfs 類似nfs ftp遠端分散式檔案服務 2 3. 啟動hdfs服務start
Atittit HDFS hadoop 大資料檔案系統java使用總結 目錄 1. 作業系統,進行操作 1 2. Hdfs 類似nfs ftp遠端分散式檔案服務 2 3. 啟動hdfs服務start-dfs.cmd 2 3.1. 配置core-site
[大資料]Scala 速學手冊2
Scala 速學手冊2 1 類、物件、繼承、特質 1.1 類 1 類的定義 //在Scala中,類並不用宣告為public。 //Scala原始檔中可以包含多個類,所有這些類都具有公有可見性。 class Person { //用val修飾的變數是隻讀屬性,有gett
大資料基礎概論
一、大資料概念 1.大資料的定義: 指無法在一定時間範圍內用常規軟體工具進行捕捉、管理和處理的資料集合,是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的資訊資產。補充:主要解決,海量資料的儲存和海量資料的分析計算問題。 2.資料的單位:
大資料之Spark(一)--- Spark簡介,模組,安裝,使用,一句話實現WorldCount,API,scala程式設計,提交作業到spark叢集,指令碼分析
一、Spark簡介 ---------------------------------------------------------- 1.快如閃電的叢集計算 2.大規模快速通用的計算引擎 3.速度: 比hadoop 100x,磁碟計算快10x 4.使用: java