大資料Hadoop學習筆記(四)
阿新 • • 發佈:2018-11-09
MapReduce執行過程
========
- step1 :
- input
- InputFormat
- 讀取資料
- 轉換成<key, value>
- FileInputFormat
- TextInputFormat
- InputFormat
- input
- step 2:
- map
- ModuleMapper
- map(KEYIN , VALUEIN, KEYOUT, VALUEOUT)
- 預設情況下——>KEYIN :LongWritable VALUEIN : TEXT
- map
- step 3:
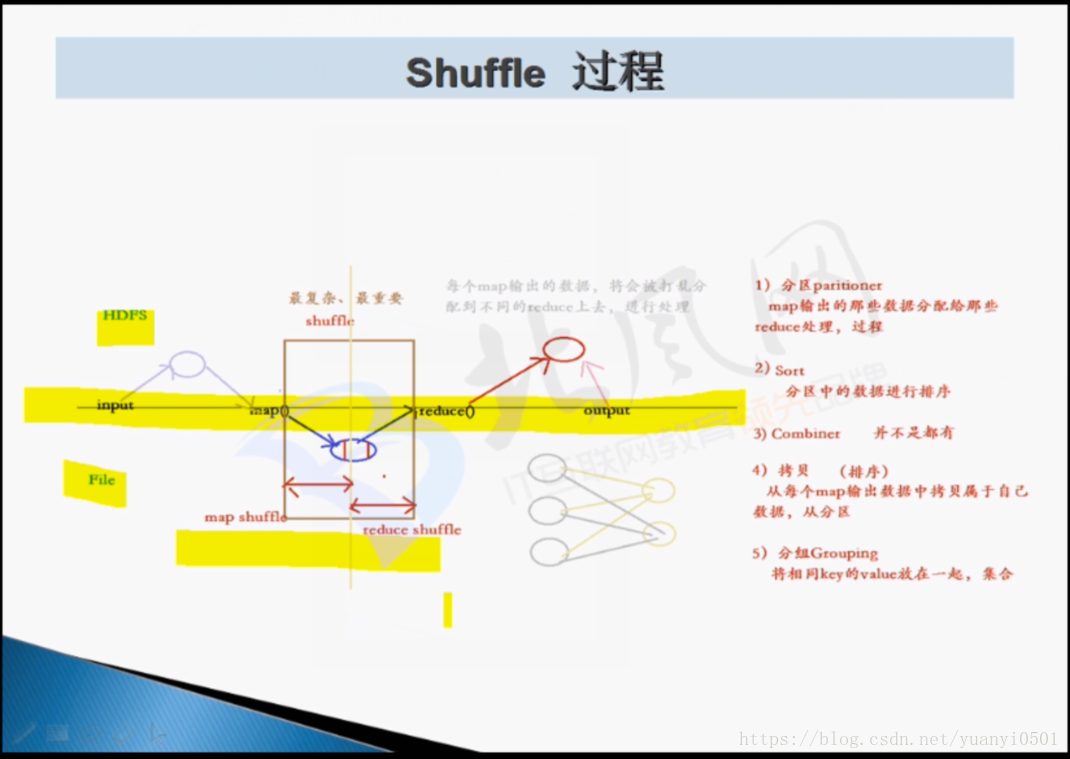
- shuffle
- proceess
- map,output<key, value>
- 輸出output一開始放在memory記憶體緩衝區
- 記憶體滿了之後通過spill,溢寫到磁碟中,很多檔案。寫的過程中有兩種操作:
- 分割槽parttition,基於hash分割槽
- 排序sort
- 輸出之後,磁碟存在很多小檔案
- 將小檔案合併merge
- 排序
- 形成一個大檔案——》在map task執行的機器的本地磁碟
-------------------------------- map結束 ---------------------------------------------
- reduce任務啟動,會到map task執行的機器的本地磁碟上,拷貝要處理的資料
- 合併。排序
- 分組group:將相同的key的value放在一起
-MAP-01
<hadoop,1>
——————<hadoop,2>------->combiner在map端合併key
<hadoop,1>
<yarn,1>
<hive,1>
-MAP-02
-MAP-03
-reduce-01
a-zA-Z
- reduce-02
other
總結shuffle過程:
- 分割槽partition
- 排序sort
- 拷貝copy——使用者無法干預
- 分組group
- 壓縮compress——可設定
- 合併 combiner map任務端的reduce——可設定
- step 4:
- reduce:
- reduce(KEYIN, VALUEIN,KEYOUT,VALUEOUT)
- map輸出的<key, value>資料型別與reduce輸入的<key, value>資料型別一致
- reduce:
- step 5:
- output
- OutPutFormat
- FileOutputFormat
- TextOutputFormat
- 每個<key, value>對,輸出一行,key和value之間用\t分隔,預設呼叫key和value的toString()方法
- TextOutputFormat
- output
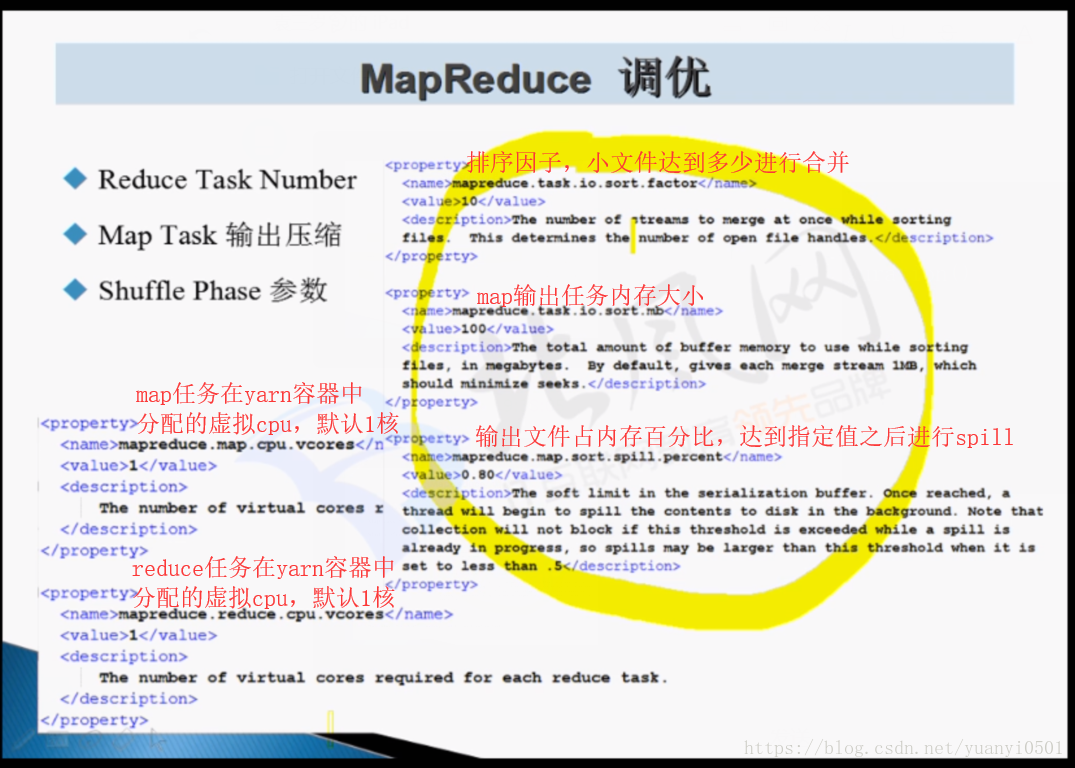
MapReduce調優
- reduce task 數量。設定的兩種方法:
- mapreduce.job.reduces
- job.setNumReduceTasks(1);
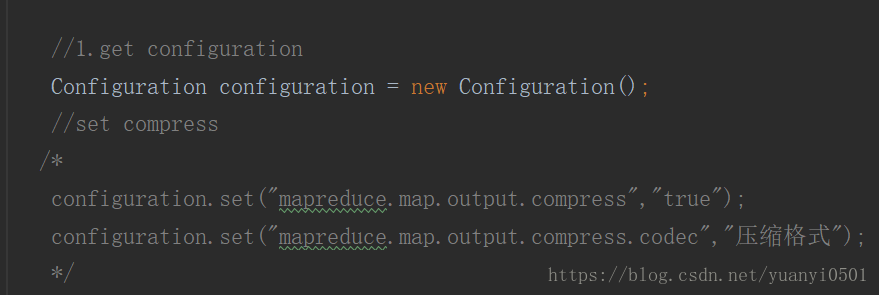
- map task 輸出壓縮
- shuffle 引數